【新智元导读】社交环境会影响阅读选择?谷歌的机器学习算法助力推荐系统优化用户体验,学校与年级分组比地区更准确。
开卷有益,是我们一直以来的认识。阅读可以帮助人们提高自己的语言能力、学习到新的技能....阅读还能够改善情绪,提高心理健康水平。经常阅读的人有更丰富的常识以及对其他文化更深入的理解。但在信息爆炸的时代,线上与线下的阅读资源都十分丰富。读什么,就成为了一项艰巨的挑战。尤其是阅读的内容既要匹配不同的年龄阶段,又要引人入胜。而推荐系统则是这个挑战的解决方案。它能够向读者呈现相关的阅读材料,并帮助他们保持阅读的兴趣。推荐系统的核心是机器学习(Machine learning, ML),它被广泛应用于构建各种类型的推荐系统中:从视频到图书,再到电商平台等。经过训练的ML 模型可以根据用户偏好、用户参与度和推荐的项目单独向每个用户进行推荐,从而改善用户体验。谷歌最新的研究提出了一种考虑到阅读的社会性质(如教育环境)的有声读物内容推荐系统:STUDY算法。由于一个人的同龄人目前正在阅读的内容会对他们感兴趣的阅读内容有重大影响,因此,谷歌与Learning Ally进行了合作。Learning Ally是一家教育非营利组织,拥有一个针对学生的大型精选有声读物数字图书馆,非常适合构建社交推荐模型。这能使模型能够从有关学生本地化社交群体的(如教室)实时信息中获益。
STUDY算法采用了将推荐内容问题建模为点击率预测问题的方法。之前的工作表明Transformer模型非常适合建模这个问题。当单独处理每个用户时,模拟交互就成为了一个自回归序列建模问题。STUDY算法是通过这一概念框架对数据建模,然后对这个框架进行扩展的最终成品。点击率预测问题可以对个别用户过去和未来的项目偏好之间的依赖关系进行建模,并且可以在训练时学习用户之间的相似性模式。但有一个问题是,点击率预测的方法无法对不同用户之间的依赖关系进行建模。为此,谷歌开发了STUDY模型,可以解决自回归序列建模中无法对阅读的社会性质进行建模的缺陷。STUDY可以将多个学生在一个课堂上阅读的书籍序列连接成一个序列,从而在一个模型中收集多个学生的数据。但是,在用Transformer对这种数据表示进行建模时,需要仔细研究这种数据表征。在Transformer中,注意力掩码是控制哪些输入可用于预测哪些输出的矩阵。在序列中使用所有先前的token来为输出的预测提供信息的模式,会导致上三角形注意力矩阵,它一般会在因果解码器中被发现。然而,由于输入进STUDY模型的序列不是按时间顺序的,尽管它的每个组成子序列都是按时间顺序,传统的因果解码器也不再适合这种序列。在试图预测每个token时,模型不允许注意力转向序列中出现在它之前的每个token;其中一些token可能具有较晚的时间戳,并包含在部署时不可用的信息中。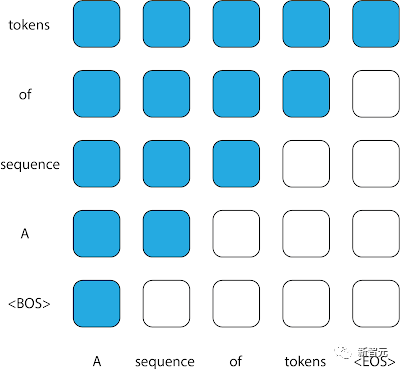
因果解码器中通常使用的注意力掩码。每一列代表一个输出,每一列代表一个输出。矩阵条目在特定位置的值为1(显示为蓝色),表示模型在预测相应列的输出时可以观察到该行的输入,而值为0(显示为白色)则表示相反。STUDY 模型以因果转换器为基础,将三角矩阵注意力掩码替换为基于时间戳的灵活注意力掩码,从而允许跨不同子序列的注意力。与普通转换器相比,STUDY 模型在一个序列中保持一个因果三角注意矩阵,并在不同序列中具有灵活的值,这些值取决于时间戳。因此,序列中任何输出点的预测都会参考相对于当前时间点过去发生的所有输入点,无论它们是出现在序列中当前输入点之前还是之后。这一因果约束非常重要,因为如果在训练时不执行这一约束,模型就有可能学会利用未来的信息进行预测,而这在现实世界的部署中是无法实现的。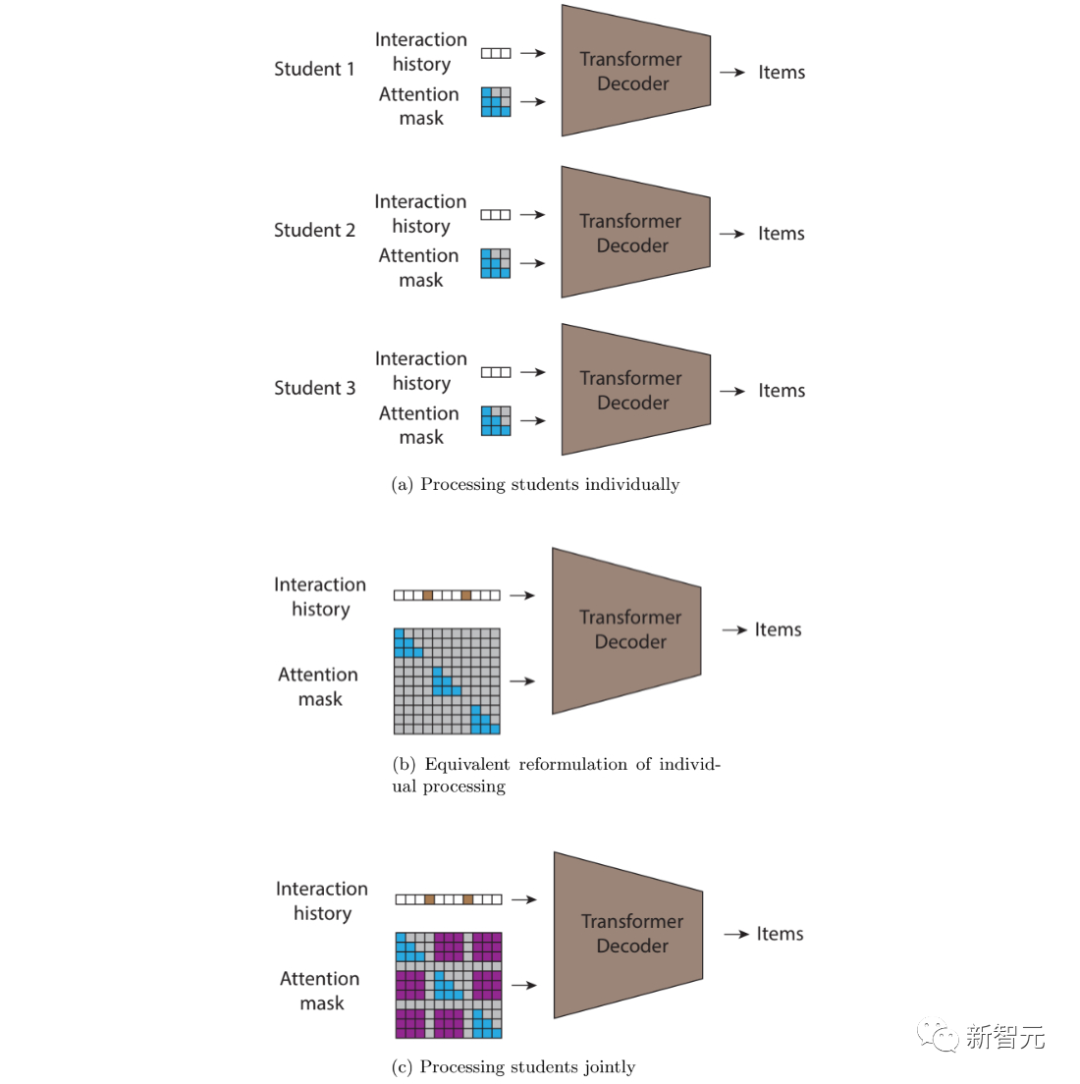
(a)一个具有因果注意力的顺序自回归变换器,它可以单独处理每个用户;(b)一个等效的联合前向传递,其计算结果与(a)相同;(c)通过在注意力掩码中引入新的非零值(紫色显示),允许信息在用户间流动。为此,研究者允许预测以时间戳较早的所有交互为条件,而不论交互是否来自同一用户
谷歌使用Learning Ally数据集来训练STUDY模型,并使用多个基线进行比较。
团队使用了自回归点击率转换解码器(称之为「个人」)、k-近邻基线(KNN)和可比较的社会基线——社会注意力记忆网络(SAMN)。他们使用第一学年的数据进行训练,使用第二学年的数据进行验证和测试。团队通过测量用户实际交互的下一个项目,在模型的前n个建议中的时间百分比,来评估这些模型。除了在整个测试集上对模型进行评估外,团队还报告了模型在测试集的两个子集上的得分,这两个子集比整个数据集更具挑战性。可以观察到,学生通常会与有声读物进行多次互动,因此,简单地推荐用户阅读的最后一本书,就显得微不足道。因此,研究者将第一个测试子集称为「非延续」,在这个子集中,我们只考察每个模型在学生与不同于前一次互动的书籍进行互动时的推荐性能。另外,团队还观察到,学生们会重温他们过去读过的书,因此,将为每个学生推荐的书本限制在他们过去读过的书本范围内,就可以在测试集上取得很好的表现。尽管向学生推荐他们过去最喜欢的书籍可能有一定的价值,但推荐系统的大部分价值还是来自于向用户推荐新的、未知的内容。为了衡量这一点,团队在测试集的子集上对模型进行了评估,在这个子集上,学生们第一次与书目进行交互。我们将这个评估子集命名为「新子集」。可以发现,「STUDY 」在几乎所有评估中,都优于其他模型。STUDY算法的核心是将用户分组,并在模型的单次前向传递中对同组的多个用户进行联合推断。研究人员通过一项消融研究,考察了实际分组对模型性能的重要性。在提出的模型中,研究人员将同一年级和学校的所有学生进行分组。然后试验了由同一年级和同一学区的所有学生定义的分组,以及将所有学生归入一个组中,并在每次前向传递时使用随机子集的分组。研究人员还将这些模型与 「个人」模型进行了比较,以供参考。研究发现,使用更本地化的小组更有效,即学校和年级分组优于学区和年级分组。这支持了一个假设,即研究模式之所以成功,是因为阅读等活动具有社会性:人们的阅读选择很可能与周围人的阅读选择相关联。在不使用年级对学生进行分组的情况下,这两种模式的表现都优于其他两种模式(单一小组模式和个人模式)。这表明,阅读水平和兴趣相似的用户的数据有利于提高模型的性能。最后,谷歌的这项研究是仅限于假定社交关系是同质的用户群进行建模的。参考资料:
https://ai.googleblog.com/2023/08/study-socially-aware-temporally-causal.html