

丛京生院士介绍了他在民主化集成电路设计和可定制计算上的由一系列工作所形成的生态系统。引言:丛京生院士为作者之一的论文“AutoDSE: Enabling software programmers to design efficient FPGA accelerators”获得了2023 ACM TODAES最佳论文奖。为了介绍这项工作以及丛院士在民主化集成电路设计和可定制计算上所构建的生态系统,VLSI架构综合技术研究室翻译了他在ICCAD’2022开幕日所做的主题演讲,以飨读者。
很高兴在ICCAD’2022现场见到这么多同仁!我本人也非常荣幸能够在这次的ICCAD开幕日做主题演讲。ICCAD对我来说有着非常特别和重要的意义。35年前我的第一篇论文是在ICCAD上发表的。在这张幻灯片左边,你可以看见这篇文章的截图。因为年代久远,我并没有在ICCAD Proceedings上找到这篇文章的电子版,但是我在IEEE Transactions on CAD上还是找到了这篇文章的期刊版本。
幻灯片右边,你能看见当年UIUC四位年轻的研究生。站在我旁边的男士是黄定发教授,他现在是香港中文大学工程学院院长。站在我旁边的年轻女士现在是IBM EDA部门的资深员工。站在照片最左边的男士是KC Chen。你们中的有些人可能知道他是前世界级芯片验证公司Veriplex的共同创办人。Veriplex后来被Cadence收购。当我找到这张照片的时候,心中涌起了许多回忆。最重要的一点,我想说这次的主题演讲也是为我的导师刘炯朗先生所做。他也是这篇文章的作者之一。他的一言一行带领我走进了EDA的世界并引导我了解如何真正做好科研。我非常希望刘炯朗先生今天也能在现场,然而他在两年前不幸过世。相信我们所有人都会记住他在这个领域深耕几十年的巨大贡献。
我在这篇文章里讲的是一种三层芯片设计通道布线(three-layer channel routing)的方法。这在当时是个新问题,是我在1987年根据当年的技术水平写的文章。在那个时候芯片还只有两层的设计所以我们猜测工业界会向三层或者多层发展。那么这个情况下的布局布线问题就是个很好的研究课题。实际上,我们在两年后的确看见Intel在486处理器上使用了三层的设计,顺带一提486芯片同时实现了片内集成超一百万晶体管的这个令人激动的里程碑。
所以当回看这35年间我的实验室的科研路线,前20年,我的关注点一直在服务于硬件工程师的电子设计自动化。我们希望他们可以设计出更好的奔腾处理器或者更好的硬件加速器。但是过去的10年或15年我们逐渐地改变了重心:变成可以让更多的软件工程师来设计他们自己所需要的定制化集成电路和加速器,特别是其在FPGA上的实现。当被问到为什么我们要转换跑道,我想说,我们想使得可定制计算成为可能。我们可以用下面这幅图来解释一下15年前为什么我们决定开始转变赛道。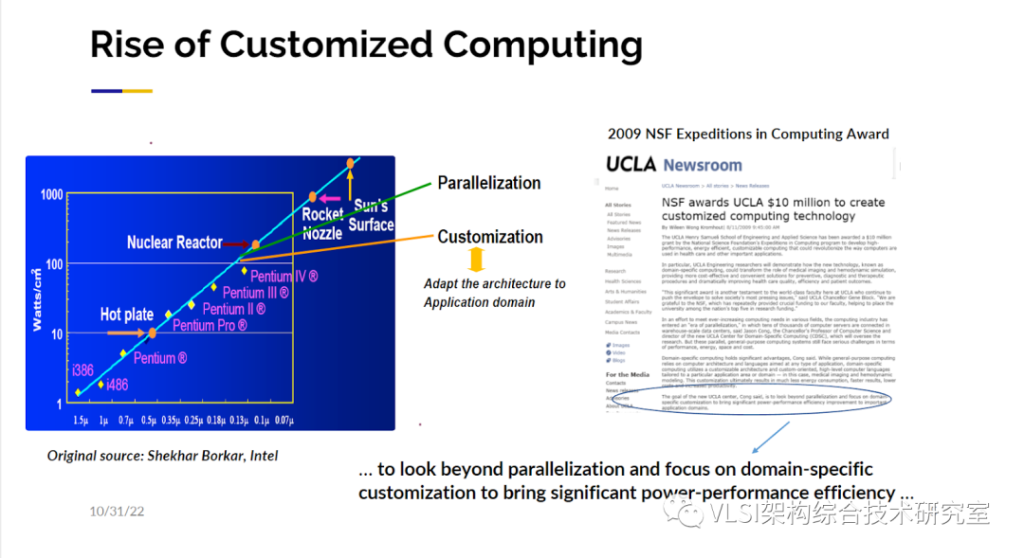
各位可能都见过这幅Intel绘制的能耗图线。我们可以看到频率的增加是和热量的产生成正比的。今天大多数的芯片都运行在2-4GHz之间。想做一个太赫兹级的芯片其实是没有问题的,只是做完运行后你大概率会发现芯片被自己烧了。所以工业界在2000年中后期沿着图线向右折了一下, 从单纯提高频率转向并行设计。基本意思就是我们尽量保持现有的频率,然后增加更多的核来设计出更强大的芯片。当时也有对功率和散热进行专门的分析。在那个时候,我们实际上已经提出了一个更大胆的想法,那就是我们应该再往下走一步让芯片架构服务于具体应用,而不是先固定架构再进行开发。所以我们向美国国家科学基金会(NSF)提交了一个相关的项目申请。很幸运,这个项目获得了NSF的5年1000万美元的资助并同时获得了Expedition in Computing的奖项。这在当时应该是NSF最大的奖项和资助之一。在申请中我们写了出现在幻灯片里的一句话“不止着眼于并行设计,同时关注特定领域可定制设计从而显著提高功耗-性能的效率”。我们不仅写下了这句话,我们也是沿着这个方向努力去做的。实际上也有很多同仁做出了成功的例子。其中最著名的例子是谷歌的TPU。TPU就是专门为一种应用而设计的,那就是深度学习。如果你仔细去看TPU的设计架构,他主要就是由一个个矩阵-向量乘法块或者矩阵-矩阵乘法块构成。TPU的论文报告了相比于最先进CPU快200倍,GPU快70倍的性能提升。当然现在CPU和GPU的性能也在提升,所以这是个大概的数字。谷歌的TPU是个非常大的成就。但是设计类似TPU这样的特定芯片有一些显著的限制。首当其冲的问题就是必须非常有钱。根据麦肯锡做的调查报告设计制造7nm的芯片需要花费至少15亿人民币。你有没有15亿人民币这是第一个问题。第二个问题是你必须要很有耐心。我实验室的学生不是很喜欢去设计芯片以及流片,原因之一就是从你有想法到流片成功至少需要两年的时间。万一你的设计流片回来发现有问题你又要重新流片,这就很难及时发出文章。一般毕业你可能需要有三篇文章发表,那你什么时候才能毕业呢?不仅如此各类算法和设计都在快速推陈出新,可能现在的想法很快就过时了。所以冗长的设计周期也是一项限制。尽管可定制计算芯片有诸多限制,你还是可以在可编程逻辑器件FPGA上实现很多的可定制计算,也能达到很高的计算效率。我在这里想举一个我们在ISCA’2020上发表的工作。这项工作其实是在讲一个很经典的问题——排序。不过不是对10000个数字排序,而是对超大规模,比如10T规模的数字进行排序。我们的做法从宏观上看是一个简单的归并排序,这样的排序先对许多小块数据进行排序,然后合并小块排序合成更大的块。你可以知道计算层面的算法复杂度是NlogN, 数据的移动也是最优化的。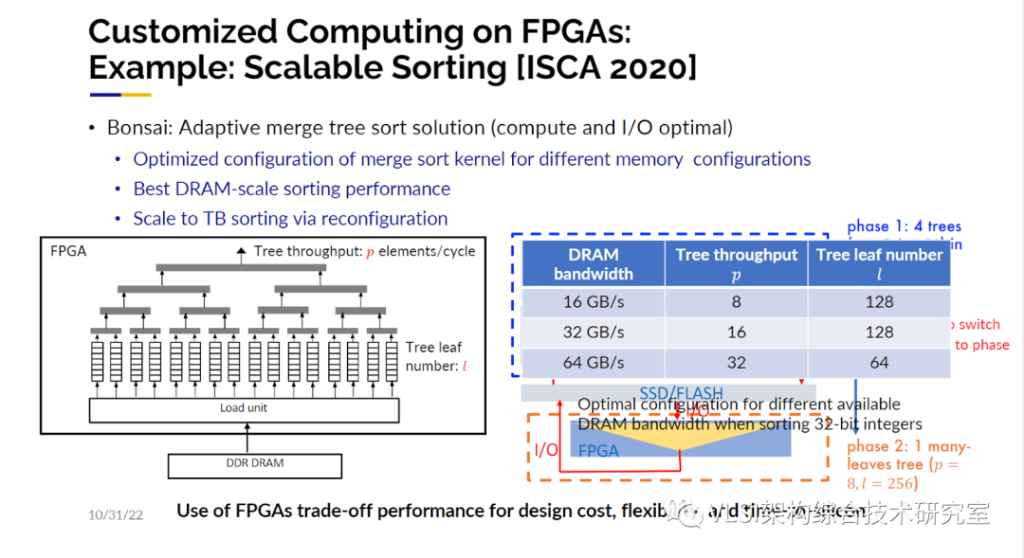
那么在硬件设计层面如何对这个排序算法做特定设计?设计的自由度在于有多少数字需要被处理,以及IO的带宽有多少?那么映射到这个归并排序的合并树就是你有多少的叶子结点以及每个节点的吞吐量有多大?做ASIC对这两项进行专门设计就比较有难度,我们可以做到的是,如果你告诉我需要排序1T字节的数据、100字节记录实现原地归并排序我们就可以给你定制一个最优化的归并树。定制化的归并树设计好之后当你实际去跑这个排序时你会发现1T字节的数据可能装不进内存里,那又该怎么做呢?最好的解决方案是在以内存的容量为块的大小在内存里排序,比如说你有256G的内存那么你就排序256G大小的数。那么归并就会发生在硬盘比如SSD里。SSD和内存比带宽小了很多,所以从DRAM的排序到SSD的归并的数据转移我们可以在线重构FPGA来重新产生一个电路专门解决这个问题,这也是ASIC做不到的。这样的定制化重构电路仅需要花费1秒钟,整体的1T字节排序总共花费200秒。相比于现有的CPU、GPU或者其他替代方案,我们的方案可以得到最优的性能和最高的吞吐量。这项工作传达的一个信息就是,FPGA可以在设计的开销、性能和吞吐量之间给出一个较好的权衡考量。
我很欣赏斯坦福大学Bill Dally教授写的一篇文章《Domain-Specific Hardware Acclerators》。这篇文章总结了可定制计算的优势,并且阐述了一些得到高效的可定制设计的关键。第一点在于使用特殊的数据类型。比如说AI的推断通常使用8比特数据类型。我们曾经实现了基因测序的加速。在这个应用中一般会有四种含氮碱基ATCG。我们用2比特的数据类型就可以表达这四种碱基。这可能会带来10-1000倍的效率提升。第二点在于使用大规模并行计算。比如说在计算矩阵乘法时利用脉动阵列(Systolic Array)架构,其每一个处理单元都可以处理数据。这种处理不是简单的16路并行而是几千路并行。这可以带来极大的性能提升。第三点是优化存储。不需要使用标准的L1/L2/L3缓存架构。数据就放在优化好的内存里,需要时取出就好了。这为高吞吐量低能耗的可定制计算提供了可能。第四点降低或者平摊额外的处理器开销。在一般的芯片上做一个加法需要先获取指令,解码,然后获取操作数,再根据其他指令的执行情况安排执行这条加法指令。实际上定制化计算做加法你只要拿到这两个操作数用加法器加起来就可以了。其他的操作都是额外的处理器开销。这种简化的指令执行可以带来10000倍的效率提升。第五点是定制化计算不使用标准的处理器,既可以根据算法来设计芯片架构,也可以根据架构来考虑各类算法。这两者是在定制环节中是可以一起考虑的。这几点加起来,就可以提供和传统标准处理器相比几个数量级的性能和效率的提升。当然ASIC也有和以上相同的优势。
不过,我们之前提过ASIC的设计是一个昂贵又漫长的过程。使用FPGA虽然没有ASIC的性能提升那么高,但是和一般处理器比性能的提升也是相当显著的。同时FPGA的设计周期极短,在需要时可以快速重构,成本和ASIC比大大减小的优势,使我们觉得FPGA是让大多数人可以体验到可定制计算优势的首选方案。现在我希望已经让大家相信:让软件工程师为自己的应用设计一款定制化加速器是一件重要而有趣的事情。那现阶段软件工程师可以很容易地设计出专属的定制化加速器吗?可能这个问题太宽泛了。很多软件工程师的工作范围可能触及不到对性能的考量,只要设计出的软件正常工作就可以。但实际上还有很多“认真的”软件工程师对程序的运行性能有着很高的要求。他们在写代码的时候可能会关注处理的数据能不能放进缓存里,是不是要改写一下循环做循环分块使得程序跑的更快。这些都是固定于现有架构基于软件层面的优化。我希望这一类的软件工程师更进一步不需要很多硬件知识能够很容易地设计出定制化加速器从来更好地提升性能提高效率。这是我们的目标。只要你懂如何在普通CPU的情况下优化软件代码,我可以让你很容易地设计出你想要的加速电路。我们可以把问题精确到现阶段这些“认真的”软件工程师身上,他们可以很容易地设计出专属的定制化加速器吗?当我一提到电路设计自动化,你可能会立刻想到高层次综合(High-level Synthesis)。这是我们20年前的工作。高层次综合可以将C/C++转变成LLVM中间代码。通过做各种代码变换、调度安排和片上资源分配就可以得到RTL电路。我们这项工作从一个普通的学术项目xPilot为起点,然后基于它我们创立了AutoESL公司,不断迭代xPilot变成AutoPilot。之后Xilinx收购了AutoESL,AutoPilot也变成了如今的Vivado HLS/Vitis HLS。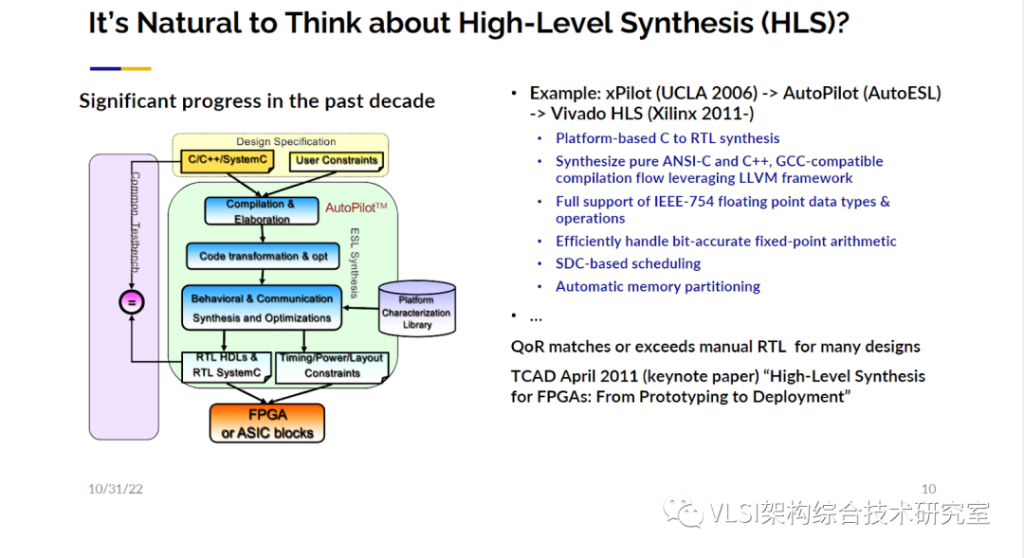
在收购之前Xilinx需要做完善的技术尽职调查。他们不仅自己在内部进行了测试,也雇佣了Berkerly Design Automation来进行第三方测试。测试的结果表明,高层次综合的结果(QoR)可以和手工设计的电路相媲美。IEEE TCAD将我们的最初验证结果作为主旨论文发表在其2011年4月刊上。你可以在这篇文章里看见参照设计和高层次综合生成设计的对比结果。高层次综合确实是个好消息。利用高层次综合可以很轻松的将C/C++程序转换成电路。比如说下面这个Polybench的例子。这个例子中有两个做矩阵乘法的循环。使用高层次综合,你按一下按钮就可以得到一个FPGA的设计,这条路已经完全自动化了。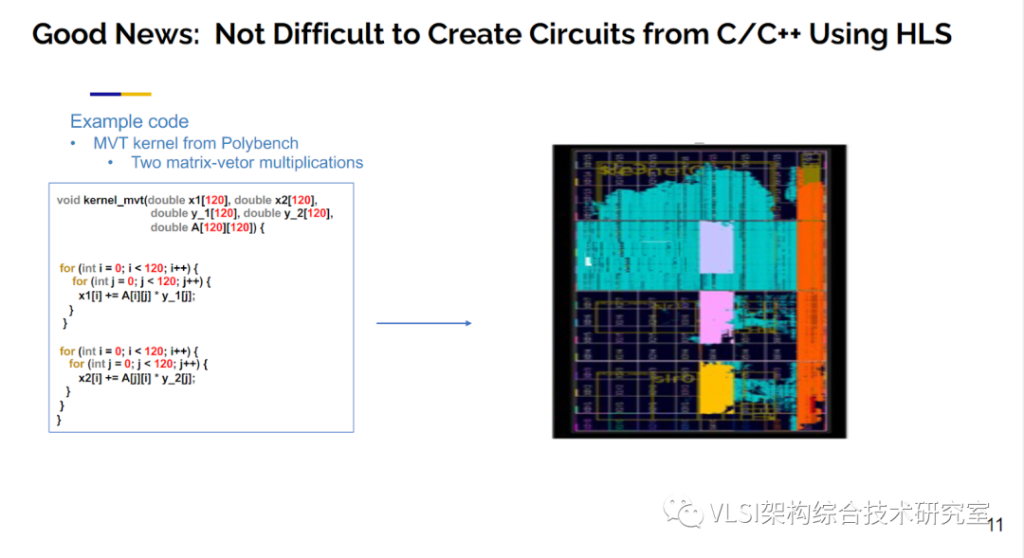
然而,这并不是故事的终点,不然我今天的主题报告到这里就结束了。实际上你会还会遇到以下几个挑战。第一个挑战在于,当你原原本本地将软件代码放进高层次综合工具,点完成按钮测试了一下性能,发现这个电路比单线程CPU慢了13倍。那设计这样一个比CPU还要慢的加速器又有什么意义呢?顺带一提,CPU一般的运行频率是2-4GHz,而FPGA的频率是300-500MHz。这样的性能差别其实很常见。在座的各位如果写过并行程序如OpenMP的话,会发现你写的第一个程序在16核CPU上并不会提高16倍的效率,甚至你可能几乎看不见有任何性能提升。你要做的事情是去做运行时间分析(profiling)。然后你会发现你需要给程序添加一些prgama来指明哪段代码可以并行执行,哪些需要做规约(reduction)等等。高层次综合工具也提供了类似的pragma写法。在下图的例子里,我们就对两个循环添加了pipeline, parallel和parallel with reduction三种pragma。我们回过头来再看加了pragma的代码产生的RTL发现性能提高了120倍。顺带一提这些pragma和Vitis_HLS的pragma略有不同。我们使用了Merlin编译器来产生这些电路。Merlin是我们另外一家公司峰科计算(Falcon Computing)的产品。Xlinx在两年前收购了峰科之后也将Merlin编译器开源供各位试用。
开源地址:https://github.com/Xilinx/merlin-compilerMerlin编译器的好处在于它自动实现了一般高层次综合手写才能做的很多代码优化,需要额外添加的pragma数量和一般高层次综合相比大大减少。你们可以看见这个例子只用3个pragma就可以了。Merlin的pragma只有简单的pipeline, parallel和tiling三种。总的来说我们想告诉大家的是软件代码需要添加合适的pragma来产生高性能的RTL电路。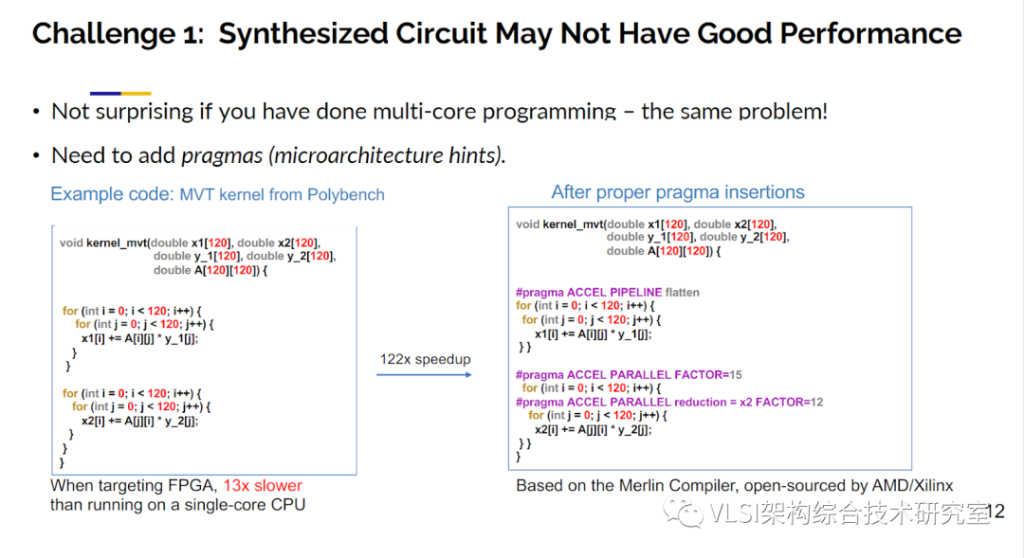
现在你说,好,如果我添加三个pragma就可以产生120倍性能提升的电路,那么我怎么知道在哪里添加什么pragma呢?以Merlin编译器为例子,我们已经知道Merlin只有pipeline、parallel和tiling三种pragma,你可能需要在每个循环上把这三种pragma以及对应不同的参数都试一遍。就算你的程序很简单只有四五个循环,这样的求解空间都是指数级。对于我们图示的简单例子可能就有超过三百万种设置,一个个手工穷举并不是一件合理的事情。那我们怎么来解决这个挑战呢?
下面我想介绍一下为了解决这个挑战我们做的几方面工作。为了民主化可定制计算:即让大家都可以用!我们希望不仅是C/C++语言能用来设计电路,更上层的语言或工具比如TensorFlow、Halide、Spark等都可以用来描述和设计电路。然后对这些更高层次的语言有一些通用的中间表示层如HeteroCL/MLIR。
第一个角度我称之为架构导向优化(Architecture Guided Optimization)。如果我知道某些特定的架构模板对特定的应用有很大优势那么我就使用这些特定模板。这样的例子包括脉动阵列(Systolic Array, DAC‘17)和模板计算(Stencil, ICCAD’18)。还有一类新的架构我们称之为可组合可并行可流水架构(CPP, DAC’18)。第二个角度,我们的初步研究相信利用机器学习或者深度学习来进行优化设计是有可能的,我们之后会提到相关的工作。第三点基于上述两个角度,我们希望可以把各种加速器快速地组合在一起,我们也有一些相应的工作。我们的目标是使得软件工程师可以在他们熟悉的高层次语言描述上可以一路到底畅通无阻的生成他们需要的高性能加速器。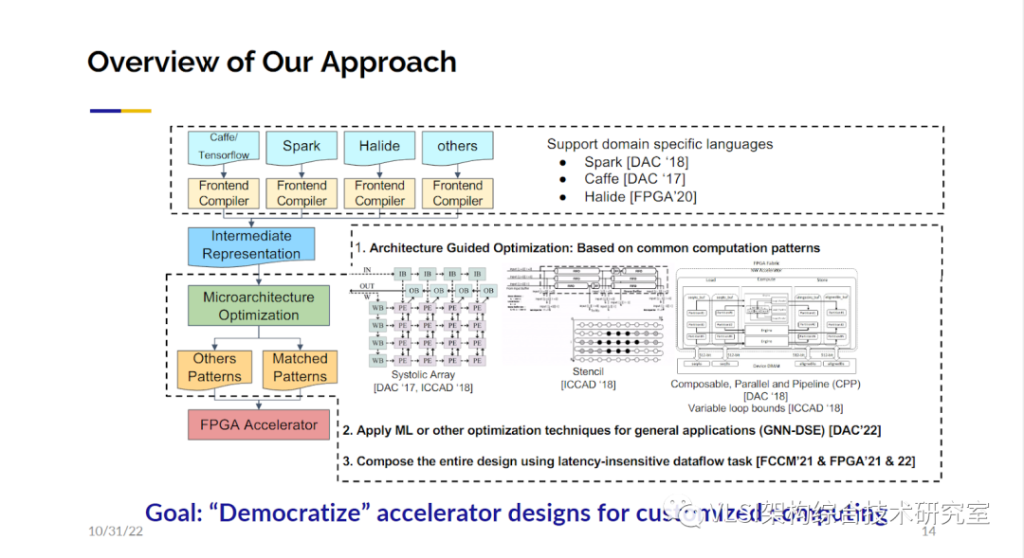
我们的工作的其中一个例子是AutoSA。这项工作主要是深度学习的高层次代码核(Kernel)映射到脉动阵列上。脉动阵列在上世纪70年代由H. T. Kung教授和Charles Leiserson教授提出并给出了形式化的定义。大概的意思是数值的计算是可以像心跳一样舒张收缩脉动化的,比如在3x3矩阵相乘时,行列向量之间错拍输入处理单元(PE),结果可以按节拍输出(译者记:行列输入分别在1,2,3拍进入,按列为单位输出分别在第3,4,5拍, 第4,5,6拍, 第5,6,7拍产生)。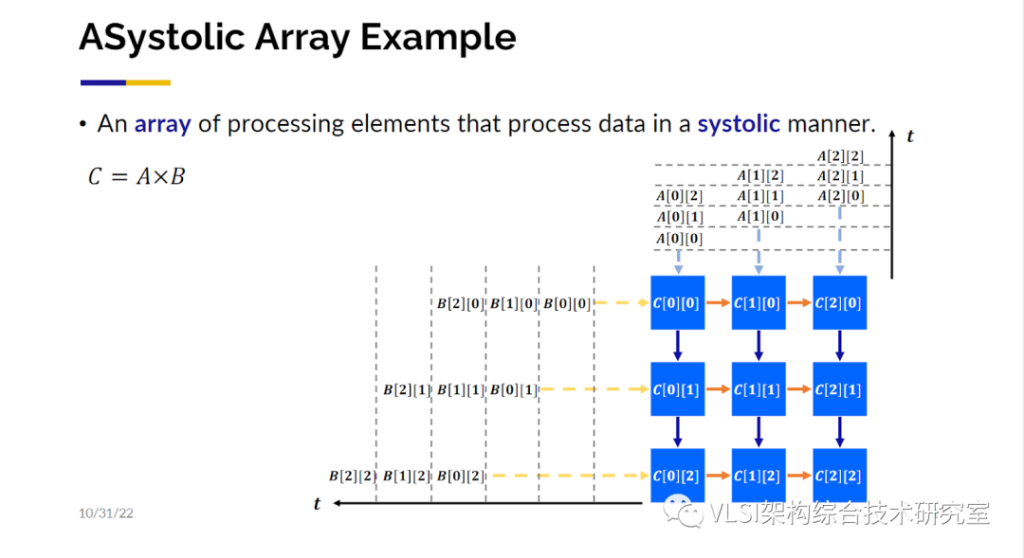
为什么我们对脉动阵列这么感兴趣呢。因为这里面包含了很多大型矩阵和大量的并行处理,这带来了性能提升。谷歌的TPU就是基于脉动阵列的架构进行设计的。脉动矩阵的另一个关注点在于局部临近计算,这优化了能耗。对传统芯片设计主要的性能影响指标并不是门的速度而是导线的速度。脉动阵列的布线只连接了相邻的处理单元。所以现在几乎所有的,包括谷歌、特斯拉和亚马逊的深度学习加速器都在基于脉动阵列来设计。虽然脉动阵列的原理很简单,然而要设计出一块好的脉动阵列加速器并不是一件容易的事情。下面这幅研发周期分析图来自英特尔,他们展示了从包括C、OpenCL、Verilog、SystemVerilog等语言开始到生成硬件电路的研发周期。其中红色高亮的三个设计使用到了脉动阵列。我们可以看到研发这样的电路少则4个月,多则18个月。设计出的可能只是一个性能还可以的电路,不是最终完全调优的电路。我们希望自动化这一步骤。实现自动化的挑战在哪里呢?挑战在于不仅仅可以设计出一个脉动阵列的电路,而且是根据不同参数自动设计出最优的或者接近于最优的电路。所以,我们提出了设计空间的概念。比如说你有输入数组的参数以及所有可能的脉动阵列参数等等,这些参数的笛卡尔积就构成了一个待求解的设计空间。我们的工作已经可以在这个求解空间内自动寻找最优解或者接近于最优的设计。接下来的工作我们又分成两大步骤,一个是计算管理,另一个是通信管理。对于计算管理,我们这里用一个三循环的矩阵乘法来展示一下工作原理。这里第一个需要考虑的问题就是时间-空间映射。对这三个循环,你需要决定哪几个循环可以映射到二维的空间域上同时计算,哪几个循环映射到一维时间维度上在处理器上进行常规的时间循环。解决这个问题我们使用了多面体模型(Polyhedral Model)来分析数据依赖,然后做一定程度上的穷举来缩小求解空间从而划出存在着最优解的子集。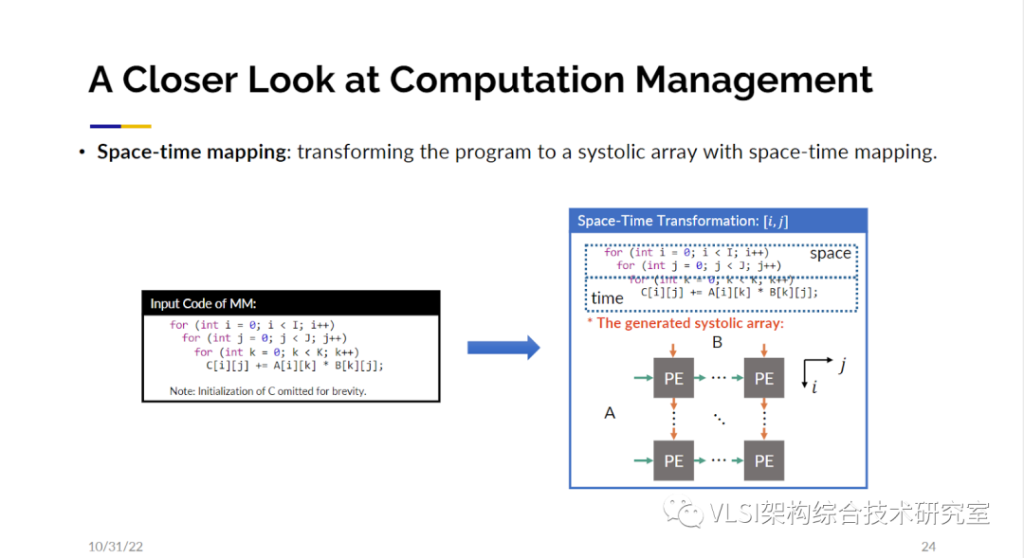
你的数据量可能特别大,比如说你需要处理10x24x24字节的数据,因为数据量大可能没有办法做到计算单元和每一个数据的对应。你可能需要创建多个小一点的数组作为替代,我们称之为数组分块(Array Partition)。见图中的实例,你可以把循环划分出一个个小块并在每一个小块上产生一个新的循环。这里我们会对产生多大的小块这一参数进行优化。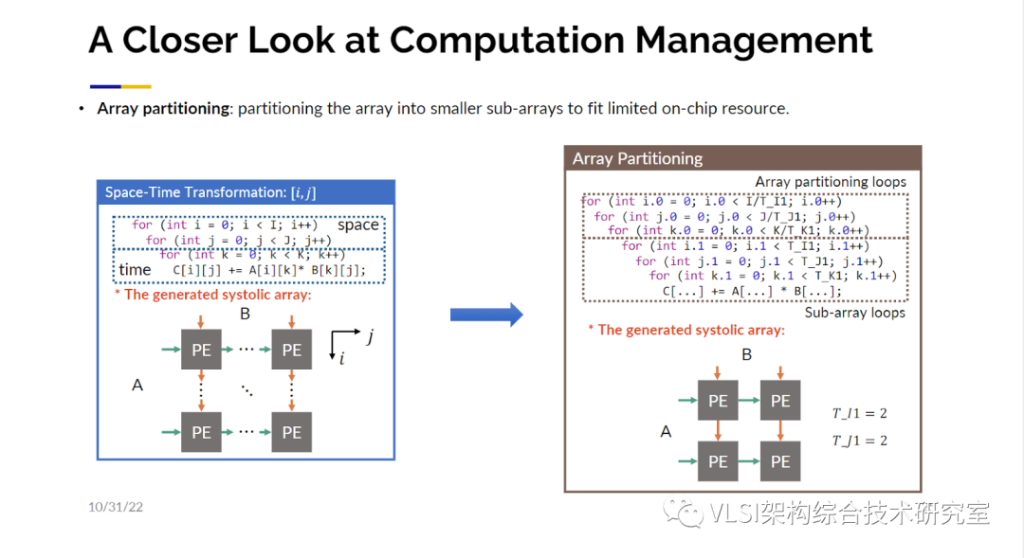
真正的电路并没有像当前时刻做计算然后传到右边的邻接节点然后在下一个时刻做新的计算这么简单。很多的运算比如说浮点数加乘需要花费好几个时钟周期。如果不做任何优化,相邻的处理单元可能需要等上5-10时钟周期才能得到数据。一个更好的方式是我先开始计算一部分数据,比如说要花8个时钟周期。接着我立刻在下一时钟周期对一块没有数据依赖的独立区域进行计算,这样每个时钟周期我都能给相邻的处理单元一些数据。这就意味着你可能需要额外再分离出一些循环来实现上述操作,我们称之为延时隐藏(Latency Hiding)。
最后你的脉动阵列处理单元不一定只能做一次加乘操作,这其中可以进行SIMD处理。你可以有一个向量来同时处理16个运算。这也会产生额外的循环我们称之为SIMD循环。以上就是我们在计算管理上几个角度的考量。这些考量合在一起就形成了一个大的自动化求解空间。你也可以看见因为空间很大,我们也需要花一些时间来找到最优或接近最优的脉动阵列电路设计。
到现在为止对数据计算管理就有这么多的选项,对数据传输通信呢?其实传输通信才是关键,因为你要保证数据只在相邻的处理单元之间传递而不是广播数据。我们通过做依赖分析来解决这个问题。你可以在这个矩阵乘法的例子中发现A和B矩阵各自都有读后读依赖(Read-after-Read dependency)。一般来说在CPU中我们对读后读依赖不是很看重,但在脉动阵列设计中这非常重要。接着我们发现操作中还有写后读的依赖(Read-after-Write dependency)因为C矩阵是在循环之间累加的。最后不同的数值会写在C矩阵不同的位置上。接着你就能得到下图中的这张表来发现哪一个I/O组有着怎样的数据依赖关系。
有了这张表你就可以知道如何构建网络架构。比如说根据你的依赖向量你发现依赖是沿着j轴的那你就可以沿着j轴传输数据流。同理,如果依赖沿着i轴那么就沿i轴传输数据流。这些分析都是通过多面体分析得来的,基于这个分析得出的传输网络,我可以保证是依赖正确,同时只有相邻处理单元有数据传输。当然所有计算完成之后数据会被读回去。我在这里不会详细展开这个分析,但是我很乐于分享相应的论文给大家参考。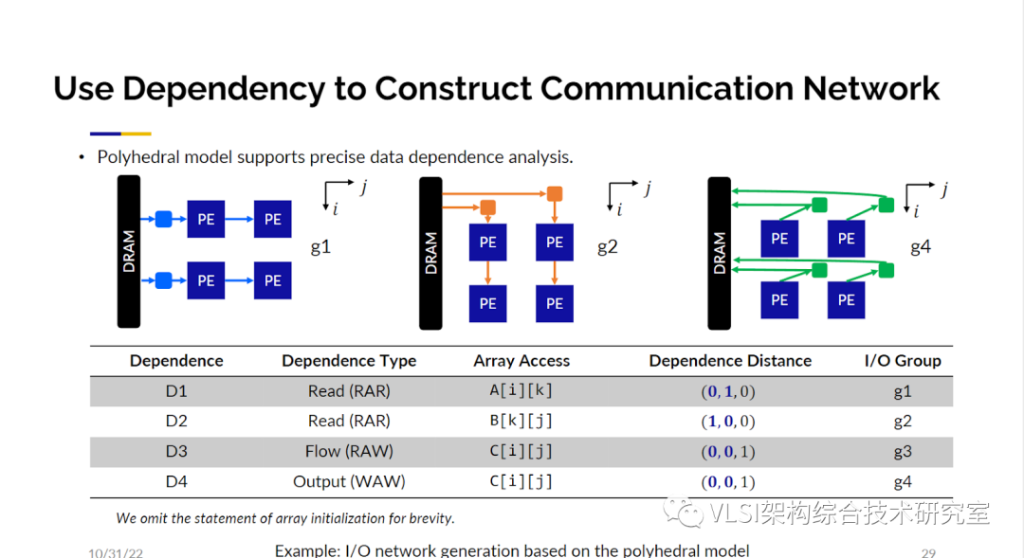
以上的步骤中有些参数是我们需要去调整的。其中很重要的是循环分块(loop tiling)的参数。你需要决定执行循环的数组的维度是多少。为了找到这个参数我们采取了一种混合方法。首先我们用一个数学优化求解器,然后我们做进化搜索,因为找到的参数可能存在无法整除的情况。我想强调的是之所以我称之为基于微架构的优化是因为一旦你定义好了微架构的模板我就可以根据这个架构来快速准确的估计设计电路的性能。这使得使用数学求解器成为了可能。我们目前已经将AutoSA开源。欢迎大家来试用这个工具,并给这个工具添加新的功能。
开源地址:https://github.com/UCLA-VAST/AutoSA我也可以告诉大家,当你拥有了这样的基于具体架构的空间求解器你可以得到一些令人惊讶的结果。其中一个新洞察是物理数组的大小应该是多少,这个大小一定需要是总体数据大小的因数吗?比如说总大小是1024,是不是只能去尝试2、4、8、16这样的因数作为物理数组的大小呢?实际上,有不少文章是基于这样的假设来做设计空间求解的。这些文章也发表在了顶级的期刊或会议上。但是我们证明了这条假设不是一定正确的。原因很简单,如下图所示如果一个4x32的设计是可以装进FPGA的,8x32则装不下,在这个设计里如果你用一些非因数参数(13x16)反而有更好的效果。这个矩阵乘法的例子我们可以很明确地告诉大家根据纯因数参数最好的设计参数为32x4x8(行,列,SIMD),但如果你选一些奇怪的数字比如说16x13x8我们甚至可以获得50%的性能提升,这是令人意想不到的。
另外一个惊人的洞察是很多人知道片外的存储转移是很重要的。不对此进行优化,很难得到最优化的设计。很多人说只要最小化存储转移的量,我应该就可以得到最优化的设计。当然也有一些文章是基于这样的假设。我们还是使用刚才的例子,如果你计算一下数据移动你会发现第二个设计有着更高的移动。这是一个高计算密度的应用所以计算量是很重要的,增加的数据移动保证了所有的计算单元都被有效利用了。
以上例子显示了有些工作如果你如果没有用到空间求解你可能就无法真正研究到这种设计细节。顺带一提,我们的工作不仅实现了对脉动阵列的优化,而且优化了一些模板计算(Stencil Computation)。这些模板计算也在数据管理和通信管理上做到了最优化。希望现在你可以相信脉动阵列我们可以做得很好。但是对于没有经典架构可以映射的一般程序,是否也可以做好呢?在这个问题上我们使用峰科计算开发的Merlin编译器来解决这个问题。我们将Merlin编译器设计成和OpenMP类似的使用方式。OpenMP是很多软件工程师开发多核CPU程序的应用程序接口。我们认为这样的设计可能是最贴近于软件工程师使用习惯的。在OpenMP里怎么让程序并行执行呢?和高层次综合类似,你用pragma来做这件事情。OpenMP的pragma以”omp parallel for”为前缀,你可以把它加在需要并行执行的循环之前并指定并行执行的参数。类似地在Merlin编译器里,我们使用”ACCEL”作为前缀,你可以对循环指定pipeline,parallel和tiling的操作并指定对应的优化参数。比如这里的例子我们就指定对循环做16路并行。Merlin编译器会自动执行很多的代码变换。这些变换包括将数据装入缓冲存储器(Buffer)、数组划分(Array Partition)、上位机代码生成等等。这些所有的步骤都是全自动的。对于软件工程师来说这非常容易上手。
基于Merlin编译器,我们所做的第一项工作叫自动设计空间求解(AutoDSE)。这项工作也获得了ACM TODAES 2023年度最佳论文奖。AutoDSE的工作原理类似一个专家系统。一般来说如何去设计一个加速电路呢?极大概率你会想从什么pragma也不加开始,当然有可能很幸运的,什么pragma不加就能用Merlin达到性能目标。从一个没有pragma的程序出发,你先会去看一下Merlin的输出报告。从报告上不仅可以看见总的时钟周期,也可以看见详细到每个循环的时钟周期分布以及资源使用情况。这样很明显你可以发现某几个嵌套循环占据了大量的延时。知道这一点之后你就会在相应的循环上添加pragma来提升性能。如此循环往复直到获得满意的设计。我称之为基于瓶颈指向的优化设计。AutoDSE可以通过空间求解自动产生pragma及其参数,并调用Merlin编译器实现了自动化求解。然而AutoDSE有一个限制在于,对于每次迭代求解我都必须运行高层次综合以了解性能。一次执行可能需要10分钟,有时20分钟,有时30分钟,所以一天之内你很难经历很大量多次迭代,也许最多20-40次。一个设计求解空间中可能有数百万个点,因此我们认为这可能是深度学习可以提供帮助的地方:我们想要提出一个模型,可以给我们正确的性能预测。如果机器学习可以成为最好的国际象棋棋手,也许它也可以成为即将到来的最好的电路设计师。我们实际上研究发现这比下棋要困难得多。因为围棋虽然是相当具有挑战性的大棋盘,但它的规则是固定的。但是加速器电路设计,例如编写算法,都是开放式的没有固定的规则。你只受你的创造力的限制,所以这是一个更加难的问题。我们的第一个目标是给程序和pragma准确预测性能,这样我就可以在设计空间里快速迭代。对于AlphaGo的设计师来说最激动人心的时刻还在于,一旦你拥有了棋盘,你就拥有了黑色棋子、白色棋子和规则。一旦他们看见棋盘的局势他们就可以产生对应的评分函数进行预测,这是他们可以进行机器学习的关键。我们也想做同样的事情,当我看到程序员的程序时,我也想建立一个评分函数对其进行性能评估。另一个问题是我该如何预处理这些带pragma的程序,你是把它当作一串字符向量、自然语言还是别的什么量化表示。事实上,我发现程序与自然语言非常不同,因为当我在这里说话时,有很多的冗余词,你可以跳过也许五个词你仍然可以知道我在说什么。但是对于一个程序它敏感到如果你放错了分号,你会得到一个非常不同的结果。所以对于程序直接使用自然语言处理并不是一个很好的方式。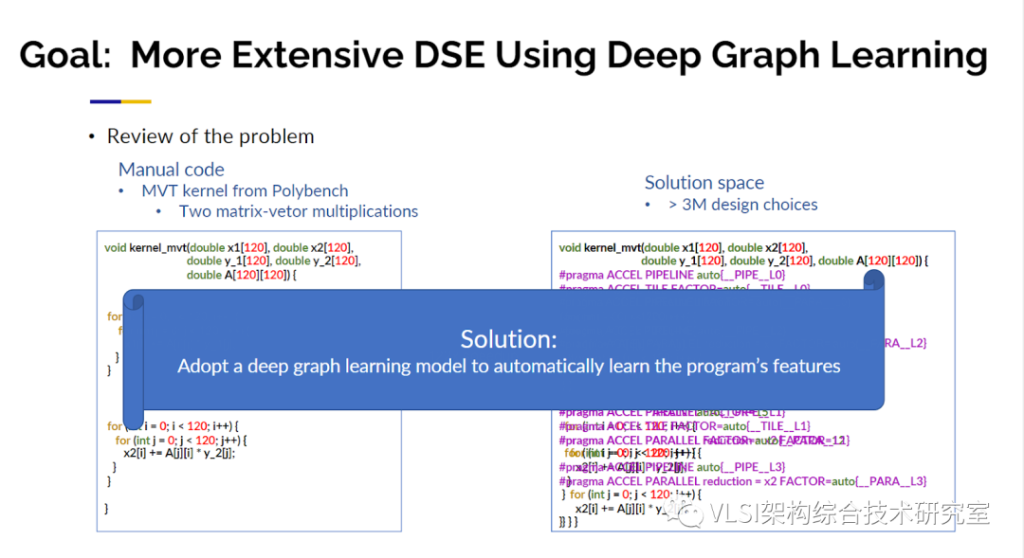
我们在这里想解的决问题依然是希望能够自动插入pragma。然后我们快速地搜索这个求解空间。我们要做的第一件事情是创建训练样本。这个时候AutoDSE就可以发挥巨大的作用,原因是AutoDSE的求解过程中会产生大量的中间设计结果,我们不仅保留了这些电路的性能指标也保存了这些对应的电路设计。这些AutoDSE生成的样本电路可以作为我们的训练样本,不仅是因为我们进行了针对瓶颈的优化使得这些中间设计仍然是有意义的,尽管它不是最优的。而且我们对有些电路也做了一些扰动使得我们生成的训练样本包括好的和坏的设计。我们通过这样的方式创建包含有几千个程序的训练样本数据库。我也希望您可以与我们合作,也许在更大的社区范围内我们可以制作一个更多更大的样本数据库。图神经网络有很多令人兴奋的进展。事实上,我注意到在我的主题报告之后有一个关于图神经网络的研讨会。我认为这非常及时。我们将把图编码成多维向量或者多个多维向量的嵌入(Embedding)。在编码成向量之前我们需要考虑节点的注意力机制(Attention)、知识跳跃(Jumping knowledge)等等很多因素。有了这个图的嵌入编码,就可以作为高维神经网络的输入层,然后把对应的性能指标作为训练标签进行训练了。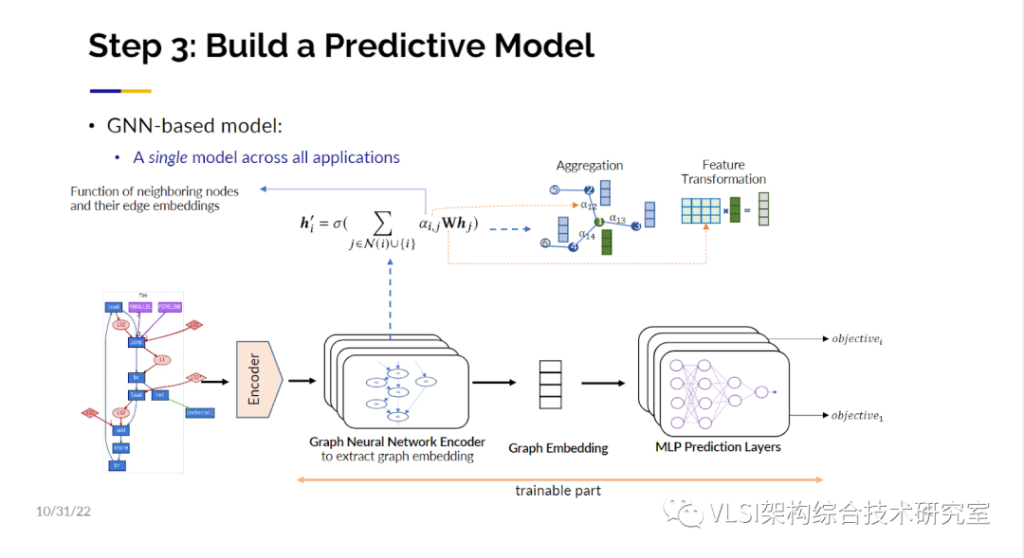
这样的做法和纯用AutoDSE相比就快多了。我也不必运行高层次综合就可以做设计空间求解。我们在第一个版本中选择最好的M个设计,然后对M个设计再进行高级综合来作为新的训练数据集。但这还不是故事的结束。对于和训练集完全不一样设计使用图神经网络我们还是有一些挣扎的。这些测试样本对于训练来说属于域外分布。所以这就是我们想要利用迁移学习(Transfer Learning)的地方(GNN-DSE-MAML)。大概的做法是如果你给我一些全新的东西,我要建立一个模型,我必须运行在一些样本上运行几次真正的高层次综合,然后我更新我的模型而不是直接使用已有数据进行探索。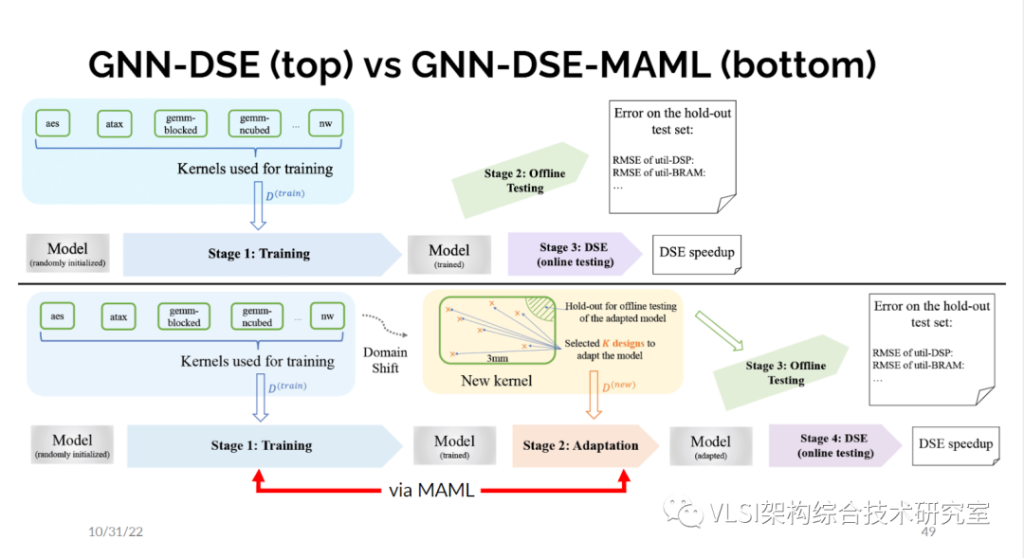
我们这个方法的灵感来源于机器学习中K样本学习(K-shot learning)的概念。用早期的分类工具我可以从一百万张图像中学会如何区分一千个类别的狗和猫或其他物件。那现在如果我给你一种新动物比如说骆驼,你从来没有见过你能认出吗?显然必须教你一些东西,但也许只要有两三个骆驼的照片你就可以知道这是骆驼,你以后可以一直分辨出来。如何来做这件事情?基本上你将会有一些动物,每一种都有一些例子。每一个新动物都称为一项任务,你希望在所有这些任务上都做好。每个任务的样本数很少,你也想要在这些任务之间做好区分。数学上发生的事情是你迭代所有这些任务,你进行梯度下降,每个任务都会给你一个新的梯度,然后你做某种加权平均然后你取得了训练进展。在推理时,当你看到一个新任务,基本上是一种新动物或在我们的情况是一个新程序,然后你会先运行几张图,找到现有最小化误差,所以给你另一个梯度,然后你从这个梯度出发来更新现有的模型。
这是我们做自适应的方法。利用这个方法我们得到了鲁棒性更好的结果。这个结果是比直接微调更好的。我会说我们还是有优化的空间,尤其是在资源管理部分。因为在某些情况下我们得到了很好的结果,但它已经超出了我们拥有的资源,所以我们必须更精确地处理这些情况。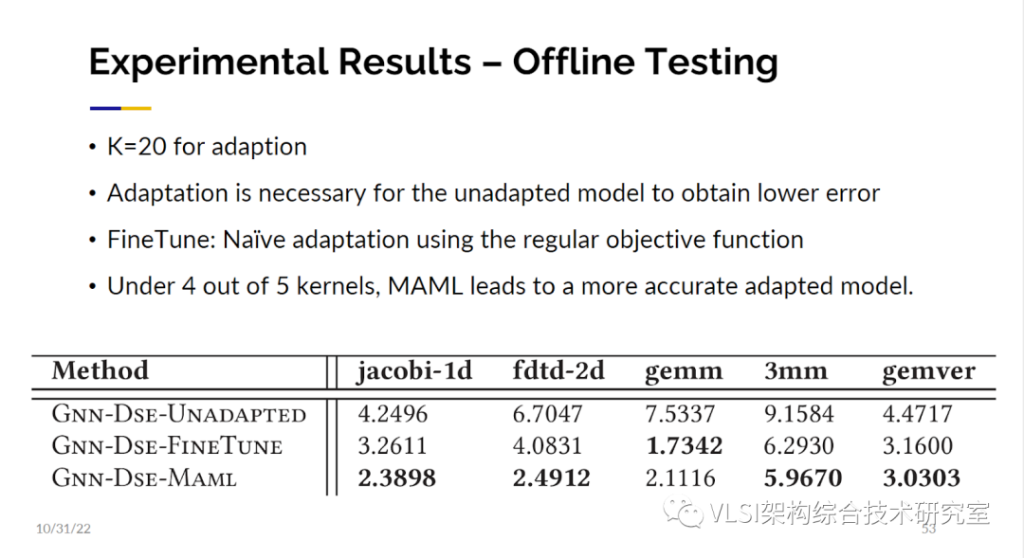
AutoDSE(https://github.com/UCLA-VAST/AutoDSE)和GNN DSE(https://github.com/UCLA-VAST/GNN-DSE)都是开源的,所以如果您有兴趣在这个方向继续研究,欢迎您下载试用。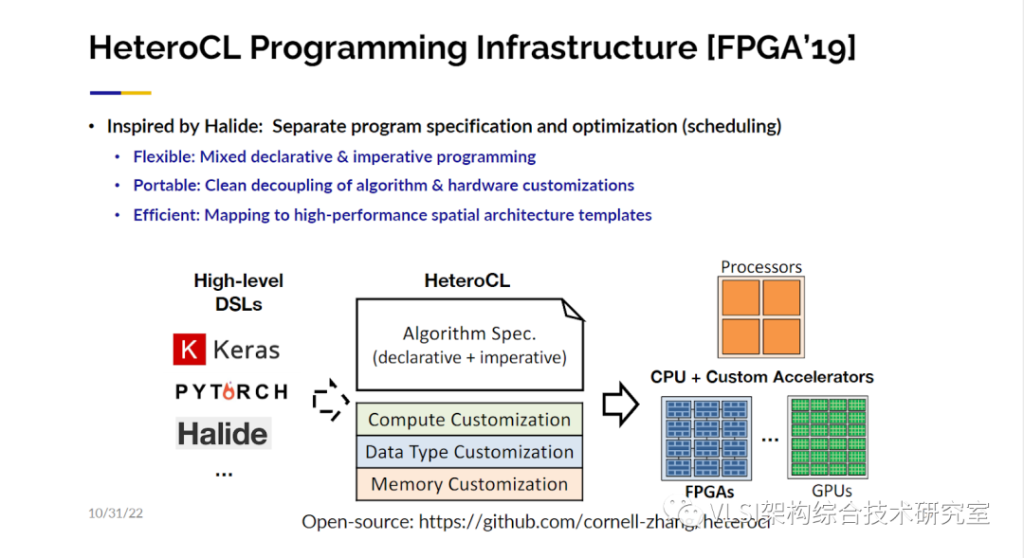
HeteroCL这项工作非常成功,我们将其硬件优化部分扩展到我们的加速器设计。在这里我们主要有三种优化方式。第一种是特定计算的定义。比如我们可以来定义一个循环的展开。第二种是自定义数据类型。你可以很容易地尝试从2bit到16bit,看看你的输出结果是什么样子。我们也可以指定如何复用数据。
接下来我们很快意识到,在硬件优化的定义区块中,我们可以给用户使用微架构的设计自由。比如说其中某些计算可以使用脉动阵列,某些计算可以使用模板计算。这些都是设计模式,和真正的硬件指标比如FPGA中的BRAM或者URAM的使用毫不相关。软件设计师可以很容易地和他们平常写设计一样指定这些模式。其他指定不了的步骤我们将通过自动合成、AutoDSE和机器学习等等技术帮助他们自动完成。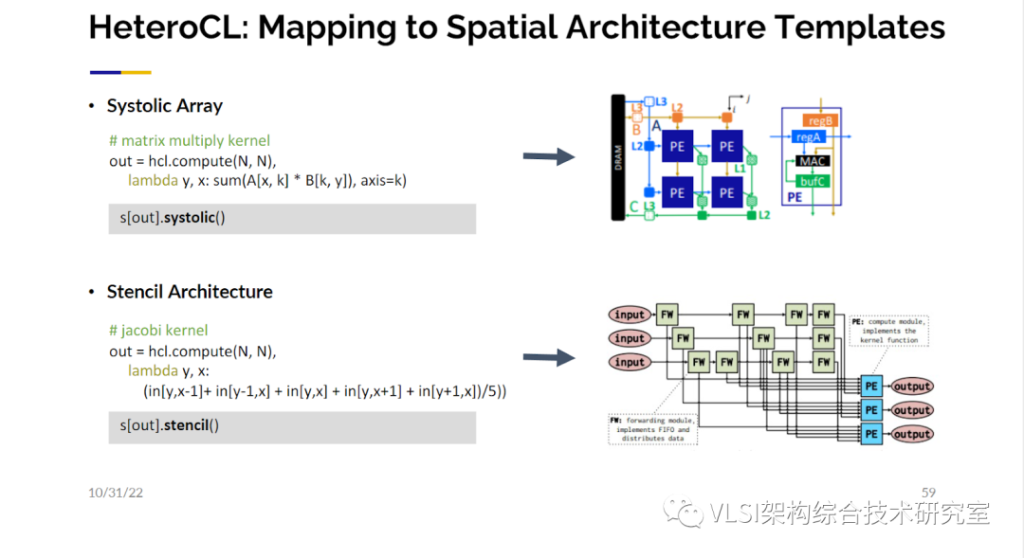
最后,在我的主旨报告结束之前,我想再谈一个问题:即如何将所有东西搭建在一起?对于一些真正从事FPGA设计的人来说,当你把所有东西放在一起时,性能可能从大约300MHz降至100MHz。而且还需要非常长的时间生成比特流。20小时并不夸张,40小时完全合理。顺便说一句,你不必因为设计错了什么而感到难过,只是大型的FPGA非常复杂。你可能注意到了一个大的FPGA往往有四个大片(die)而不是一个。如果你的设计出现了跨片的情况整个电路的延时可能一下子就从几纳秒涨到几十纳秒。而且大型FPGA中还有很多IP核在那里阻碍了很多布局布线。比如说你有DDR、控制器在中间,然后你有PCIe控制器在最后与CPU通信。最新的FPGA有32个通道的HBM。那么如何连接到你需要的数据你需要创建一个大的交叉通信模块,这也会牺牲芯片的性能。有了以上原因,你的FPGA实际表现很差并不是一件奇怪的事情。HLS对这一点的考虑也是有限的。你在编写代码和插入pragma时不知道在实际布局布线中你会在哪里出现跨片,在哪里会遇到哪些IP块。我们的解决方法实际上很简单。如果你有一根高延时长线我可以通过增加流水线级数来解决这个问题。所以问题转变为这些长线在哪里。这就是我们要先做布局的地方,这是一个粗略等级的布局。然后利用这个粗略的布局信息作为约束条件来指导全局的优化。从高层次综合开始实际上是理想的,因为我基于一种抽象表示做调度比较自由。如果我需要两个额外的时钟周期我可以将其添加到我的调度解决方案中。这个方法也是比较成功的。现在我们在超过43种设计中看到几乎是2倍的时钟周期提升,从150MHz到 297MHz。我可以告诉你,每一个我实验室的项目都在使用Autobridge进行FPGA辅助设计, 因为学生自然而然能获得2倍的性能提升。这项工作获得了 FPGA’2021的最佳论文奖。如果你对此感兴趣,欢迎与你的团队分享这项工作。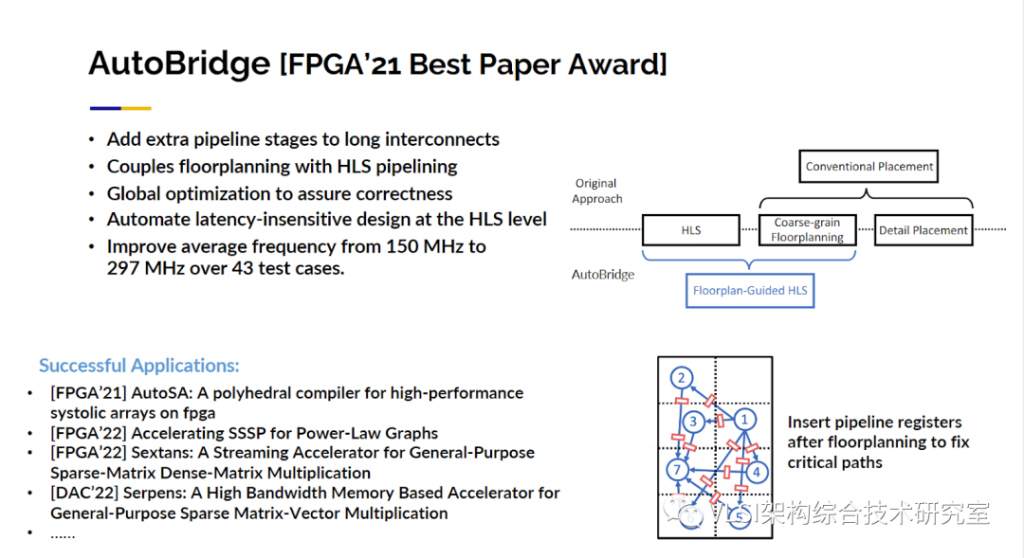
不仅如此,我可以继续向你展示关于脉动阵列的设计讨论。从12 x 12阵列开始到24 x 24阵列时,在传统情况下你会发现性能下降,频率从300MHz开始降至150MHz或120MHz,但用AutoBridge优化后,我们的运行频率基本上保持不变。所以你可以看到图中的布局布线图是一个很神秘的部分,左边的图中布局布线工具看起来似乎做得很好,他们将所有东西都包装在尽可能少的片中,但是他们造成大量布线拥堵(Congestion)。我们可以放心地将其分离出来,然后我们将流水线寄存器按需插入设计。
这些我称之为延迟激励设计技术,因为你可以容忍比较长的延迟,也可以帮助我们改善布局布线。如果你运行Xilinx工具,你发现它太慢了要40小时,你分析一下CPU使用情况发现你只使用了四个核。你说我有32个核,为什么不使用32个核?因为你无法并行优化各个电路,因为片与片之间存在全局互连。使用这种方法,我们在边界添加触发器,因此每个触发器完全解耦了片间连接,以便我们可以并行运用它们。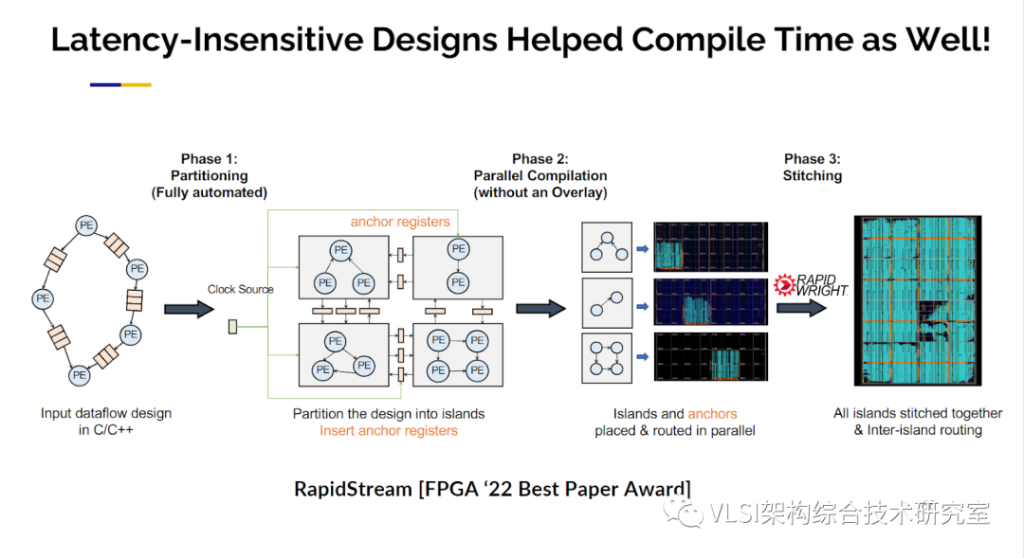
这种技术实际上也可以带来惊人的结果。我们获得5到10 倍编译综合运行速度的提升,我们还获得了30%频率提升。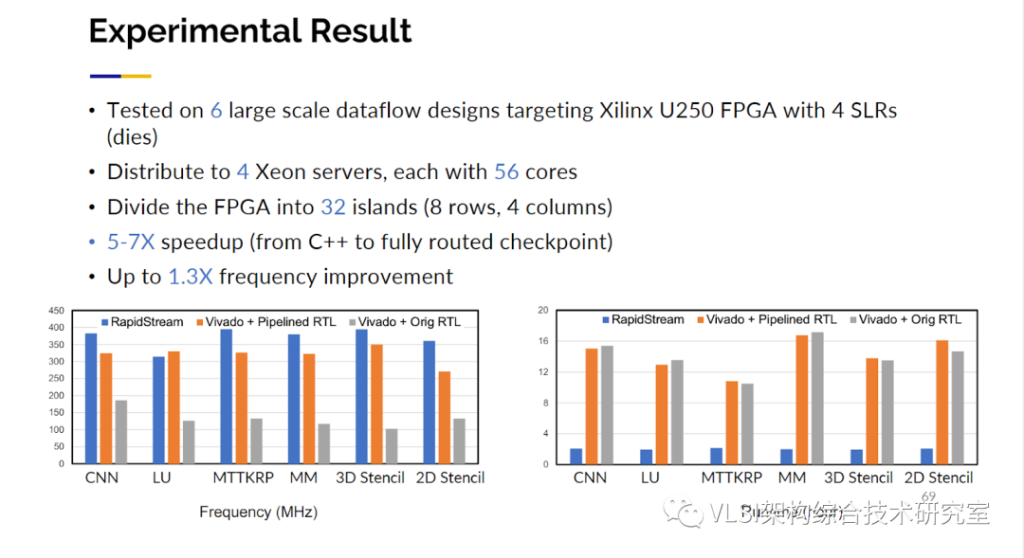
我们还有一个扩展,被称为TAPA的HLS。基本上我们添加一些模板IO来描述这些数据。从那里进行流程设计,我们可以利用之前提到的技术自动进行延迟激励优化。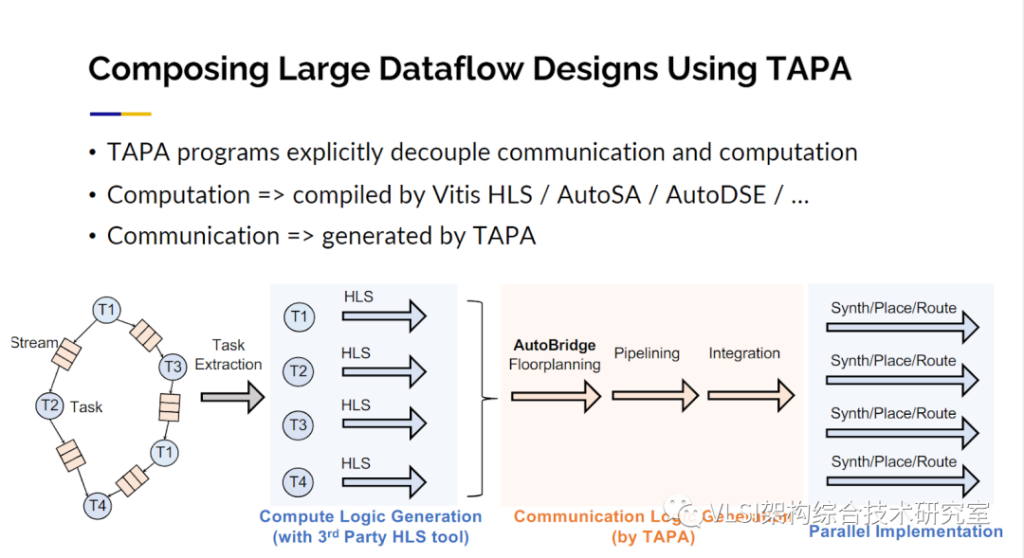
我们使用TAPA设计了一个FlexCNN。它共计有14000行代码,这一切都使用了延迟激励设计。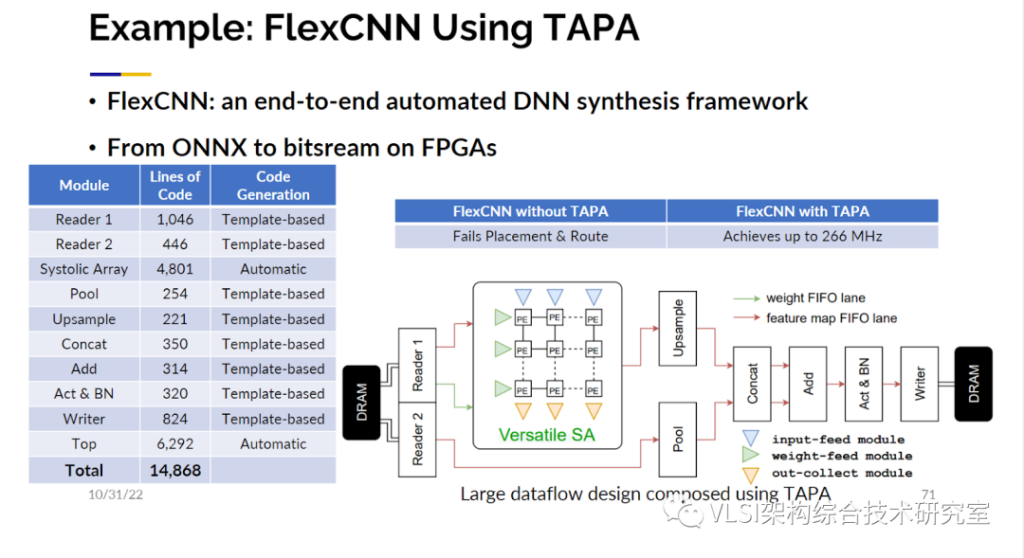
最后总结一下,我知道民主化可定制计算这个方向存在的时间很短,但对在这个方向上所取得的进展,我倍感鼓舞。也许我有些偏爱,在报告中我选择了更多来自我的实验室所做的研究,但实际上这个领域有着一群共同努力的优秀学者。这确实需要整个社区的共同努力,这就是为什么我们对工具开源这件事情如此强调。我希望聆听或者是阅读我报告的人,能够在这个领域继续添砖加瓦。工业界也正在朝着开源这个方向发展,并且会更加开放,例如英特尔有一个可定制计算API 是开源的。同时在我们的鼓励下,AMD-Xilinx在收购峰科计算之后也开源了Merlin编译器。我们对使用MLIR作为加速器设计的也越来越感兴趣。你们很多人可能都听过Hennessy教授和Patterson教授在他们的图灵奖演讲中的一句话:“这是一个计算机架构的黄金时代”。因为以前你只有微处理器、控制器等一些很少类型的东西可以设计。现在有了所有这些加速器的设计,实际上产生了无限的机会。开源软件生态:
AutoSA: https://github.com/UCLA-VAST/AutoSA
Stencil: https://github.com/UCLA-VAST/soda
Merlin Compiler:
https://github.com/Xilinx/merlin-compiler
AutoDSE: https://github.com/UCLA-VAST/AutoDSE
GNN-DSE: https://github.com/UCLA-VAST/GNN-DSE
HeteroCL: https://github.com/cornell-zhang/heterocl
AutoBridge:
https://github.com/UCLA-VAST/AutoBridge
TAPA: https://github.com/UCLA-VAST/tapa
FlexCNN with TAPA:
https://github.com/UCLA-VAST/FlexCNN
参考链接:
[1]主旨报告演讲视频:
https://www.youtube.com/watch?v=qlqjymTcLdI
[2]主旨报告幻灯片:
https://ucla.box.com/s/8yx0m0v1wtobn0io87jg4xh4sw0fculp
[3]Wang, Jie, Licheng Guo, and Jason Cong. "AutoSA: A polyhedral compiler for high-performance systolic arrays on FPGA." The 2021 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays. 2021.
[4]Chi, Yuze, and Jason Cong. "Exploiting computation reuse for stencil accelerators." 2020 57th ACM/IEEE Design Automation Conference (DAC). IEEE, 2020.
[5]Chi, Yuze, Jason Cong, Peng Wei, and Peipei Zhou. "SODA: Stencil with optimized dataflow architecture." In 2018 IEEE/ACM International Conference on Computer-Aided Design (ICCAD), pp. 1-8. IEEE, 2018.
[6]Cong, Jason, Muhuan Huang, Peichen Pan, Yuxin Wang, and Peng Zhang. "Source-to-source optimization for HLS." FPGAs for Software Programmers (2016): 137-163.
[7]Wei, Xuechao, Cody Hao Yu, Peng Zhang, Youxiang Chen, Yuxin Wang, Han Hu, Yun Liang, and Jason Cong. "Automated systolic array architecture synthesis for high throughput CNN inference on FPGAs." In Proceedings of the 54th Annual Design Automation Conference 2017, pp. 1-6. 2017.
[8]Sohrabizadeh, Atefeh, Cody Hao Yu, Min Gao, and Jason Cong. "AutoDSE: Enabling software programmers to design efficient FPGA accelerators." ACM Transactions on Design Automation of Electronic Systems (TODAES) 27, no. 4 (2022): 1-27. (ACM TODAES best paper award)
[9]Sohrabizadeh, Atefeh, Yunsheng Bai, Yizhou Sun, and Jason Cong. "Automated accelerator optimization aided by graph neural networks." In Proceedings of the 59th ACM/IEEE Design Automation Conference, pp. 55-60. 2022.
[10]Lai, Yi-Hsiang, Yuze Chi, Yuwei Hu, Jie Wang, Cody Hao Yu, Yuan Zhou, Jason Cong, and Zhiru Zhang. "HeteroCL: A multi-paradigm programming infrastructure for software-defined reconfigurable computing." In Proceedings of the 2019 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, pp. 242-251. 2019. (Best paper award candidate)
[11]Pal, Debjit, Yi-Hsiang Lai, Shaojie Xiang, Niansong Zhang, Hongzheng Chen, Jeremy Casas, Pasquale Cocchini et al. "Accelerator design with decoupled hardware customizations: benefits and challenges." In Proceedings of the 59th ACM/IEEE Design Automation Conference, pp. 1351-1354. 2022.
[12]Guo, Licheng, Yuze Chi, Jie Wang, Jason Lau, Weikang Qiao, Ecenur Ustun, Zhiru Zhang, and Jason Cong. "AutoBridge: Coupling coarse-grained floorplanning and pipelining for high-frequency HLS design on multi-die FPGAs." In The 2021 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, pp. 81-92. 2021. (Best paper award)
[13]Chi, Yuze, Licheng Guo, Jason Lau, Young-kyu Choi, Jie Wang, and Jason Cong. "Extending high-level synthesis for task-parallel programs." In 2021 IEEE 29th Annual International Symposium on Field-Programmable Custom Computing Machines (FCCM), pp. 204-213. IEEE, 2021.
[14]Basalama, Suhail, Atefeh Sohrabizadeh, Jie Wang, Licheng Guo, and Jason Cong. "FlexCNN: An End-to-End Framework for Composing CNN Accelerators on FPGA." ACM Transactions on Reconfigurable Technology and Systems 16, no. 2 (2023): 1-32.
[15]Sohrabizadeh, Atefeh, Jie Wang, and Jason Cong. "End-to-end optimization of deep learning applications." In Proceedings of the 2020 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, pp. 133-139. 2020.