头部厂商纷纷切入AI ASIC领域,技术路径不同。谷歌15年发布第一代TPU(ASIC)产品,TPU产品持续迭代升级。英特尔19年收购人工智能芯片公司Habana Labs,22年发布AI ASIC芯片Gaudi 2,性能表现出色;IBM研究院22年底发布AI ASIC芯片AIU,有望23年上市;三星第一代AIASIC芯片Warboy NPU芯片已于近日量产。头部厂商纷纷切入 AI ASIC领域,看好ASIC在人工智能领域的长期成长性。谷歌:谷歌为AI ASIC芯片的先驱,于15年发布第一代TPU(ASIC)产品,大幅提升AI推理的性能;17年发布TPU v2,在芯片设计层面,进行大规模架构更新,使其同时具备AI推理和AI训练的能力;谷歌TPU产品持续迭代升级,21年发布TPU v4,采用7nm工艺,峰值算力达275TFLOPS,性能表现全球领先。英特尔:19年底收购以色列人工智能芯片公司Habana Labs,22年发布Gaudi 2 ASIC芯片。从架构来看,Gaudi架构拥有双计算引擎(MME和TPC),可以实现MME和TPC并行计算,大幅提升计算效率;同时,其将RDMA技术应用于芯片互联,大幅提升AI集群的并行处理能力;从性能来看,Gaudi 2在ResNET-50、BERT、BERT Phase-1、BERT Phase-2模型的训练吞吐量优于英伟达A100,性能表现优异。1、ASIC具有性能高、体积小、功率低等特点
ASIC具有性能高、体积小、功率低等特点。AI芯片指专门用于运行人工智能算法且做了优化设计的芯片,为满足不同场景下的人工智能应用需求,AI芯片逐渐表现出专用性、多样性的特点。根据设计需求,AI芯片主要分为中央处理器(CPU)、图形处理器(GPU)、现场可编程逻辑门阵列(FPGA)、专用集成电路(ASIC)等,相比于其他AI芯片,ASIC具有性能高、体积小、功率低等特点。CPU->GPU->ASIC,ASIC成为AI芯片重要分支。1)CPU阶段:尚未出现突破性的AI算法,且能获取的数据较为有限,传统CPU可满足算力要求;2)GPU阶段:2006年英伟达发布CUDA架构,第一次让GPU具备了可编程性,GPU开始大规模应用于AI领域;3)ASIC阶段:2016年,Google发布TPU芯片(ASIC类),ASIC克服了GPU价格昂贵、功耗高的缺点,ASIC芯片开始逐步应用于AI领域,成为AI芯片的重要分支。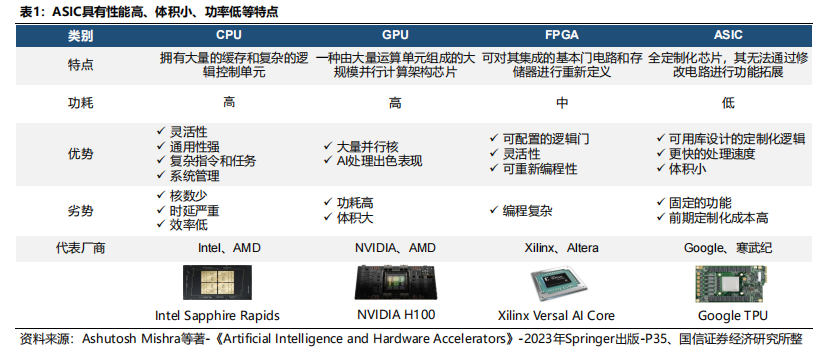
ASIC芯片在推理领域具有明显优势,有望在该领域率先出现爆品。根据CSET数据,ASIC芯片在推理领域优势明显,其效率和速度约为CPU的100-1000倍,相较于GPU和FPGA具备显著竞争力。尽管ASIC芯片同样可以应用于训练领域(例如TPU v2、v3、v4),但我们认为其将在推理领域率先出现爆品。
预计ASIC在AI芯片的占比将大幅提升。根据McKinsey Analysis数据,在数据中心侧,25年ASIC在推理/训练应用占比分别达到40%、50%;在边缘侧,25年ASIC在推理/训练应用占比分别达到70%、70%,ASIC在AI芯片的占比将大幅提升。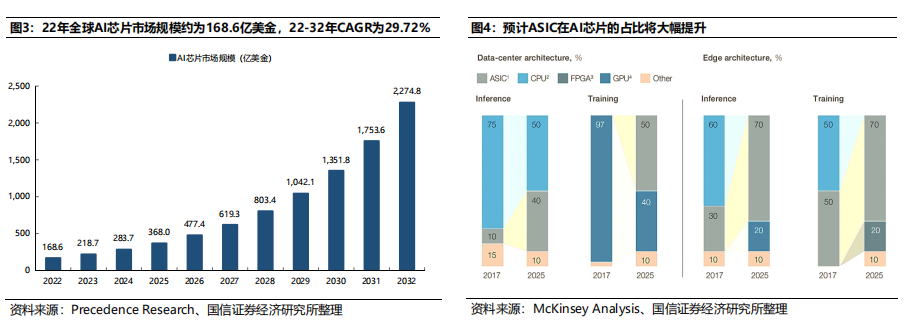
2、多种类AI芯片并存,头部厂商纷纷切入ASIC领域
多种类AI芯片并存,头部厂商纷纷切入ASIC领域。英伟达延续GPU路线,22年发布H100芯片,目前广泛应用于云端训练和推理;AMD利用自身技术积累,将CPU和GPU集成在一起,推出Instinct MI300芯片,预计23年H2上市。头部厂商开始切入ASIC领域,Google为AI ASIC芯片的先驱,21年推出TPU v4,运算效能大幅提升;英特尔19年收购Habana Lab,22年推出Gaudi2 ASIC芯片;IBM、三星等头部厂商亦纷纷切入ASIC领域。3、谷歌:全球AI ASIC先驱,TPU产品持续迭代;性能表现,A100<TPU v4<H100
谷歌为全球AI ASIC先驱,TPU产品持续迭代。谷歌2015年发布TPU v1,与使用通用CPU和GPU的神经网络计算相比,TPU v1带来了15~30倍的性能提升和30~80倍的能效提升,其以较低成本支持谷歌的很多服务,仅可用于推理;17年发布TPU v2,用于加速大量的机器学习和人工智能工作负载,包括训练和推理;18年发布TPU v3,算力和功率大幅增长,其采用了当时最新的液冷技术;20年和21年分别发布TPU v4i和v4,应用7nm工艺,晶体管数大幅提升,算力提升,功耗下降。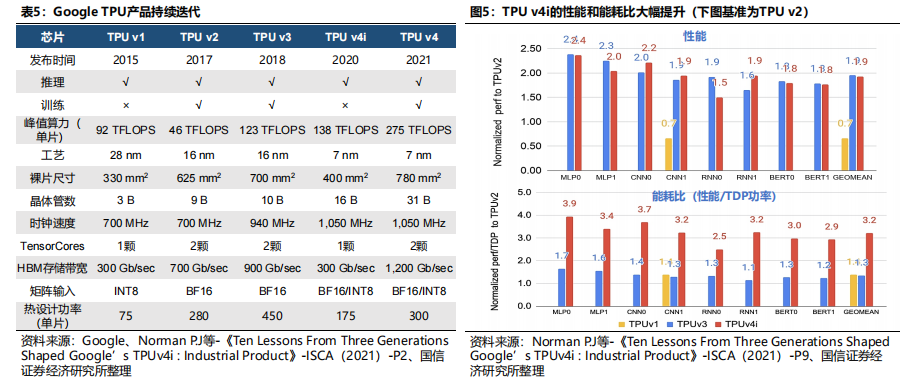
TUP v4性能表现优于英伟达A100。TPU v4的性能表现在BERT、ResNet、DLRM、RetinaNet、MaskRCNN下分别为A100的1.15x、1.67x、1.05x、1.87x和1.37x,性能表现优于英伟达A100。TUP v4性能表现略逊于H100,但功耗管理能力出色。根据《AI and ML Accelerator Survey and Trends》数据,英伟达H100的峰值性能表现高于TUP v4,而TUP v4作为ASIC芯片,在功耗管理方面表现出色,峰值功率低于H100。4、谷歌:TPU v1架构
统一缓冲器(Unified Buffer)和矩阵乘法单元(MMU)占据53%的芯片总面积。TPU v1主要包括统一缓冲器(Unified Buffer)、矩阵乘法单元(MMU)、累加器(Accumulators)、激活流水线电路(Activation Pipeline)、DDAM等,其中统一缓冲器和矩阵乘法单元面积占比最高,合计达53%。2)用户加载TPU编译的模型,将权重放入DDR3内存;5)主机触发执行,激活并通过矩阵乘法单元传播到累加器;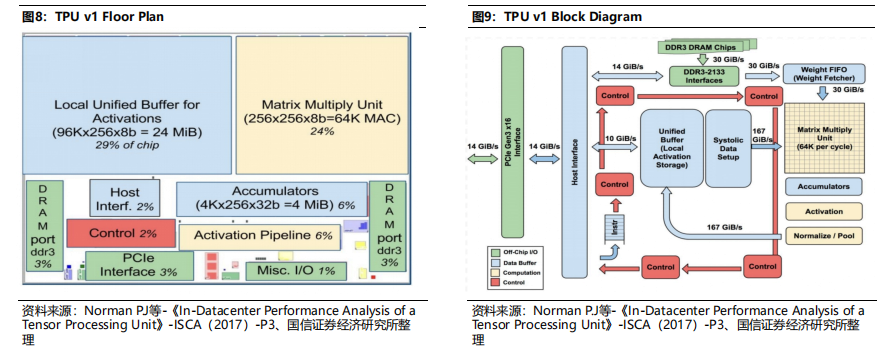
5、谷歌:TPU v2架构,基于TPU v1的大规模架构更新
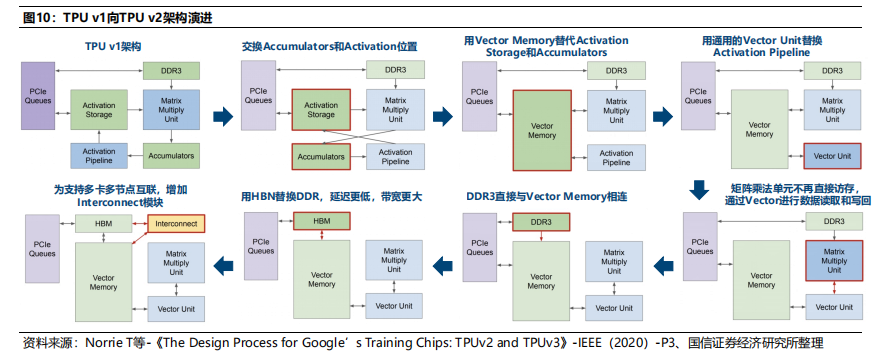
TPU v2内核数增加值2个。TPU v1仅有1个Tensor Core,导致管道更为冗长。TPU v2的内核数增加为2个,对编译器也更为友好。MXU利用率提升。TPU v1的MXU包含256*256个乘积累加运算器,由于部分卷积计算规模小于256*256,导致单个大核的利用率相对较低;而TPU v2的单核MXU包含128*128个乘积累加运算器,在一定程度上,提升了MXU利用率。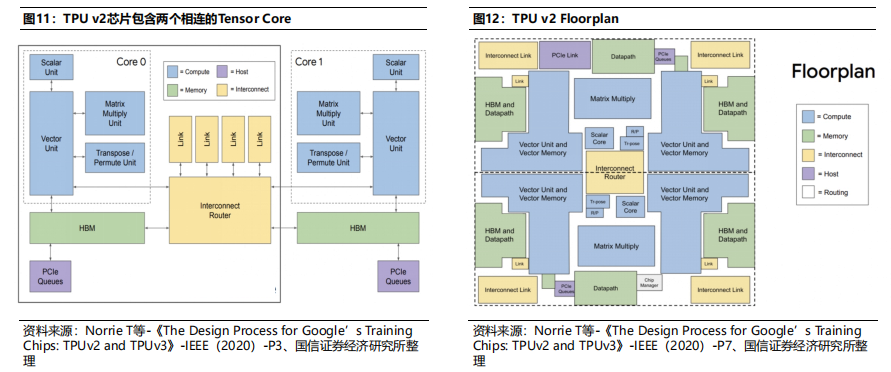
6、谷歌:TPU v3延续v2架构,性能提升,TDP优化
谷歌TPU v3延续v2架构,性能提升。TPU V3在v2架构的基础上,矩阵乘法单元(MXU)数量提升翻倍,时钟频率加快30%,内存带宽加大30%,HBM容量翻倍,芯片间带宽扩大了30%,可连接的节点数为先前4倍,性能大幅提升。采用液冷技术,TDP优化。TPU v3采用液冷技术,峰值算力为TPU v2的2.67倍,而TDP仅为TPU v2的1.61倍,TDP大幅优化。7、谷歌:TPU v4,硬件性能进一步提升
MXU数量翻倍,峰值算力大幅提升。从硬件提升来看,根据Google Cloud数据,TPU v4芯片包含2个TensorCore,每个TensorCore包含4个MXU,是TPUv3的2倍;同时,HBM带宽提升至1200 GBps,相比上一代,提升33.33%。从峰值算力来看,TPU v4的峰值算力达275 TFLOPS,为TPU v3峰值算力的2.24倍。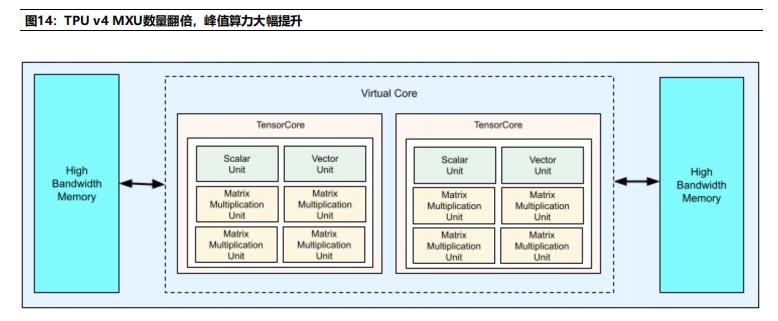
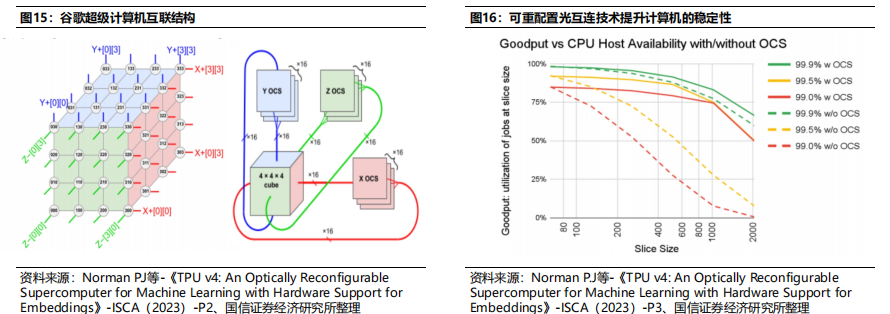
谷歌的超级计算机构想:将4*4*4(64)个TPU v4芯片连接成1个立方体结构(Cube),再将4*4*4个立方体结构(Cube)连接成共有4096个TPU v4芯片的超级计算机,其中物理距离较近TPU v4芯片(即同一个Cube中的4*4*4个芯片)采用常规电互联方式,距离较远的TPU(例如Cube之间的互联)间用光互连。采用光互连技术可以有效避免“芯片等数据”的情形出现,进而提升计算效率。可重配置光互连技术可以进一步提升计算性能。谷歌TPU v4通过加入光路开关(OCS)的方式,可以根据具体模型数据流来调整TPU之间的互联拓扑,实现最优性能,可重配置光互连技术可以将性能提升至先前的1.2-2.3倍。可重配置光互连技术提升计算机的稳定性。若计算机中部分芯片出现故障,可以通过该技术绕过故障芯片,进而不会影响整个系统的工作。
8、英特尔:Gaudi架构实现MME和TPC并行运算
英特尔收购Habana Lab。Habana Labs成立于2016年,总部位于以色列,是一家为数据中心提供可编程深度学习加速器厂商,2019年发布第一代Gaudi。英特尔于2019年底收购Habana Lab,旨在加快其在人工智能芯片领域的发展,2022年发布Gaudi 2。Gaudi架构实现MME和TPC并行运算。Gaudi架构包含2个计算引擎,即矩阵乘法引擎(MME)和TPC(张量处理核心);Gaudi架构使得MME和TPC计算时间重叠,进行并行运算,进而大幅提升计算效率。Gaudi 2延续上一代架构,硬件配置大幅提升。Gaudi 2架构基本与上一代相同,TPC数量从8个提升至24个,HBM数量从4个提升至6个(总内存从32GB提升至96GB),SRAM存储器提升一倍,RDMA从10个提升至24个,同时集成了多媒体处理引擎,硬件配置大幅提升。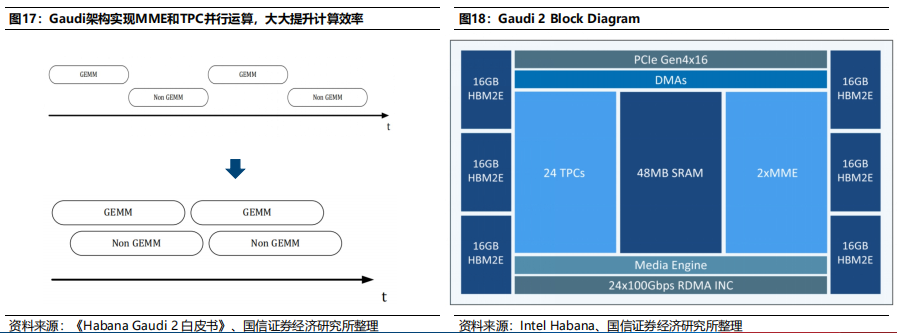
RDMA技术用于芯片互联,大幅提升并行处理能力。RDMA是一种远端内存直接访问技术,具有高速、超低延迟和极低CPU使用率的特点。Gaudi将RDMA集成在芯片上,用于实现芯片间互联,大幅提升AI集群的并行处理能力;同时,Gaudi支持通用以太网协议,客户可以将Gaudi放入现有的数据中心,使用标准以太网构建AI集群。Gaudi 2性能表现出色。根据《Habana Gaudi 2 White Paper》披露数据,Gaudi 2在ResNET-50、BERT、BERT Phase-1、BERT Phase-2模型的训练吞吐量分别为A100(40GB,7nm)的2.0、2.4、2.1、3.3x,性能表现出色。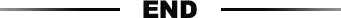
申明:感谢原创作者的辛勤付出。本号转载的文章均会在文中注明,若遇到版权问题请联系我们处理。
推荐阅读
更多架构相关技术知识总结请参考“架构师全店铺技术资料打包”相关电子书(37本技术资料打包汇总详情可通过“阅读原文”获取)。
全店内容持续更新,现下单“架构师技术全店资料打包汇总(全)”,后续可享全店内容更新“免费”赠阅,价格仅收198元(原总价350元)。
温馨提示:
扫描二维码关注公众号,点击阅读原文链接获取“架构师技术全店资料打包汇总(全)”电子书资料详情。