
©作者 | 申琛惠 程丽颖 邴立东 司罗 等
单位 | 阿里巴巴达摩院

论文标题:
MReD: A Meta-Review Dataset for Structure-Controllable Text Generation
Findings of ACL 2022
https://arxiv.org/abs/2110.07474
https://github.com/Shen-Chenhui/MReD
https://nlp.aliyun.com/mred

传统的文本生成任务(不可控制型生成)通常只能训练模型,生成单一的贴近标准文本(gold)的内容,却忽视了在实际书写中,作者需要根据具体情况来强调不同侧重点的需求。如果没有实际的应用背景,对于不同的生成内容我们很难区分孰优孰劣,而生成符合应用背景的内容则需要模型对于相关领域有足够深入的“了解”。可控制型文本生成旨在文本生成的基础上进一步控制文本生成的方向,使生成的文本充分满足控制变量的要求,进而更为灵活地满足实际应用的需求。目前已有的可控文本生成研究探索了文本情感的正负度(sentiment polarity)【1】、文本语言的正式性或礼貌程度【2】等。这些研究存在两个明显的局限:1)缺乏更为精确的依据内容功能性进行的控制;2)不能对生成文本进行篇章/文档级的控制。我们针对当前可控制型文本生成研究领域存在的以上两个问题,首次提出了篇章级可控文本生成任务,并整理了较大规模、逐句标注的领域主席评审数据集(MReD: Meta-Review Dataset),来尝试在深刻“理解”领域背景知识的前提下,通过控制目标文本的整体结构来更精细和可控地生成文本。
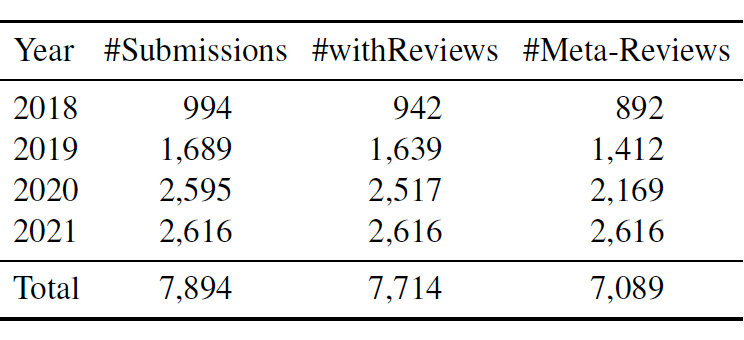
为了构建实验数据集,我们先从 OpenReview 的平台上抓取了 ICLR 会议 2018 至 2021 年中的 7894 篇论文。经过删选,我们保留了其中 7089 篇同时拥有同行评审(peer reviews)和其对应主席评审(meta-reviews)的文章来组成我们的 MReD 数据集。详情如下图所示。
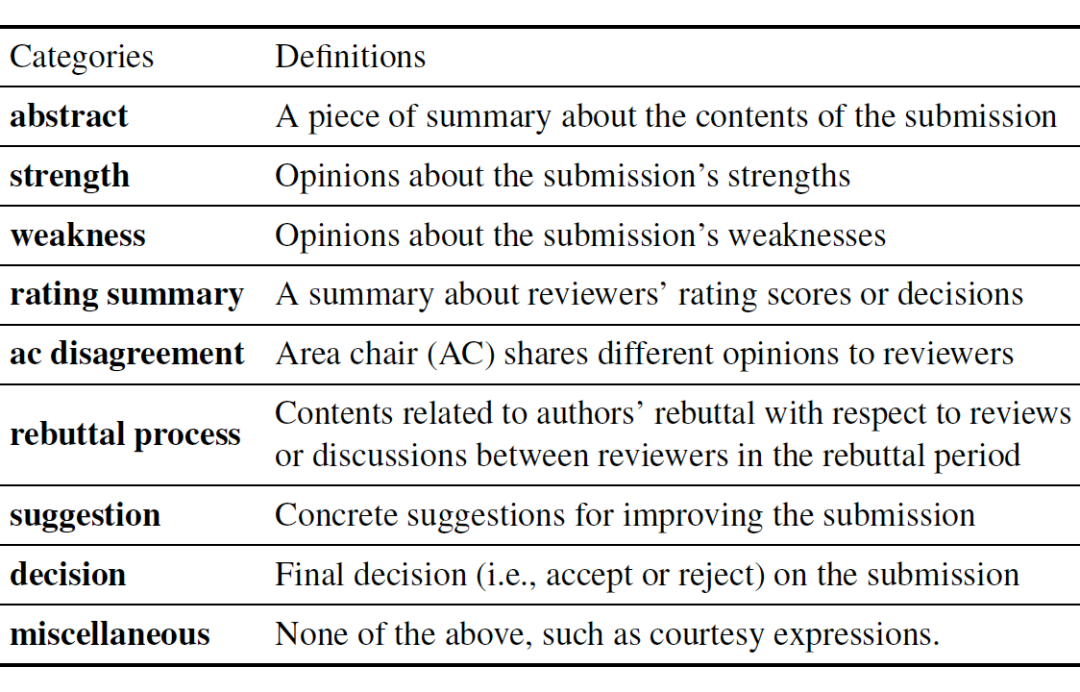
我们雇佣了 12 位专业的数据标注员对以上选中的 7089 篇主席评审进行了逐句标注(共 23675 句)。根据主席评审每一句的功能性以及上下文的背景,标注员把每一个句子标注为以下 9 个类别之一:
在标注的每个流程中我们都进行了严格的质量把关。每个批次我们都会抽查标注数据,不过关的标注会被要求通篇重标,直到合格为止。每个句子由两位不同的标注员各自标注,最终我们取得的标注一致性指数(Cohen's kappa)为 0.778。最后一个流程则是将之前标注不一致的内容转交第三位专家标注员来决定最终标签。以下为一篇主席评审的标注示例:

我们数据集的一大优势就是让可控制型文本生成模型,使用带有大量领域背景知识的数据来训练(即我们对主席评审中句子的功能性进行逐句标注,并收集了对应的文章录稿或拒稿信息、审稿人给出的打分及其对打分的自信度等),进而使得模型能够按照特定的控制要求,生成符合领域需求的文本。具体来说,在篇章级可控文本生成时,我们可以指定生成的 meta-review 的结构,从而控制最终的生成内容。比如用序列“abstract | strength | weakness | decision”来控制,输出的 meta-review 应该会先概括论文,然后指出其优缺点,最后给出录用结论。我们选择了使用由同行评审及主席评审组成来数据集,主要原因有二:这个领域的数据已有大量的公开内容,并且审稿流程也有逐渐透明化的趋势,如此可以更利于大家开展后续对可控制型生成的研究;同时,相信大家都对审稿流程并不陌生,因此也可以更为轻松地理解我们的工作以及我们提出的篇章级可控模型的价值。篇章级可控文本生成的方法并不局限于我们提出的主席评审的领域,亦可为其他不同的数据生成领域所用。

我们对 MReD 中句子类型的分布进行了统计。在我们数据集使用的 7089 篇文章中,共有 2368 篇被录稿,4721 篇被拒稿。其中,“abstract”和“strength”在被录用的文章中占比最高;而在被拒绝的文章中,“weakness”占比最高。如下图所示:
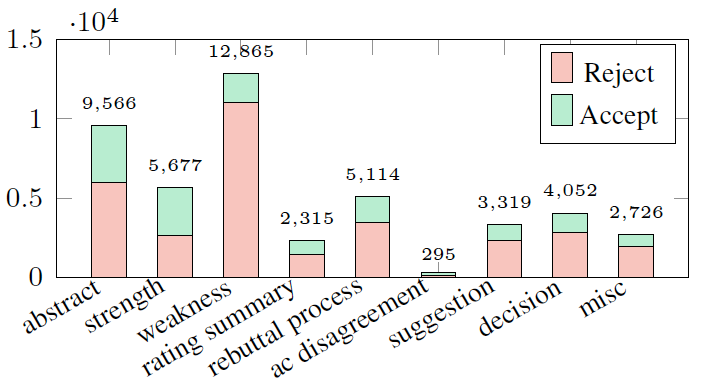
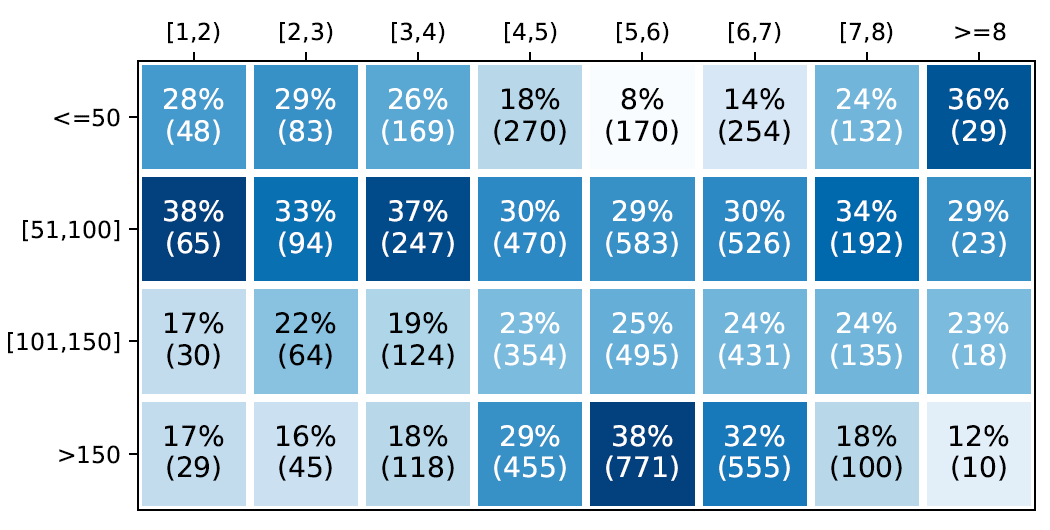
这些在主席评审中占比较高的种类基本都是可以通过总结同行评审得到的。但是也有一些不常见的类别(比如“ac disagreement”)不能通过总结得出,占数据的极少数。此外,我们也分析了在不同的平均同行打分上主席评审长度的分布,如下图所示。可以看出,当平均分在居中位(4~7 分)时,主席评审较长;而当平均分较高或较低时,主席评审则较为简短。这个分布是符合常识的:打分很高或很低大概率代表着论文有着明显的优点或缺点,也更容易让主席做出最终是否录稿的决定;当打分更靠近边界线(borderline)时,主席需要花更长的篇幅来分析论文优缺点并给出最终决定。
我们进一步观察了标注中标签的前后转移规律并整理出了下图。其中<start>代表主席评审的起始位置,<end> 代表结尾位置。我们将同一标签的多句相邻句子视作同一个片段(segment),故不将相同标签的转移计入下图中(即同一标签转移到相同标签的概率为 0)。如图所示,主席评审通常以论文内容梗概(“abstract”)作为开头,给出最终结论(“decision”)或建议(“suggestion”)作为结尾。同时,一些常见的标签转移序列,如“abstract | strength | weakness”, “rating summary | weakness | rebuttal process”, “abstract | weakness | decision” 等。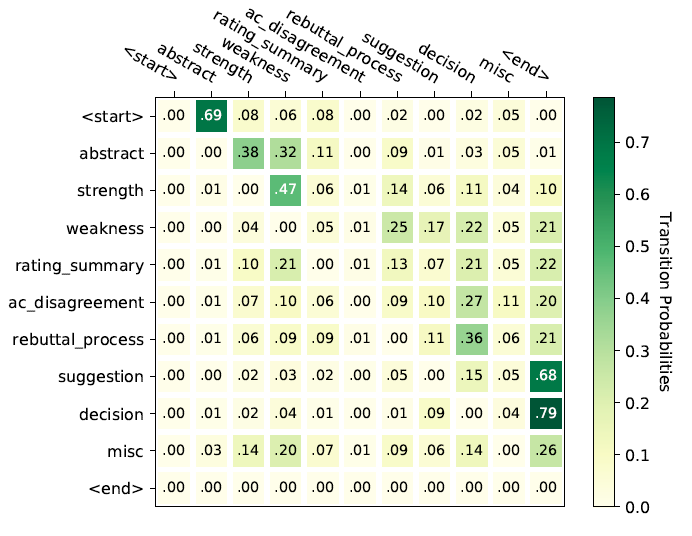

我们探索的基于 MReD 可控制型生成的主要关注点是结构的可控制性:在给出一段由多个标签组成的控制序列,以及同一论文的多个同行评审内容后,模型可以生成同时符合控制序列、并可以由同行评审内容总结出的主席评审。为了验证任务的可行性,我们尝试了抽取式(extractive)模型和抽象式(abstractive)的摘要模型。在抽取式模型方面,我们首先训练了分类器来根据定义的 9 类标签(定义详情请见第二部分 MReD 数据集介绍)对同行评审进行逐句分类。在生成过程中,我们限制抽取式模型只抽取满足控制类别的句子,从而使生成内容符合正确的控制序列(the gold control sequence)。在抽象式生成上,我们分别尝试了两种控制方法:片段式控制(seg-ctrl)和逐句式控制(sent-ctrl)。在片段式控制中,控制序列中的每个标签代表着目标文本中一句或连续几句符合该标签的句子(即符合该标签的一个“片段”),因此给出的控制序列中相邻标签不会重复;在逐句控制中,单个控制标签代表了生成一句符合该标签的句子,多个相邻相同的标签则代表着生成连续的多个符合该标签的句子。同时,除了同行评审,我们额外给模型提供了同行的打分信息(reviewers' rating scores)。在最常用的编码解码结构(encoder-decoder based architecture)上,我们的输入文本开头为对生成目标的控制序列(如: "abstract | abstract | stength ==> "),接着是同行评分的句子(例如:"R1 rating score: 8, R2 rating score: 5, R3 rating score: 7."),最后部分则是按顺序依次相连的多篇同行评审内容。通过把控制信息(标签序列)作为输入文本的一部分,我们的方法和数据可以直接作为不同架构模型的输入;把重要的控制信息放在开头可以避免控制信号受到后续内容的干扰,以及防止模型因对于输入文本字数限制而做出的截断处理(truncation)导致的控制信息损失。此外,为了满足编解码结构只允许一段输入文本的限制,我们尝试了不同的将多篇同行评审组合成为一整段输入文本的方法。由于输入篇幅过长,我们也进行了在抽象式生成模型上限制不同输入长度的实验。我们发现比起单篇同行评审,多篇同行评审的输入为模型提供了更多有用的信息,能够取得更好的生成结果。但是过多的信息反而会造成了模型表现的下降(如输入字符数从 2048 增加到 3072)。目前,如何更好地充分利用多篇同行评审中的信息仍是一个待研究的方向。

我们在常见的抽取式模型 Lexrank【3】, Textrank【4】, MMR【5】以及抽象式模型 Transformers【6】(bart-large-cnn)【7】 上进行了实验,分别对比了非控制型生成(unctrl)和控制型生成(sent-ctrl, seg-ctrl)的结果。此外,我们分别选取各个标签的代表性句子,按其来源,分别建立输入典型(“Source Generic")和输出典型(“Target Generic”)基线,以便检验只用这些句子组成 meta-review 的效果。各结果如下图所示:
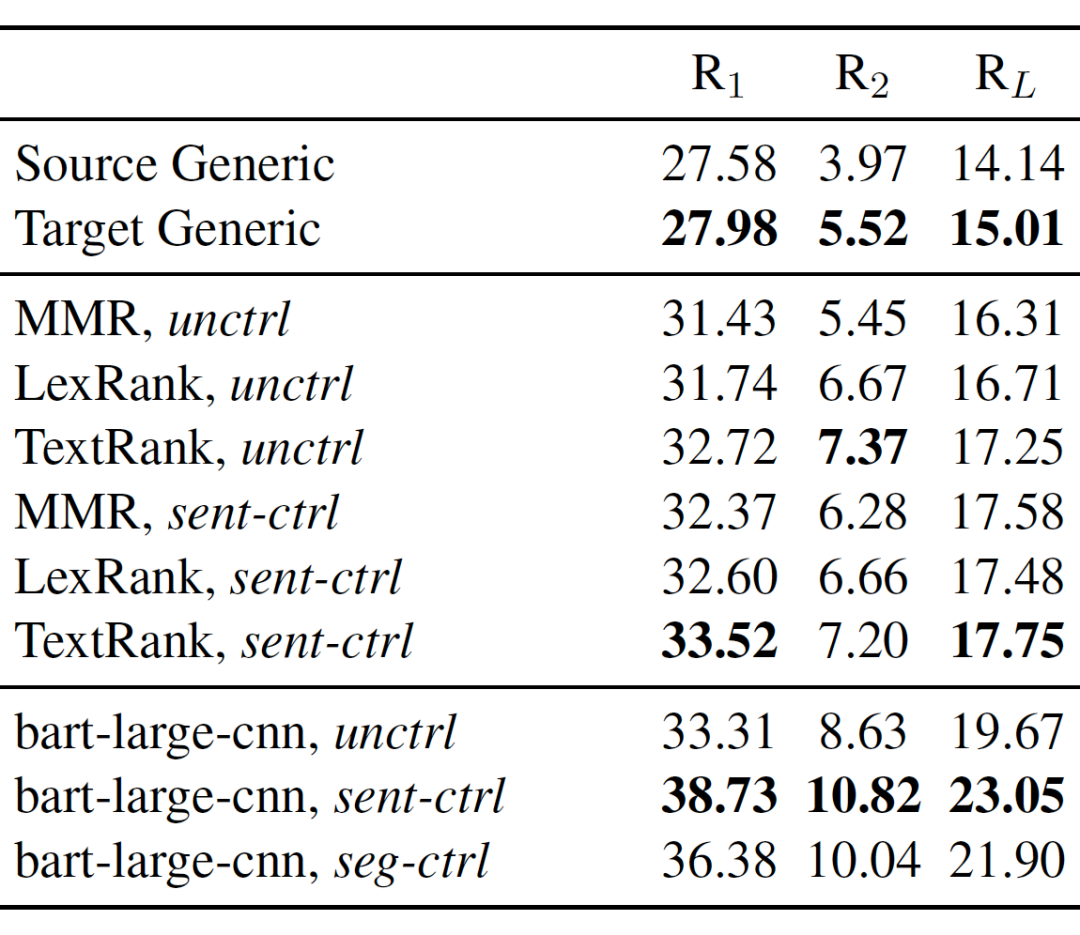
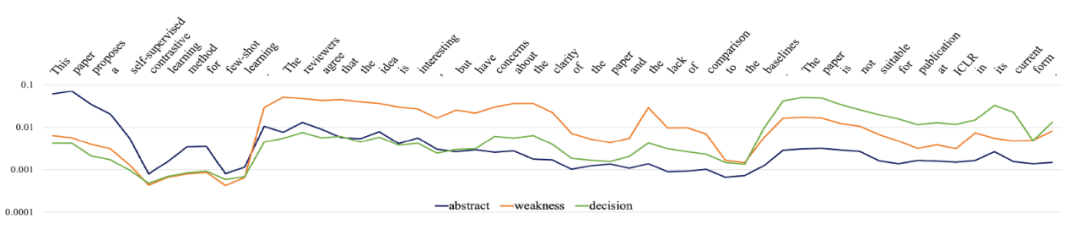
抽象式生成明显优于抽取式生成,可以看出 MReD 这个数据集较为抽象。且由训练集输出文本中抽取的代表性句子,所组成的输出典型的表现持续优于由输入文本中抽取的句子组成的输入典型。控制型生成在抽取式、抽象式生成中都优于非控制型生成,且其中更为精确的控制方法,逐句式控制(sent-ctrl),有更好的效果。我们分析了模型生成每个词时对各个控制标签的注意力权重(“attention weights”),如下图所示。模型在生成每一句的几乎所有词汇时,都会分配给对应标签更多的注意。
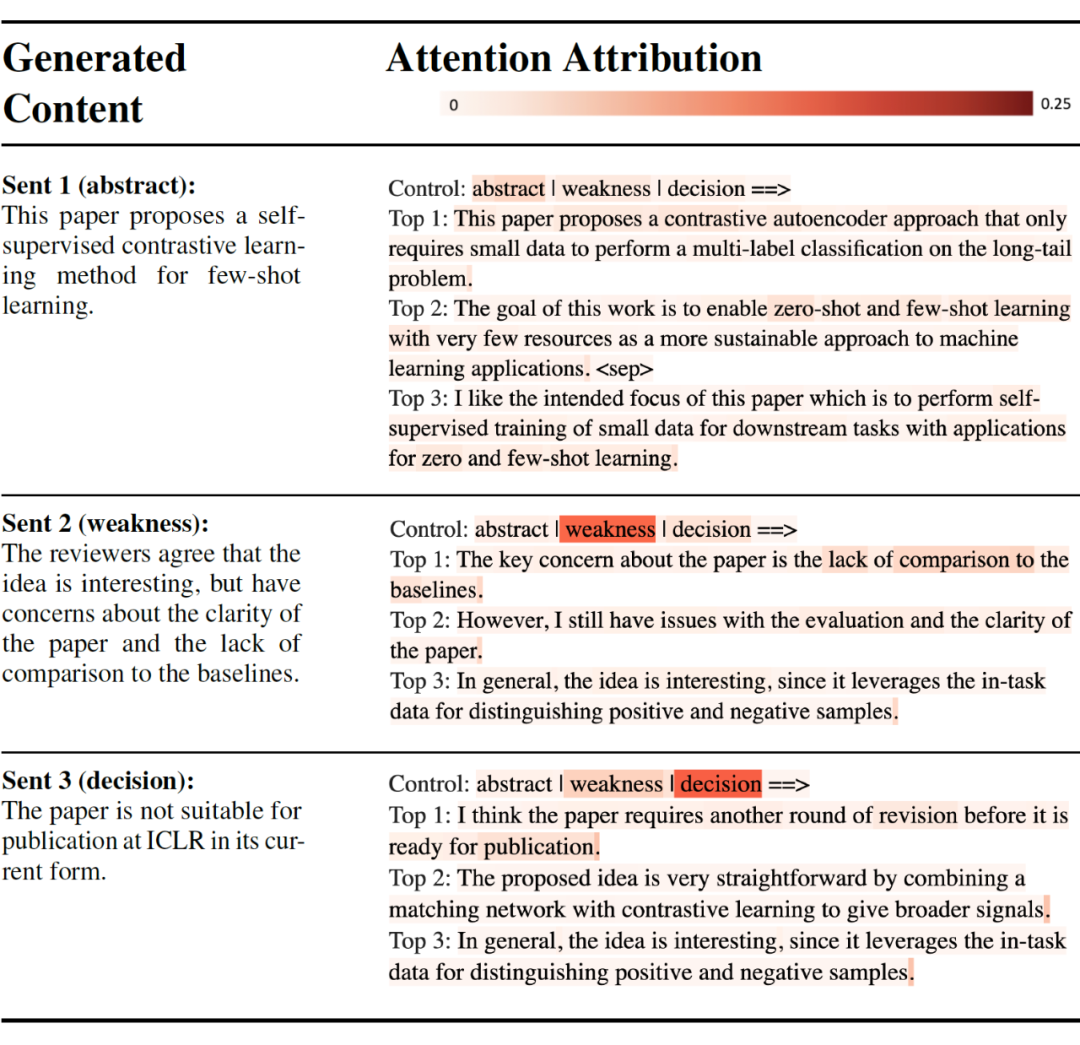
此外,我们根据模型生成词汇时对输入词汇的注意力权重分布,进一步分析出了每一句内容生成时注意力权重最大的前三句输入。如下图所示,我们在以上方法得出的前三句输入句子、以及所有控制标签上,用不同深浅的红色标注出了每个词汇从每句生成内容(左列)上所得的不同的注意力强弱(右列)。生成的句子不但给了对应控制标签较多的注意力,而且生成内容也有迹可循。例如在第二句(weakness)的生成上,模型准确地抓取到了输入内容中的“interesting”,“clarity”和“lack of comparison to baselines”这些关键信息。
为了进一步验证我们生成方法的可控制性,我们还对同一输入使用了其他多种不同于 gold sequence 的控制序列进行生成。如下图所示,我们的模型可以灵活地根据控制条件来生成不同侧重点的内容。例如,第 2 行的控制序列比第 1 行的多了一个“abstract”,于是模型多生成了一句有关论文梗概的补充信息,并且避免了生成内容的重复。这也是我们提出的控制方法的优势之一:我们可以通过当前控制标签的数量,来控制生成内容的篇幅和详略程度。此外,我们给出了一个较长的控制序列(第 3 行)。即使模型最终生成了拒稿的结论,生成的内容依旧较为礼貌和流畅,并且符合这个冗长的控制序列。

我们基于目前表现最佳的模型(逐句式控制模型,sent-ctrl)上线了任务 Demo(https://nlp.aliyun.com/mred),共分为三部分:任务介绍(Intro)、静态示例(Static Demo)和动态示例(Dynamic Demo),如下图所示。

静态示例展示的是我们用 OpenReview 上的论文审稿例子来生成的内容(提供了 OpenReview 网址)。在静态示例中,大家也可以查看我们设定的不同于 gold sequence 的其他控制序列时,生成内容的变化。动态示例允许人为地输入同行评审内容及控制结构序列,并使用在线模型来生成主席评审内容。由于 Demo 的计算资源有限,平均每次生成得到结果的时间会在 1 至 3 分钟左右,请大家耐心等待,不要刷新页面也不要打开多个窗口。如果服务器过于繁忙,可选择在其他时间段再进行尝试,或使用我们的 colab notebook 来利用 GPU 进行更为快速的生成(如果使用 colab,需自行将输入文本处理成要求格式,详情请见 colab 中的说明)。https://colab.research.google.com/drive/1VDrP34xTFXtD1VR2Ls-IoC3xCp52OT8L?usp=sharing&pli=1#scrollTo=qUpK8EEpdpp2

我们提出了篇章级可控生成的新任务,我们提出了几种在常见生成模型上的控制方法,灵活地控制生成文本的结构。同时,我们也整理并公开了一个适用于此任务、带有丰富领域背景信息的主席评审数据集。在这个数据上,我们提供了大量的篇章级可控生成的实验,作为同行进一步研究的比较基线。免责声明:虽然我们的模型可以根据输入 reviews 总结并生成一条可读性较好、结构符合预期的 meta-review,但不能代替领域主席对于某个科研工作的价值判断和研究建议。同时,我们的现有模型仍有一些待改进之处,例如生成一些错误的信息。以上两个方面也是我们需要继续深入研究的问题,同时希望这个工作也可以给大家的研究带来一些微小的启发。[1] Yi Liao, Lidong Bing, Piji Li, Shuming Shi, Wai Lam, and Tong Zhang. 2018. QuaSE: Sequence Editing under Quantifiable Guidance. In Proceedings of the EMNLP.
[2] Mingyue Shang, Piji Li, Zhenxin Fu, Lidong Bing, Dongyan Zhao, Shuming Shi, and Rui Yan.2019. Semi-supervised Text Style Transfer: Cross Projection in Latent Space. In Proceedings of EMNLP.
[3] Günes Erkan and Dragomir R Radev. 2004. Lexrank: Graph-based lexical centrality as salience in text summarization. Artificial Intelligence Research.
[4] Rada Mihalcea and Paul Tarau. 2004. Textrank: Bringing order into text. In Proceedings of EMNLP.
[5] Jaime Carbonell and Jade Goldstein. 1998. The use of mmr, diversity-based reranking for reordering documents and producing summaries. In Proceedings of ACM-SIGIR.
[6] Thomas Wolf, Julien Chaumond, Lysandre Debut, Victor Sanh, Clement Delangue, Anthony Moi, Pierric Cistac, Morgan Funtowicz, Joe Davison, Sam Shleifer, et al. 2020. Transformers: State-of-the-art natural language processing. In Proceedings of EMNLP.
[7] Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Veselin Stoyanov, and Luke Zettlemoyer. 2020. Bart: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. In Proceedings of ACL.

如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:[email protected]
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
