点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
点击进入—> CV 微信技术交流群
【导读】一篇论文带你读完「连续分片线性函数」的发展。
连续分片线性函数是一类具备局部线性特性和全局非线性特性的连续函数。具有特定表示模型的连续分片线性函数能够对紧集上的任意连续函数进行全局逼近。
其本质是利用有限数量的线性函数对复杂的非线性系统进行精确建模,即在保持局部线性特性的同时,使整体建模表现出非线性特性。
分片线性神经网络(PieceWise Linear Neural Networks,PWLNN)是利用连续分片线性函数对非线性系统建模的主要方法之一。
当合理配置神经网络网络结构及神经元中的激活函数(如ReLU等分片线性映射函数),可以得到一类PWLNN,并以此为基础,灵活利用常见的神经网络模型参数优化算法和各类成熟的计算平台,实现对复杂非线性系统或数据集进行黑箱建模。
在过去的几十年里,PWLNN已经从浅层架构发展到深层架构,并在不同领域取得了广泛的应用成果,包括电路分析、动态系统识别、数学规划等。近年来,深度PWLNN在大规模数据处理方面取得的巨大成功尤为瞩目。

图1 二维连续分片线性函数示例[2]
最近由清华大学自动化系、比利时荷语鲁汶大学电子系、上海交通大学自动化系以及之江实验室的研究人员共同完成的一篇发表在《自然-综述》系列期刊上的综述论文,系统地介绍了分片线性神经网络表示模型(包括浅层及深度网络)、优化算法、理论分析以及应用。

论文链接:https://www.nature.com/articles/s43586-022-00125-7
清华大学自动化系李力教授及王书宁教授指导的博士毕业生陶清华(现任比利时荷语鲁汶大学博士后)、黄晓霖(现任上海交通大学副教授)为论文的通讯作者,其中陶清华博士为论文第一作者,其他共同作者包括王书宁教授、比利时荷语鲁汶大学Johan A.K. Suykens教授及王书宁教授指导的博士毕业生袭向明(现任之江实验室助理研究员)。
清华大学自动化系王书宁教授团队近二十年来在分片线性神经网络方向开展了系统的研究,取得了一些重要成果,显著推进了该领域的发展。
目前,团队成员遍布于国内外的研究机构,继续从事分片线性神经网络及其相关科研工作,共同促进相关理论的发展和成果转化。
Nature Reviews Methods Primers于2021年1月创刊,致力于加强跨学科的协作,出版多领域前沿方法或技术的综述文章,旨在为处于不同职业阶段或具有不同研究背景/不同知识储备的跨学科研究者和实践者提供了解、评估和应用前沿方法和技术的信息交流平台。
为了将PWLNN更好地应用于数据科学,学者们长期以来一直围绕两个基本问题展开研究,即表示模型及其参数学习算法,其中前者旨在建立具备分片线性特性和充分的逼近能力的数学模型[2-11],后者则研究适应大规模数据的表示模型参数准确而快速的学习算法[9-22],从而使PWLNN能够准确描述给定数据或待研究系统对象的特性。 图3. 模型部分概况[1]1977年,著名电路系统专家蔡少棠(Leon O. Chua)等在电路系统分析中首次成功提出了紧凑的PWLNN表示法,即典范表示模型[3]。1993年,著名统计和机器学习专家Leo Breiman开创了另一类基于铰链的模型表示,即链接超平面模型[4],其与当今深度神经网络中最流行的激活函数之一,即线性整流单元(Rectified Linear Units, ReLU),极为类似。随后王书宁教授将其推广至具有全局表示能力的广义链接超平面模型[8]。随着典范表示模型和链接超平面模型的提出,PWLNN相关研究也得到快速发展,其中大部分工作围绕浅层网络结构和参数学习方法而展开。2010年,Nair和Hinton提出的ReLU21大幅度提高了深度学习在各种基于数据驱动的任务中的效果,使得具有深层网络结构的PWLNN得到更加广泛的关注。
图3. 模型部分概况[1]1977年,著名电路系统专家蔡少棠(Leon O. Chua)等在电路系统分析中首次成功提出了紧凑的PWLNN表示法,即典范表示模型[3]。1993年,著名统计和机器学习专家Leo Breiman开创了另一类基于铰链的模型表示,即链接超平面模型[4],其与当今深度神经网络中最流行的激活函数之一,即线性整流单元(Rectified Linear Units, ReLU),极为类似。随后王书宁教授将其推广至具有全局表示能力的广义链接超平面模型[8]。随着典范表示模型和链接超平面模型的提出,PWLNN相关研究也得到快速发展,其中大部分工作围绕浅层网络结构和参数学习方法而展开。2010年,Nair和Hinton提出的ReLU21大幅度提高了深度学习在各种基于数据驱动的任务中的效果,使得具有深层网络结构的PWLNN得到更加广泛的关注。
如上图3所示,PWLNN可分为两大类,即浅层的PWLNN(如图3中下半部分左右两图所示)和深层的PWLNN(如图2中上半部分图)。浅层的PWLNN主要分为两大类,即基函数组合模型及格模型。其中前者通过对具有不同结构、参数和特性的基函数进行组合,如图4(a)(b)所示,实现能够满足不同场景的具有不同逼近能力、表示能力、参数及结构的辨识难易程度的PWLNN后者则通过显式枚举可行域的各个子区域所对应的线性表达,并利用min-max(或max-min)的嵌套形式,实现PWLNN的紧凑表示,如图4(c)所示。格模型中线性子区域的显式表达特性在一些特定应用场景下尤为重要,例如模型预测控制[25,31]。
图4. (a) 二维链接超平面模型基函数示意图; (b) 二维单纯形模型基函数示意图;(c) 一维格模型示例图 (含5个子区域线性表达式)对比而言,由于网络深度的限制,浅层的PWLNN通常通过筛选更为有效的神经元,而逐渐增加网络宽度的方式,提升模型灵活性,然而在反复搜索有效神经元的过程往往会牺牲算法效率,同时缺少对全局信息的考虑。与浅层PWLNN更加侧重于神经元连接方式的特点不同,深层的PWLNN更加侧重于在深度神经网络中引入形式简单的分片线性函数作为激活单元,从而是深层PWLNN整体表现为逐层嵌套的分片线性映射函数。深层的PWLNN更偏好于增加网络深度[23],这种方式的优势在于能够更加高效而灵活地实现分片线性子区域的划分,并使模型具有更好的灵活性,例如图5中的典型全连接深层PWLNN模型结构示意。
通过逐层的分片线性函数映射,定义域会被划分为更多的线性子区域,如图6所示。
图6中(b)、(c)、(d)为(a)所示网络中第一层隐含层、第二隐含层、第三隐含层中神经元输出对应的定义域划分,可见随着网络深度的嵌套网络定义域被划分成更多的子区域,即神经元输出由更多不同片线性子函数构成,因此可以得到更为灵活的PWLNN。
又例如图7中示例所示,随着网络层数的加深,定义域可被灵活的划分为众多具有线性特性的子区域,从而可以更为精确的地对数据进行拟合,实现强大的逼近能力。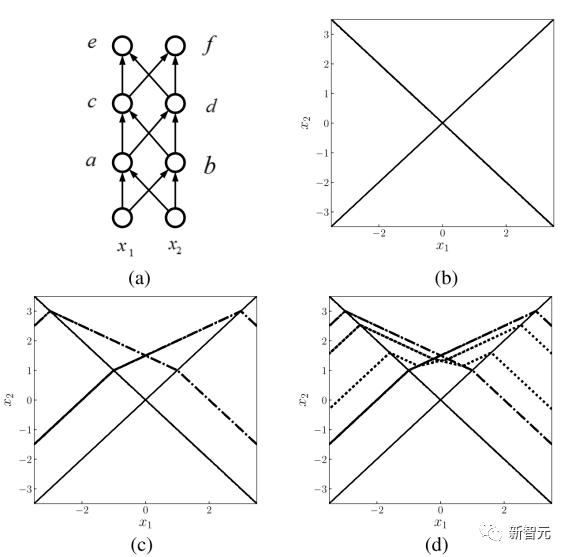
图6. 二维简单PWLNN(ReLU为激活函数)网络结构及其定义域划分示意图[32]
图7. 简单的深层PWLNN定义域划分示意图[33]对于更为一般的情况,与浅层PWLNN模型类似,深层PWLNN网络中神经元的连接方式也可多样化,例如全连接网络和卷积神经网络CNN,以及逐层连接和残差网络ResNet。进一步的,PWLNN中神经元间的非线性传递函数也可以为一般形式的连续分片线性函数,不仅限于一般的一维函数,例如ReLU及Leaky ReLU[34],也可以为多维的Maxout[26]等。图8示意了具有一般形式的PWLNN网络结构,适用于上述所有浅层和深层PWLNN模型。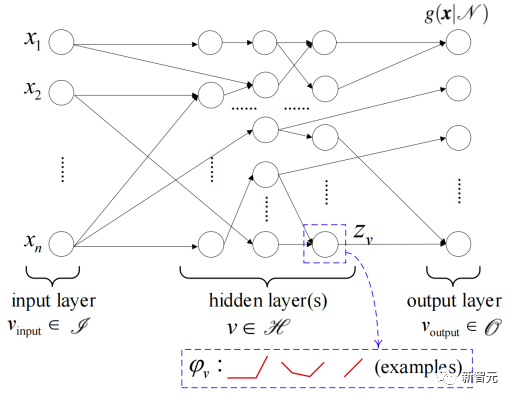
浅层的PWLNN的参数学习算法主要是增量式地逐步添加神经元和/或更新参数,其目标是学习到一个更宽的网络,以实现更好的学习效果。不同的浅层PWLNN模型通常有其特有的学习算法,充分考虑模型特有的几何特性及实际应用需求,例如图4(a)中对应的链接超平面模型对应找链接算法[13],及图4(b)中单纯形模型对应的基于单纯形找片的辨识算[2]等。以图9为例,通过逐步添加左侧所示的辨识得到的三个基函数,可得到右侧对应的PWLNN,实现对示例中正弦函数的逼近。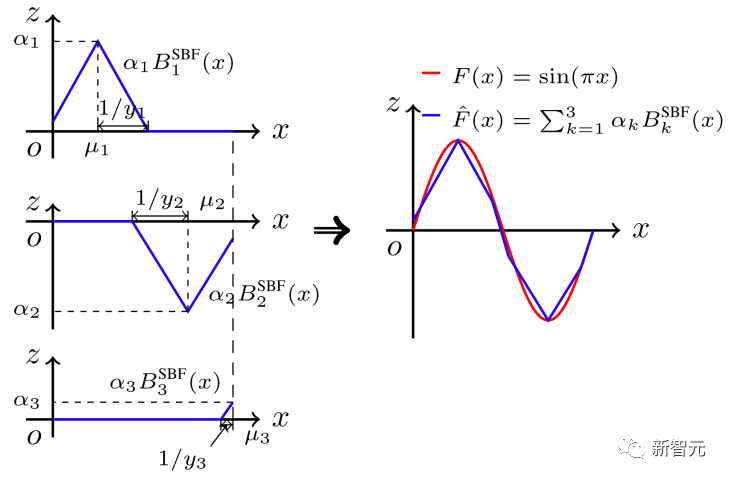
图9. 基于增量式学习的单纯形找片算法示意图[2]浅层的PWLNN广泛应用于函数逼近、系统辨识及预测控制等领域中的问题,但在处理高维问题、大规模数据及复杂任务时,这些模型的灵活性及算法效率仍具有局限性[5]。
相比较而言,深层的PWLNN的学习则延续了深度学习中一般深度网络的优化算法,即其通常具有预先确定的网络结构,并在基于梯度反向传播策略和随机梯度下降算法的学习框架下进,优化网络参数,这样实现了对优化过程的简化并提高了学习效率,从而使其可以求解复杂问题[16]。
值得一提的是,分片线性激活函数(如ReLU)的引入,能有效抑制梯度消失等影响深度学习应用效果的不利特性[22],因此PWLNN的发展也在一定程度上促进了深度学习的发展。
此外,在GPU/TPU等硬件和各类成熟的深度学习软件平台的支撑下,对计算能力具有较高需求的深层的PWLNN能够应用于更大规模的问题,使其在当今的大数据时代脱颖而出。
与其他非线性函数不同,分片线性函数具有一个重要性质,即其对定义域划分和子区域局部线性表达的可解释性。
除了强大的逼近能力,目前分片线性还被广泛的应用于深度学习中的各类理论分析中[24-30],例如通过利用线性子区域边界特性验证对于给定输出情况下网络输出预测的鲁棒性验证[28-29],以及利用估计线性子区域片数衡量网络灵活性[24]等。深层PWLNN的分片线性特性导致的复杂的子区域划分及模型表达式会阻碍分片线性函数的可解释能力和带来难易预测的行为特征。浅层的PWLNN的建模及学习算法通常会考虑定义域中各子区域的局部线性特征,并以实现足够稀疏的模型结构为参数学习目标。特别地,具有不同形式的浅层PWLNN对应了不同的参数学习算法,这些算法充分考虑了各模型特有的几何特征,从而实现较好的学习效果。例如,对应于链接超平面模型的找链接算法[13],对应于自适应链接超平面模型的基于定义域划分的树形结构算法[9]等。然而,深层的PWLNN通常忽略了模型的几何特征,而通过为各个神经节点配置形式简单的分片线性映射函数,并结合多层结构带来的非线性特性逐层叠加效应,以实现极其复杂的子区域划分和局部线性表达。尽管在各领域问题的求解过程中的数值结果证明了深层PWLNN的优越性能,但模型参数学习算法与模型结构相独立,一般采用深度学习的常用策略,即随机梯度下降算法,而忽略了分片线性特性对学习过程的影响。例如,如何为具有不同网络结构和神经元映射函数的PWLNN构建特有的学习算法,在保持参数稀疏性和模型可解释性的同时,提升学习过程的效率和效果;
对于给定数据集,是否能够以及如何找到一个具有最简单结构和模型可解释性的深层PWLNN;
这样的PWLNN应该通过显式的构建一个浅层PWLNN或隐式的的正则化一个深层PWLNN得以实现;
如何建立PWLNN与其他强调局部特征学习的深度神经网络之间的区别和关系等。综上,此综述对PWLNN方法论进行了的系统性回顾,从浅层网络和深层网络两个方面对表示模型、学习算法、基础理论及实际应用等方面内容进行了梳理,展现了浅层的PWLNN向当今广泛使用的深层的PWLNN的发展历程,全面剖析了二者之间的关联关系,并对现存问题和未来研究方向进行了深入讨论。
不同背景的读者可以很容易地了解到从PWLNN的开创性工作到当今深度学习中最先进的PWLNN的发展路线。同时,通过重新思考早期的经典工作,可将其与最新研究工作相互结合,以促进对深层PWLNN的更深入研究。综述文章阅读链接:https://rdcu.be/cPIGw综述文章下载链接https://www.nature.com/articles/s43586-022-00125-7arXiv版本下载链接 https://arxiv.org/abs/2206.09149编辑同期配发了PrimeView进行推介 https://www.nature.com/articles/s43586-022-00137-3[1] Tao, Q., Li, L., Huang, X. et al. Piecewise linear neural networks and deep learning. Nat Rev Methods Primers 2, 42 (2022). [2] Yu, J., Wang, S. & Li, L. Incremental design of simplex basis function model for dynamic system identification. IEEE Transactions on Neural Networks Learn. Syst. 29, 4758–4768 (2017). [3] Chua, L. O. & Deng, A. Canonical piecewise-linear representation. IEEE Trans. Circuits Syst. 35, 101–111 (1988). This paper presents a systematic analysis of Canonical Piecewise Linear Representations, including some crucial properties of PWLNNs. [4] Breiman, L. Hinging hyperplanes for regression, classification, and function approximation. IEEE Trans. Inf. Theory 39, 999–1013 (1993). This paper introduces the hinging hyperplanes representation model and its hinge-finding learning algorithm. The connection with ReLU in PWL-DNNs can be referred to. [5] Julián, P. A High Level Canonical Piecewise Linear Representation: Theory and Applications. Ph.D. thesis, Universidad Nacional del Sur (Argentina) (1999). This dissertation gives a very good view on the PWL functions and their applications mainly in circuit systems developed before the 2000s. [6] Tarela, J. & Martínez, M. Region configurations for realizability of lattice piecewise-linear models. Math. Computer Model. 30, 17–27 (1999). This work presents formal proofs on the universal representation ability of the lattice representation and summarizes different locally linear subregion realizations. [7] Wang, S. General constructive representations for continuous piecewise-linear functions. IEEE Trans. Circuits Syst. I Regul. Pap. 51, 1889–1896 (2004). This paper considers a general constructive method for representing an arbitrary PWL function, in which significant differences and connections between different representation models are vigorously discussed. Many theoretical analyses on deep PWLNNs adopt the theorems and lemmas proposed. [8] Wang, S. & Sun, X. Generalization of hinging hyperplanes. IEEE Trans. Inf. Theory 51, 4425–4431 (2005). This paper presents the idea of inserting multiple linear functions in the hinge, and formal proofs are given for the universal representation ability for continuous PWL functions. The connection with maxout in deep PWLNNs can be referred to. [9] Xu, J., Huang, X. & Wang, S. Adaptive hinging hyperplanes and its applications in dynamic system identification. Automatica 45, 2325–2332 (2009). [10] Tao, Q. et al. Learning with continuous piecewise linear decision trees. Expert. Syst. Appl. 168, 114–214 (2021). [11] Tao, Q. et al. Toward deep adaptive hinging hyperplanes. IEEE Transactions on Neural Networks and Learning Systems (IEEE, 2022). [12] Chien, M.-J. Piecewise-linear theory and computation of solutions of homeomorphic resistive networks. IEEE Trans. Circuits Syst. 24, 118–127 (1977) [13] Pucar, P. & Sjöberg, J. On the hinge-finding algorithm for hinging hyperplanes. IEEE Trans. Inf. Theory 44, 3310–3319 (1998). [14] Huang, X., Xu, J. & Wang, S. in Proc. American Control Conf. 4431–4936 (IEEE, 2010). This paper proposes a gradient descent learning algorithm for PWLNNs, where domain partitions and parameter optimizations are both elucidated. [15] Hush, D. & Horne, B. Efficient algorithms for function approximation with piecewise linear sigmoidal networks. IEEE Trans. Neural Netw. 9, 1129–1141 (1998). [16] LeCun, Y. et al. Gradient-based learning applied to document recognition. Proc. IEEE 86, 2278–2324 (1998). This work formally introduces the basic learning framework for generic deep learning including deep PWLNNs. [17] He, K., Zhang, X., Ren, S. & Sun, J. in Proc. IEEE Int. Conf. Computer Vision 1026–1034 (IEEE, 2015). This paper presents modifications of optimization strategies on the PWL-DNNs and a novel PWL activation function, where PWL-DNNs can be delved into fairly deep. [18] Tao, Q., Xu, J., Suykens, J. A. K. & Wang, S. in Proc. IEEE Conf. Decision and Control 1482–1487 (IEEE, 2018). [19] Wang, G., Giannakis, G. B. & Chen, J. Learning ReLU networks on linearly separable data: algorithm, optimality, and generalization. IEEE Trans. Signal. Process. 67, 2357–2370 (2019). [20] Tsay, C., Kronqvist, J., Thebelt, A. & Misener, R. Partition-based formulations for mixed-integer optimization of trained ReLU neural networks. Adv. Neural Inf. Process. Syst. 34, 2993–3003 (2021). [21] Nair, V. & Hinton, G. in Proc. Int. Conf. on Machine Learning (eds Fürnkranz, J. & Joachims, T.) 807–814 (2010). This paper initiates the prevalence and state-of-theart performance of PWL-DNNs, and establishes the most popular ReLU. [22] Glorot, X., Bordes, A. & Bengio, Y. Deep sparse rectifier neural networks. PMLR 15, 315–323 (2011). [23] Lin, J. N. & Unbehauen, R. Canonical piecewise-linear networks. IEEE Trans. Neural Netw. 6, 43–50 (1995). This work depicts network topology for Generalized Canonical Piecewise Linear Representations, and also discusses the idea of introducing general PWL activation functions for deep PWLNNs, yet without numerical evaluations. [24] Pascanu, R., Montufar, G. & Bengio, Y. in Adv. Neural Inf. Process. Syst. 2924–2932 (NIPS, 2014). This paper presents the novel perspective of measuring the capacity of deep PWLNNs, namely the number of linear sub-regions, where how to utilize the locally linear property is introduced with mathematical proofs and intuitive visualizations. [25] Bemporad, A., Borrelli, F. & Morari, M. Piecewise linear optimal controllers for hybrid systems. Proc. Am. Control. Conf. 2, 1190–1194 (2000). This work introduces the characteristics of PWL in control systems and the applications of PWL non-linearity. [26] Goodfellow, I., Warde-Farley, D., Mirza, M., Courville, A. & Bengio, Y. in Proc. Int. Conf. Machine Learning Vol. 28 (eds Dasgupta, S. & McAllester, D.) 1319–1327 (PMLR, 2013). This paper proposes a flexible PWL activation function for deep PWLNNs, and ReLU can be regarded as its special case, and analysis on the universal approximation ability and the relations to the shallow-architectured PWLNNs are given. [27] Yarotsky, D. Error bounds for approximations with deep ReLU networks. Neural Netw. 94, 103–114 (2017). [28] Bunel, R., Turkaslan, I., Torr, P. H. S., Kohli, P. & Mudigonda, P. K. in Adv. Neural Inf. Process. Syst. Vol. 31 (eds Bengio, S. et al.) 4795–4804 (2018). [29] Jia, J., Cao, X., Wang, B. & Gong, N. Z. in Proc. Int. Conf. Learning Representations (ICLR, 2020). [30] DeVore, R., Hanin, B. & Petrova, G. Neural network approximation. Acta Numerica 30, 327–444 (2021). This work describes approximation properties of neural networks as they are presently understood and also discusses their performance with other methods of approximation, where ReLU are centred in the analysis involving univariate and multivariate forms with both shallow and deep architectures. [31] Xu, J., Boom, T., Schutter, B. & Wang, S. Irredundant lattice representations of continuous piecewise affine functions. Automatica 70, 109–120 (2016). This paper formally describe the PWLNNs with irredundant lattice representations, which possess universal representation ability for any continuous PWL functions and yet has not been fully explored to construct the potentially promising deep architectures. [32] Hu, Q., Zhang, H., Gao, F., Xing, C. & An, J. Analysis on the number of linear regions of piecewise linear neural networks. IEEE Transactions on Neural Networks Learn. Syst. 33, 644–653 (2022). [33] Zhang, X. & Wu, D. Empirical studies on the properties of linear regions in deep neural networks. In Proceeding of the International Conference on Learning Representations (2020). [34] Maas, A., Hannun, A. Y. & Ng, A. Y. Rectifier nonlinearities improve neural network acoustic models. Proc. ICML 30, 3 (2013).
CVPR 2022论文和代码下载
后台回复:CVPR2022,即可下载CVPR 2022论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的3篇Transformer综述PDF
目标检测和Transformer交流群成立
扫描下方二维码,或者添加微信:CVer222,即可添加CVer小助手微信,便可申请加入CVer-目标检测或者Transformer 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer等。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测或者Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲扫码或加微信号: CVer222,进交流群
CVer学术交流群(知识星球)来了!想要了解最新最快最好的CV/DL/ML论文速递、优质开源项目、学习教程和实战训练等资料,欢迎扫描下方二维码,加入CVer学术交流群,已汇集数千人!

▲扫码进群
整理不易,请点赞和在看