©PaperWeekly 原创 · 作者 | BNDSBilly
研究方向 | 自然语言处理

ICLR 2021 的一篇文章提出了基于 KNN 方法的机器翻译(kNN-MT),可以将 kNN 方法添加到现有的神经机器翻译模型(NMT)上,从而进一步提升推理表现。该方法帮助当时的 SOTA 德语-英语翻译模型提升了 1.5 BLEU 分数,并且还可以适应跨领域及零样本传输。
本次要分享的论文则是针对 kNN-MT 推理速度过慢的不足,提出了蒸馏方法(kNN-KD)。从而在保持 kNN-MT 表现的情况下,将推理速度提升到了与一般 NMT 模型推理速度相当的水平。

Nearest Neighbor Knowledge Distillation for Neural Machine Translation收录会议:
论文链接:
https://arxiv.org/abs/2205.00479
Methods
2.1 kNN-MT
KNN-MT 方法有两个步骤:
1. Datastore creation:
根据训练集每一条样本离线构建的键值对组合,如下公式所示。其中 表示样本的源语言句和目标语言句, 为翻译过程中第 步时已经推理出来的文本, 表示第 步需要推理的目标语言 token。 表示 经过模型 decoder 编码得到的高维向量。
2. Generation:
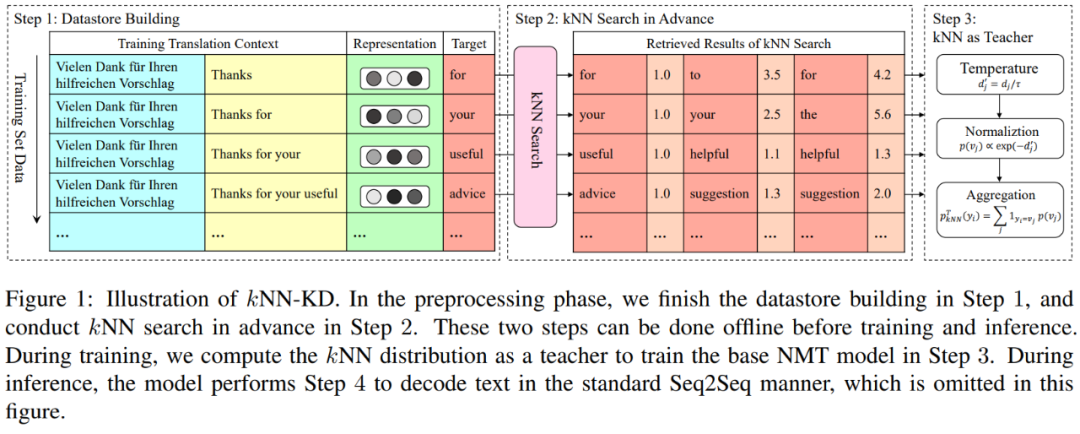
推理阶段的每一步时,首先根据 NMT 模型给出下一个 token 的输出概率 ,然后根据 kNN 方法给出下一个 token 的输出概率 ,最终的输出概率为 。kNN 输出概率如下:按照构造 Datastore 的方式,根据当前的测试样本先构建当前步骤的 key,然后遍历 Datastore 找到 距离最近的 个结果,将其距离进行一系列操作后,转化为对应 value 的输出概率,如下图所示:在一般训练 NMT 模型时,通常使用 模型预测结果 和 grount-truth 的交叉熵(CE)进行训练。但在自然语言中,一个句子通常有多种表达,如果模型预测出一个合理但偏离 grount-truth 的词,CE损失也会将其视为错误并惩罚模型,导致模型泛化性变差,这就是所谓的 overcorrection。 而在 KNN-MT 中,在解码阶段综合考虑了其他可能的合理解释,在一定程度上缓解了该问题,所以表现有了明显提升。2.2 kNN-KD
针对 kNN-MT 推理速度很慢的劣势,本文作者提出了 kNN-KD 方法,步骤如下:
1. Datastore creation:与 kNN-MT 相同
2. Distillation:
对于教师模型,在训练前针对每一条训练样本的每一步骤,都按照类似 kNN-MT 中的方法输出下一 token 的生成概率 。对于学生模型,针对每一条训练样本的每一步骤,都正常输出下一 token 的生成概率 。训练过程中,蒸馏损失为教师模型和学生模型表现的交叉熵: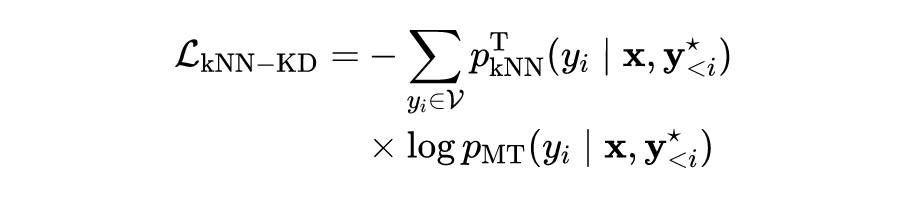

3. Generation:在最终的推理阶段,就不需要再进行 kNN 搜索了,只要按照正常的 NMT 模型进行翻译即可。
本文使用 IWSLT'14 德语-英语(De-En,160k 训练样本)、IWSLT'15 英语-越南语(En-Vi,113k 训练样本)和多域翻译数据集(De-En,733k 训练样本)进行了实验。使用 tst2012 作为验证集,使用 tst2013 作为测试集,分别包含 和 个句子。本文所提出的 kNN-KD 是一种无架构方法,可应用于任意 Seq2Seq 模型,可以与其他提升性能的工作同时应用。因此,作者主要将 kNN-KD 与 kNN-MT 以及一些典型的 KD 方法进行比较,包括但不限于 Word-KD、Seq-KD、BERT-KD 和 Selective-KD 等。
实验中所有算法都利用 pytorch 中的 fairseq 工具包实现,在 个 NVIDIA GTX 1080Ti GPU 上进行。实验模型选取 层 Transformer。对于 IWSLT'14 和 IWSLT'15 模型,配置 embedding size 为 ,feed-forward size 为 ,attention heads 为 。针对跨领域数据集,配置 embedding size 为 ,feed-forward size 为 ,attention heads 为 。作者提前对 和 (归一化温度)进行了网格搜索,并选取了验证集上的最佳 BLEU 分数对应的超参数 ,如下表所示,其中 表示 Datastore 中数据个数:

3.2 Results
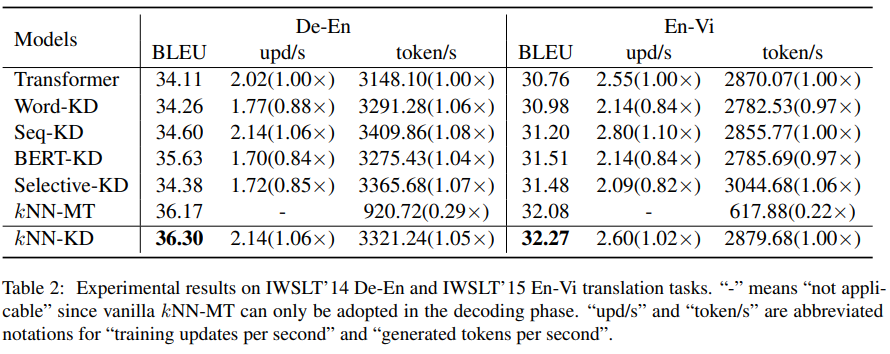
在 IWSLT 数据集上的实验结果如下表所示,KNN-KD 超过了所有其它强 baseline,比 Transformer 取得了 和 的 BLEU 分数提升。
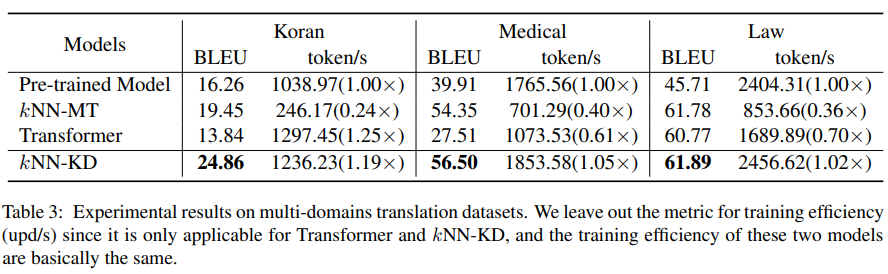
在跨领域数据集上,kNN-KD 同样超过了其他 baseline,如下表所示。在各领域中,kNN-KD 均可以超过 kNN-MT 的表现,且推理速度显著提升。
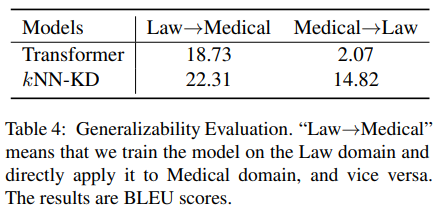
同样,作者也进一步研究了 kNN-KD 的泛化性:在特定领域训练了一个 NMT 模型,并在 out-of-domain 的测试集上进行了测试,实验结果如下表所示,kNN-KD 的泛化性明显优于仅靠标准 CE 训练的 Transformer。
Conclusion
在本文中,作者提出了 kNN-KD,它提取通过 kNN 检索得到的知识,以缓解基础 NMT 模型过度校正的问题。实验表明,kNN-KD 可以改进普通 kNN-MT 和其他baseline,而无需任何额外的训练和解码成本。

如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:[email protected]
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
