使用生成对抗网络(GAN)进行图像超分辨率(SR)已经在恢复逼真细节方面取得了巨大成功。然而,众所周知,基于 GAN 的 SR 模型会产生令人难以接受的伪影,特别是在实际场景中。以往的研究通常在训练阶段通过额外的损失惩罚来抑制瑕疵,但这些方法只适用于训练过程中生成的同分布下的瑕疵类型。而当这些方法应用于真实世界场景中时,我们观察到这些方法在推理过程中仍然会产生明显的瑕疵。针对此,来自腾讯 ARC Lab,XPixel 团队和澳门大学的研究者们提出了 DeSRA 的新方法并发表论文。它能够对在推理阶段中产生的超分瑕疵进行检测并消除。该论文被 ICML 2023 所接收。- 论文链接:https://arxiv.org/abs/2307.02457
- 代码链接:https://github.com/TencentARC/DeSRA
“GAN 训练时出现的瑕疵” 与 “GAN 推理时出现的瑕疵”基于 GAN 的方法在生成带有纹理的逼真复原结果方面取得了巨大成功。BSRGAN [1] 和 Real-ESRGAN [2] 将基于 GAN 的模型扩展到了真实场景应用,展示了它们恢复真实世界图像纹理的能力。然而, GAN-SR 方法经常会生成令人视觉上难以接受的伪影,严重影响用户体验。这个问题在真实世界场景中更加严重,因为低分辨率图像的退化是未知且复杂的。第一列:低清输入;第二列:现有超分方法引起瑕疵;第三列:DeSRA 检测出瑕疵区域;第四列:DeSRA 去除瑕疵
为了缓解瑕疵的生成,LDL [3] 通过分析纹理类型,计算每个像素是瑕疵的概率,并在训练过程中通过增加损失进而对瑕疵进行抑制。虽然它确实改善了 GAN-SR 的结果,但我们仍然可以观察到 LDL 在推理真实世界测试数据时会存在明显瑕疵,如上图所示。因此,仅仅通过改善模型的训练很难解决这些瑕疵问题,因为这些瑕疵在 GAN-SR 模型的训练过程中可能并不出现。这里我们区分一下 GAN 训练出现的瑕疵和测试出现的瑕疵:- GAN 训练出现的瑕疵(GAN-training artifacts):出现在训练阶段,主要是由于训练时网络优化的不稳定和在同分布数据上的 SR 的 ill-pose 导致。在有干净的高清图像存在的情况下,可以在训练过程中对这些瑕疵加以约束,进而缓解瑕疵的生成,如 LDL [3]。
- GAN 推理出现的瑕疵(GAN-inference artifacts):出现在推理阶段,这些伪影通常是在真实世界未见过的数据中出现的。这些瑕疵通常不在训练数据的分布中,并不会在训练阶段出现。因此,通过改善训练过程的方法(例如 LDL [3])无法解决这些瑕疵问题。
处理 GAN 推理时产生的瑕疵是一项新的、具有挑战性的任务。首先真实场景的低分辨率图片没有对应的高清图片。此外,由于这些伪影在训练集中可能很少甚至从未出现过,因此很难模拟这些瑕疵。换句话说,这些瑕疵对于模型来说是未知的,而且超出了其训练数据的分布范围。解决这个问题是将 GAN-SR 模型应用于实际场景的关键,具有重要的实用价值。在本文中,研究团队专注于处理 GAN 推理时产生的瑕疵。这些瑕疵对实际的应用有很大的负面影响,因此解决它们具有很大的实际价值。由于这些瑕疵的复杂性和多样性,一次性解决所有瑕疵是具有挑战性的。- 这些瑕疵不会出现在预训练的 MSE-SR 模型中。
- 这些瑕疵很明显且面积较大,能够很容易被人眼捕捉到。上图展示了一些包含这些瑕疵的样例。
对于前一特征,研究团队希望确保瑕疵是由 GAN 引起的,而相应的 MSE-SR 结果对于测试数据是良好的参考结果,从而区分瑕疵。其原理在于,GAN 瑕疵的呈现通常是有着过多不需要的高频 “细节”。换句话说,研究团队引入 GAN 训练来生成精细的细节,但他们不希望 GAN 生成的内容与 MSE-SR 的结果相差太大。注意,即使对于没有见过的真实场景的测试数据,MSE-SR 结果也很容易获得,因为我们通常是基于 MSE-SR 模型进行微调以获得 GAN-SR 模型。对于后一特征,之所以优化考虑那些明显且占据较大区域的瑕疵,是因为这种类型的瑕疵对人的感知有很大影响。具体的,研究团队首先设计了一个定量指标,通过计算局部方差来衡量 MSE-based 和 GAN-based 模型生成结果之间的纹理差异。该指标总共包含着以下几个部分。- 局部纹理复杂性:局部区域 P 内像素强度的标准差 σ(i, j) 来表示局部纹理
- 绝对纹理差异 d:两个局部区域的标准差(x 表示 GAN-SR 区域,y 表示 MSE-SR 区域)
在获得纹理差异图 D 后,可以利用它来确定需要处理的区域。然而,仅仅使用纹理复杂度的差异作为判断依据是不够的,因为不同语义区域的感知容忍度是不同的。例如,复杂纹理区域中的细节,如植被、头发等,很难被感知为瑕疵,而平滑或规则纹理区域中的像素差异较大,例如海洋、天空和建筑物,对人类感知敏感,容易被看作瑕疵。因此,研究团队我根据语义信息对伪影图 D 进行了进一步的调整,得到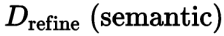 ,下图的第六列。最后,研究团队通过形态学操作来获得最终的瑕疵检测结果,即下图的第七列。具体来说,他们首先使用一个 5×5 全为 1 的矩阵进行腐蚀操作。然后,使用该矩阵进行膨胀操作以连接不连续的区域。接下来,使用一个 3×3 全为 1 的矩阵来填充地图中的空洞。最后,过滤掉离散的小区域作为检测噪声。对复原结果中瑕疵的检测本身具有很大的实际价值。基于该结果,研究团队希望进一步改进 GAN-SR 模型。考虑到对于实际应用而言,有着明显的瑕疵往往是用户无法容忍的,而没有瑕疵的弱恢复结果(细节少一点)比带有瑕疵的强恢复结果更可接受。因此,他们利用 MSE-SR 结果作为模型输出的参考。如下图所示,研究团队使用 MSE-SR 结果替换在 GAN-SR 结果中检测到瑕疵的区域。合并的图像用作伪高清图片(伪 GT)。其中
,下图的第六列。最后,研究团队通过形态学操作来获得最终的瑕疵检测结果,即下图的第七列。具体来说,他们首先使用一个 5×5 全为 1 的矩阵进行腐蚀操作。然后,使用该矩阵进行膨胀操作以连接不连续的区域。接下来,使用一个 3×3 全为 1 的矩阵来填充地图中的空洞。最后,过滤掉离散的小区域作为检测噪声。对复原结果中瑕疵的检测本身具有很大的实际价值。基于该结果,研究团队希望进一步改进 GAN-SR 模型。考虑到对于实际应用而言,有着明显的瑕疵往往是用户无法容忍的,而没有瑕疵的弱恢复结果(细节少一点)比带有瑕疵的强恢复结果更可接受。因此,他们利用 MSE-SR 结果作为模型输出的参考。如下图所示,研究团队使用 MSE-SR 结果替换在 GAN-SR 结果中检测到瑕疵的区域。合并的图像用作伪高清图片(伪 GT)。其中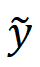 表示生成的伪 GT,
表示生成的伪 GT,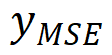 和
和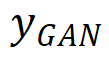 分别是 MSE-SR 和 GAN-SR 结果,(・) 表示逐元素相乘,M 是检测到的伪影地图。然后,研究团队使用少量数据从真实数据中生成数据对(x,)来微调模型,其中 x 表示 LR 数据。只需要进行少量迭代的微调(在本次实验中大约 1K 次迭代就足够了),更新后的模型将产生视觉感知良好且没有明显瑕疵的结果。此外,它不会影响没有瑕疵的区域中的细节。这种方法的工作机制是通过微调过程将合成数据的分布与实际数据的分布之间的差距缩小,从而减轻 GAN-inference 中的瑕疵问题。研究团队使用 Real-ESRGAN [2],LDL [3] 以及 SwinIR [4] 来验证他们的方法的有效性。考虑到现有的几个真实世界的超分辨率数据集都假设了特定相机的退化情况,导致会与实际情况相差甚远。因此,他们构建了一个人工标注的瑕疵数据集。考虑到图像内容和退化的多样性,他们使用 ImageNet 1K 的验证集作为真实世界的低分辨率数据。然后,选择每种方法中有 200 张有 GAN-inference 瑕疵的图像来构建瑕疵数据集,并使用 labelme 手动标记瑕疵区域。这是首个用于 GAN-inference 瑕疵检测的数据集。对于微调过程,他们对 200 张图片进行划分,其中 50 张用于模型的微调,另外 150 张作为验证集。
分别是 MSE-SR 和 GAN-SR 结果,(・) 表示逐元素相乘,M 是检测到的伪影地图。然后,研究团队使用少量数据从真实数据中生成数据对(x,)来微调模型,其中 x 表示 LR 数据。只需要进行少量迭代的微调(在本次实验中大约 1K 次迭代就足够了),更新后的模型将产生视觉感知良好且没有明显瑕疵的结果。此外,它不会影响没有瑕疵的区域中的细节。这种方法的工作机制是通过微调过程将合成数据的分布与实际数据的分布之间的差距缩小,从而减轻 GAN-inference 中的瑕疵问题。研究团队使用 Real-ESRGAN [2],LDL [3] 以及 SwinIR [4] 来验证他们的方法的有效性。考虑到现有的几个真实世界的超分辨率数据集都假设了特定相机的退化情况,导致会与实际情况相差甚远。因此,他们构建了一个人工标注的瑕疵数据集。考虑到图像内容和退化的多样性,他们使用 ImageNet 1K 的验证集作为真实世界的低分辨率数据。然后,选择每种方法中有 200 张有 GAN-inference 瑕疵的图像来构建瑕疵数据集,并使用 labelme 手动标记瑕疵区域。这是首个用于 GAN-inference 瑕疵检测的数据集。对于微调过程,他们对 200 张图片进行划分,其中 50 张用于模型的微调,另外 150 张作为验证集。由于缺乏真实世界低分辨率数据的高清参考图片,经典指标如 PSNR、SSIM 无法采用。因此,研究团队考虑三个指标来评估检测结果,包括 1) 检测到的瑕疵区域与实际的(人工标注的)瑕疵区域之间的交并比(IoU),2) 检测结果的精确度和 3) 检测结果的召回率。当用 A 和 B 表示特定区域 z 的检测到的瑕疵区域和实际的瑕疵区域时,IoU 定义为:
计算每个图像的 IoU,并使用验证集上的平均 IoU 来评估检测算法。较高的 IoU 意味着更好的检测准确性。然后,我们将检测到的瑕疵区域集合定义为 S,正确样本集合 T 定义为:
精确度 =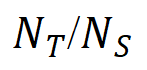 表示正确检测的区域数(
表示正确检测的区域数(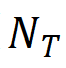 )占总检测到的区域数(
)占总检测到的区域数(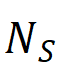 )的比例。
)的比例。
研究团队将实际的瑕疵区域定义为 G,并通过以下方式计算检测到的 GT 瑕疵区域集合 R:召回率 = 表示正确检测到的 GT 瑕疵区域数(
表示正确检测到的 GT 瑕疵区域数(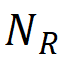 )占总 GT 瑕疵区域数(
)占总 GT 瑕疵区域数(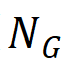 )的比例。其中,p 是一个阈值,研究团队根据经验将其设置为 0.5。
)的比例。其中,p 是一个阈值,研究团队根据经验将其设置为 0.5。
如下表所示,针对 LDL 模型中的瑕疵检测结果中,本文方法获得了最好的 IoU 和 Precision,远远超过其他方案。需要注意的是,LDL 在 threshold=0.001 时获得了最高的召回率。这是因为该方案将大部分区域视为瑕疵,因此这种检测结果几乎没有意义。Real-ESRGAN 和 SwinIR 的结果可以参考原文。研究团队同时对比了使用 DeSRA 微调策略之前和之后的瑕疵检测结果,结果如下表所示,当应用他们的 DeSRA 之后,Real-ESRGAN 的 IoU 从 51.1 降至 12.9,LDL 的 IoU 从 44.5 降至 13.9,说明瑕疵区域的检测面积大大减少。去除率分别为 75.43% 和 74.97%,表明在微调之后,测试数据中四分之三的瑕疵可以完全消除。此外,他们的方法没有引入额外瑕疵,添加率为 0。本文在下图中提供了使用与未使用该文方法改进 GAN-SR 模型的结果的视觉比较。与原始的模型结果相比,改进的 GAN-SR 模型生成的结果在视觉质量上更好,没有明显的 GAN-SR 瑕疵。所有这些实验结果证明了本文方法能有效的缓解模型在处理真实的低清图片时会出现的瑕疵。为了进一步验证本文 DeSRA 微调策略的有效性,研究团队进行了两项用户研究。第一项是比较原始 GAN-SR 模型和微调后的 GAN-SR 模型生成的结果。对于这个实验,比较的重心是图片中是否存在明显的伪影。研究团队产生了共 20 组图像,每组包含 GAN-SR 模型和微调后的 GAN-SR 模型的输出结果。这些图像被随机打乱。共有 15 人参与了用户研究,并为每组选择他们认为伪影较少的图像。最终的统计结果如图 9 所示。82.23% 的参与者认为微调后的 GAN-SR 模型生成的结果较少存在伪影。可以看出,本文方法在很大程度上消除了原始模型产生的瑕疵。第二项是对微调的 GAN-SR 模型和原始的 MSE-SR 模型结果的比较。这个实验是为了比较模型生成的结果是否有更多的细节。研究团队总共产生了 20 组图像,每组图像包含了 MSE-SR 模型和微调的 GAN-SR 模型的输出结果。这些图像被随机打乱。总共有 15 个人参加用户研究,并为每组选择他们认为有更多细节的图像。最终的统计结果如图 9 所示。93% 的参与者认为微调的 GAN-SR 模型生成的结果有着更多的细节。可以看出,微调的 GAN-SR 模型仍然比 MSE-SR 模型能够生成更多的细节。在这项工作中,研究团队分析了 GAN 在推理阶段引入的瑕疵,并提出了方法来检测和消除这些瑕疵。具体而言,他们首先计算了 MSE-SR 和 GAN-SR 的相对局部方差,并进一步结合语义信息来定位有瑕疵的区域。在检测到存在瑕疵的区域后,他们使用基于 MSE 的结果作为伪高清图片来微调模型。通过仅使用少量数据,微调的模型可以成功消除原始模型在推理过程中的瑕疵。实验结果显示了他们的方法在检测和去除瑕疵方面的优越性,并且显著提高了 GAN-SR 模型在实际应用中的能力。本文方法可以与持续学习相结合,从而提供一个新的范式来解决在线推理阶段中出现的瑕疵问题。例如,对于处理真实世界数据的在线超分辨率系统,可以使用研究团队的检测流程来检测复原的结果是否具有 GAN-inference 瑕疵。然后,他们可以使用检测到的带有瑕疵的图像快速对超分辨率模型进行微调,使其能够处理类似的瑕疵,直到系统遇到新的 GAN-inference 瑕疵。持续学习已经在高层视觉任务上得到广泛研究,但尚未应用于超分辨率。研究团队希望在未来研究这个问题,因为它可以极大地推进 GAN-SR 方法在实际场景中的应用。[1] BSRGAN: Designing a Practical Degradation Model for Deep Blind Image Super-Resolution.[2] Real-ESRGAN: Training real-world blind super-resolution with pure synthetic data.[3] LDL: Details or artifacts: A locally discriminative learning approach to realistic image super-resolution. [4] SwinIR: Image restoration using swin transformer.
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:[email protected]