
大家好,我是Epione。最近有小伙伴经常在后台问,能不能出一个SPSS使用教程?我也想点点点出统计结果。
一开始我有点“诧异”,无论是咱们解螺旋自己的精品课,还是各大公众号的推文,亦或者在某度上一搜索,关于SPSS操作的“教程”似乎都已经“烂大街”了,为何仍然有这么多小伙伴在做统计分析时感到“两眼一抹黑”,甚至搜索的关键词都想不到了呢?
我深入调研了一下,觉得目前市场上存在的“统计学教程”可能普遍存在这么几个问题:1. 知识点零碎。有的小伙伴今天看了t检验介绍,明天又看了一篇方差分析的介绍,后天放假玩了一天“羊了个羊”。大后天导师给了一批数据,要处理的时候完全想不起来可以用什么方法。知识掌握的不够系统,即使在单个知识点上介绍得很清楚,也不能使其学会应用。2. 重原理,而轻解读。我一直都主张认为对于普通的医学科研人员来说,要把统计知识、统计方法当做“药方”一样来学习,我们要知道每一种药物的“适应症”,也要知道它的“禁忌症”和“配伍”。做到看到一种数据就能形成“条件反射”。至于这个方法背后的数学原理、公式,就只能留给那金字塔尖1%的牛人去琢磨了。因此,有些教程上来就介绍了很多统计方法的数学背景,我相信很多医学生看的已经云里雾里了,又如何能够坚持学习下去呢?此外,一个新方法的学习最好的就是理解他的用处。一些教程在举例的时候要么不是临床医学的例子,要么对结果的解读不够深入,使学员即使点出了自己的分析结果,也不知道如何下结论。3. 缺乏实操。今天看了一个教程,似乎看懂了,过了几天又抛之脑后。而缺乏实操的客观原因就是没有数据!没数据→没法练习→没法掌握统计方法,这似乎陷入了一种无法克服的“恶性循环”。4. 缺少解决问题思维的培养。很多学员在本科《医学统计学》考试能考98分,但是在面对数据的时候依然抓瞎。这是因为考试是有“重点”可以去背的。但是拿到数据以后,你要做的不是背诵什么概念、知识点、重点,而是真真切切要解决问题。在解决问题的过程中,你会发现:做完两组总体均值差异的t检验后,你会立马想到再做一个线性回归调整混杂因素。虽然在教科书中t检验和线性回归被安排在相差很远的章节,但是它却能够相辅相成回答一个临床问题——该连续性指标在组间到底有没有差异!发现这些问题后,Epione老师“痛心疾首”。因为解决上面所述的问题并不简单。我想最有效的途径,就是跟着我参加学习10月28日开始的“通关临床预后型研究”。这个课程虽然名字中关注预后型研究,但实际上基础统计学知识都会涉及。同时,这个培训班会手把手带领大家下载SEER数据库,让大家带着数据,从解决问题的目的入手,实现基础统计学知识的串讲,从而带领大家实现SCI 3-5分文章的复现!重点解决上面提到的4大问题!
当然,如果你抽不出连续的21天时间来参加讲席营,我们也希望你能通过在我们“君莲数据库”公众号的跟踪学习,系统掌握基础统计知识!所以从这一期开始,我们将陆续推出基于SPSS的常见统计方法操作指导。这样虽然不能和Epione老师面对面语音交流,但是这个系列的推文,希望可以成为你的“枕边书”,在需要的时候随时拿起来翻看!言归正传!今天想给大家介绍的第一个统计方法是“单样本t检验”。它虽然不比“独立样本t检验”那样家喻户晓,但是却可以解决许多临床大问题,不信你来看。如果我们要研究某降压药物服用前后是否可以使血压下降,抽取了10名高血压患者,分别在服药前后测量血压。服药前后血压变化值分别为:-10,-1,0,8,5,-2,4,3,7,-9,那么这个药是否有降压作用呢?
回答这个问题之前,我们不妨想一下,如果这个药物没有降压作用,那么理论上这群人前后血压变化应该是多少?所以上面这个临床问题,可以转换为数学问题,就是:这些数值(前后血压变化)的总体均值是不是0?1. 研究目的是检验某一组数据是否来自于某个已知均值的总体(上面这个例子中,如果该药没有效果,那么差值应该等于0。这个0就是总体!);2. 待检验的变量Y是连续变量。当然此时我们可以先假设它服从正态或近似正态分布,并且样本个体值之间是相互独立的(每个患者自己的血压变化情况是和别人无关的)。在SPSS变量视图窗口新建一个变量血压变化值(图1),在数据视图窗口将10名高血压患者的血压变化值数据填入血压变化值变量下单元格,如图2所示。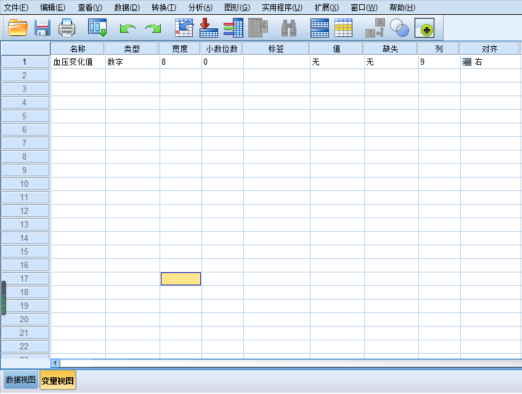
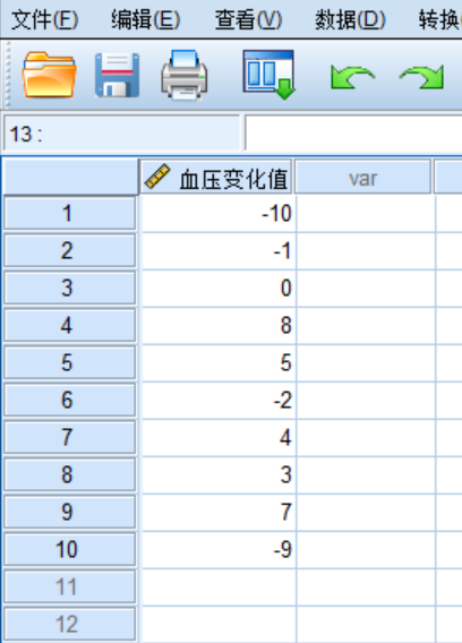
1、我们知道如果该药物总体上是无效的话,那么前后的血压变化值就应该是0。因此,该问题意在分析样本均值与已知的总体均值(0)之间是否存在统计学差异,即这10名高血压患者服药前后的血压变化值的平均值是否为0,从而检验该降压药物是否有效,应该使用单样本t检验。2、血压值为连续型变量,假设高血压患者服药前后的血压变化值服从正态分布(当然也可以通过正态性检验来看,这个我们后面单独介绍),这10名高血压患者服药前后的血压变化值是相互独立的个体值,符合单样本t检验的条件。主界面点击分析—比较均值—单样本T检验,即出现单样本T检验对话框,在对话框中将左侧方框中的变量血压变化值选入右侧检验变量,并在下方检验值中填写总体均值,在本案例中即为0,然后点击确定,如图3、图4所示。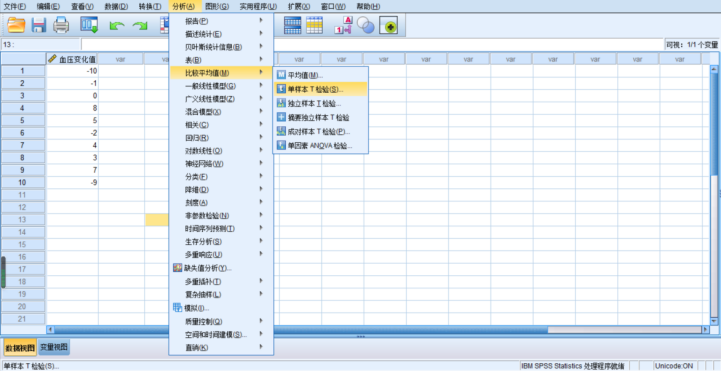 图3
图3
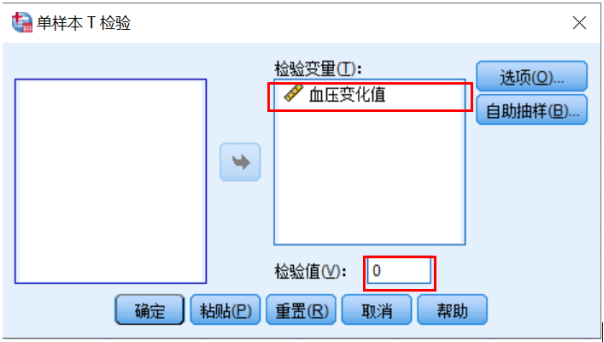
图4
在进行单样本t检验之前,spss统计软件还会给出样本数据的基本统计量,如图5所示,我们可以得知,这10名高血压患者服药前后的血压变化值的平均值为0.50,标准差为6.205。 图5
图5
单样本t检验的结果如图6所示,对比的总体均值(检验值)为0,t统计量为0.255,P值(Sig)为0.805>0.05,按照α=0.05的检验水准认为样本均值和总体均值之间的差异无统计学意义,即这10名高血压患者服药前后的血压变化值与总体均值0之间的差异无统计学意义,认为该降压药物无降压效果。此外,我们从图中还可以得出,样本均值和总体均值的差值为0.5,该差值的95%置信区间为-3.94到4.94,置信区间包含0。两样本均值差等于0时,说明两样本均值相等。因此该置信区间说明该样本与总体的均值差无统计学意义。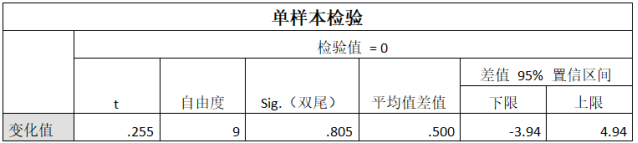 图6
图6
1. 样本数据必须来自于正态或近似正态总体,因此在进行单样本t检验前应该先进行正态性检验。2. 上面举的例子是最为常见的单样本t检验使用场景,大家可以将其作为典型案例。在临床研究中,还有一种可能用到单样本t检验的场景:既往有一项权威研究认为,健康人的某心理量表得分平均值在60分(即常模)。某研究随机抽取了一群糖尿病病人,采用同样的量表进行调查。欲分析该糖尿病的人群该量表得分是否与健康人不同?此时也应该采用单样本t检验,并且总体均值设定为60。好啦,今天的课是不是还是很简单呢?快来动手实践操作一下吧!我们接下来还会继续介绍经典的组间比较假设推断方法(如独立样本t检验、方差分析、秩和检验、卡方检验……)、常见回归模型(一般线性回归、Logistic回归、Cox回归等)、预测模型、“高级”统计方法(如中介效应分析、工具变量等)等系列的教程。欢迎锁定关注我们的“SPSS操作系列推文”吧!当然,这个更新可能会有点慢,想在短时间内掌握以上这些,欢迎报名参加“通关临床预后型研究”训练营!