海归学者发起的公益学术平台
分享信息,整合资源
交流学术,偶尔风月

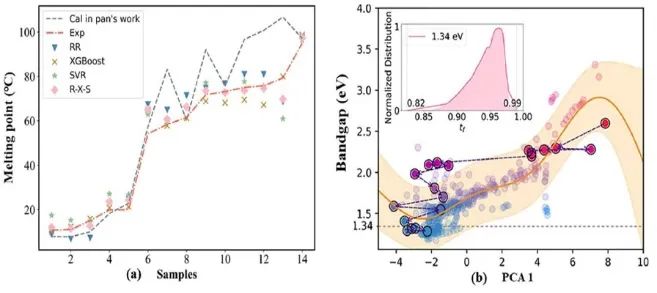
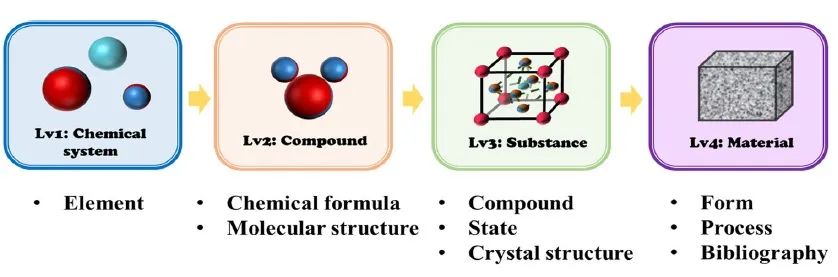
小数据由于数据规模小、特征维过高或过低,容易造成数据不平衡和模型过拟合或欠拟合的问题,这一直是材料机器学习的痛点之一。上海大学化学系陆文聪教授课题组结合前沿研究成果,介绍机器学习辅助材料设计与发现的一般流程,并综述了该过程中小数据的处理方法,包数据源层面的文献数据提取、材料数据库建设、高通量计算和实验;算法层面的小数据建模算法和不平衡学习;机器学习策略层面的主动学习和迁移学习。最后,提出了小数据机器学习在材料科学领域的发展方向。
大部分材料机器学习课题的数据量还处于小数据阶段。就数据源而言,自然语言处理技术与文本挖掘的发展可以从文献中自动提取数据;材料数据库的发展可以方便收集碎片化的材料数据;此外,高通量技术可以通过实验或计算方法在短时间内获得大量高质量的数据。机器学习模型除了依靠数据之外还要依靠算法,而有些算法因其本身的原理就很适合小数据建模。适合小数据集的算法包括支持向量机、高斯过程回归、随机森林、XGBoost、梯度提升决策树和符号回归。传统的分类方法通常在每个类别的数据大小几乎相等的情况下处理数据,但材料科学中的数据类别往往是不平衡的,不平衡学习可以处理因一类样本量有限而造成的数据不平衡问题。主动学习可以从大量的无标记数据中选取样本进行标记,使小数据中的信息尽可能代表大的无标记数据,实现小数据下的大数据分析和处理。迁移学习可以在给定的源域和学习任务中获取知识,结合目标域小数据调整预训练模型的参数,提高模型对小数据的预测精度。本综述旨在为材料机器学习中的小数据问题提供解决方案。该文近期发表于npj Computational Materials 9,42(2023),英文标题与摘要如下,点击左下角“阅读原文”可以自由获取论文PDF。
Small Data Machine Learning in Materials Science
Pengcheng Xu, Xiaobo Ji, Minjie Li & Wencong Lu
This review discussed the dilemma of small data faced by materials machine learning. First, we analyzed the limitations brought by small data. Then, the workflow of materials machine learning has been introduced. Next, the methods of dealing with small data were introduced, including data extraction from publications, materials database construction, high-throughput computations and experiments from the data source level; modeling algorithms for small data and imbalanced learning from the algorithm level; active learning and transfer learning from the machine learning strategy level. Finally, the future directions for small data machine learning in materials science were proposed.