“混元”初开
9月7日,深圳的连绵细雨中,一场意料之中的发布会终于拉开序幕。舞台的大屏幕,一位工作人员缓缓在键盘中敲下数个问题:“你是谁?”“你的核心技术架构是什么?”类似微信对话框一样的鲜艳绿色,揭示着这场发布会的主角。回答者的光标闪烁,缓缓道出:您好!我是腾讯混元大模型,……”在2023年上半年的“百模大战”开打半年后,腾讯终于揭开了通用大模型“腾讯混元”的面纱。腾讯集团高级执行副总裁、云与智慧产业事业群CEO汤道生在会上表示,腾讯将迈入全面拥抱大模型时代。当前,包括腾讯云、腾讯文档、腾讯视频在内的50多个业务,都已经接入混元进行测试。 腾讯集团高级执行副总裁、
腾讯集团高级执行副总裁、
云与智慧产业事业群CEO汤道生
混元的发布的意义在于,在巨头中,腾讯不仅坐拥微信、QQ等国民级To C社交产品,在To B端也坐拥企业微信、腾讯文档、腾讯会议等王牌应用,这是离用户最近的第一落点。而在大模型时代来临后,AI能够为这些产品和场景带来多少增量,决定了AI能够多有效地落地。在生态大会上,腾讯除了展示混元在聊天对话、文字生成等方面的能力,更为重要的是与各类产品的结合:在腾讯广告中,AI助手可以进行广告素材创作,生成合适的广告模特图,商品文案等;在腾讯会议中,混元能帮助与会者,实时总结会议讨论了多少个论点,并且能够分辨出参会者A、B、C是谁,并且总结某个人的观点。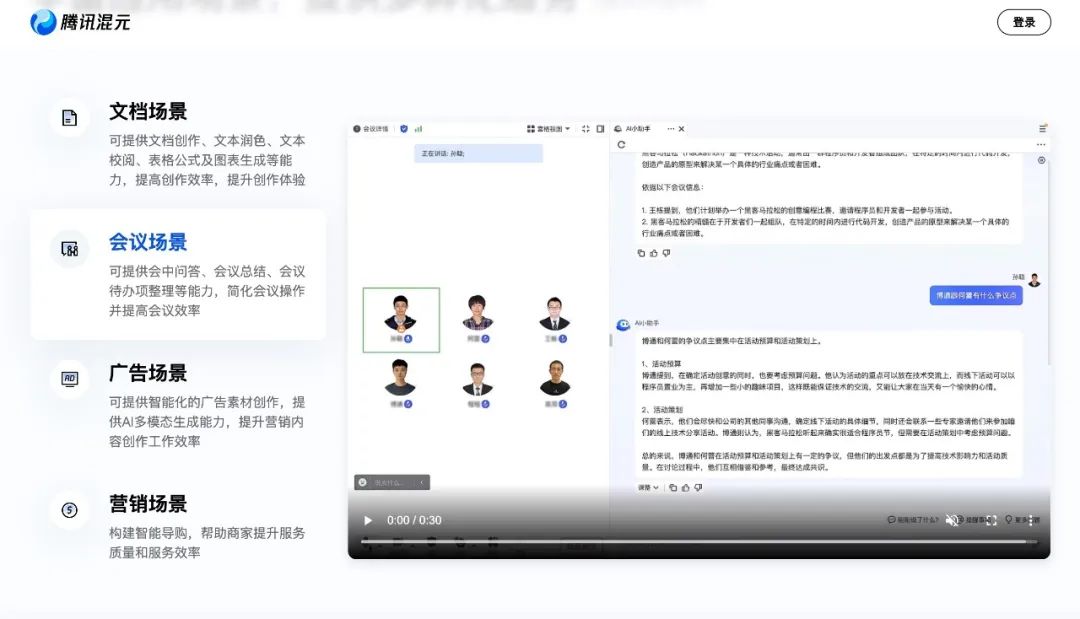
OpenAI的ChatGPT在去年底推出后,以迅雷不及掩耳之势点燃全球,这把火蔓延到中国后,中国的互联网巨头、AI公司、甚至各个垂直行业中的垂直龙头,纷纷宣布要做AI大模型,追上这波时代浪潮。与其说沉默,不如说腾讯是不急于一时。“我们也一样在埋头研发,但是并不急于早早做完,把半成品拿出来展示。对于工业革命来讲,早一个月把电灯泡拿出来在长的时间跨度上来看是不那么重要的。”今年5月,马化腾在股东大会中如此表示。而到了混元对外亮相的此刻,腾讯集团副总裁蒋杰将其定义为一个“可用”“可实践”的大模型。“从今天的展示可以看出,从大语言模型,到文生图,到最后的视频,混元的能力一直在演进,混元的亮相只是开始。”蒋杰表示。 腾讯集团副总裁蒋杰事实上,能在短时间内做到这些能力,并非一蹴而就。“混元”大模型并不是在ChatGPT浪潮来临之后才出现的产品,真正的投入早在两年前才开始。蒋杰回忆,腾讯在2021年开始研发混元,一开始就用在了广告业务当中。“最早的混元并不是稠密的大模型,我们是基于稀疏结构的大模型,用于支撑我们的广告业务。”稀疏结构的大模型特点在于,具有非常大的容量,但只有模型的用于给定的任务、样本或标记的某些部分被激活,好处在于,让千亿甚至万亿的模型运行起来更容易。从人工智能的发展脉络来看,在以Transformer为主的大模型架构创新出来前,AI在工业界还是以CV(图像识别)为主应用方向,比如摄像头的人脸识别等等。在这样的场景中落地,基本是针对每个细分场景训练一个专有的模型,参数体量很少过亿。但大模型的体量大,需要高密度的,以GPU为主的算力。如果说机器学习、深度学习等流派让AI进入工业化时期,那么大模型的出现,则是让AI进入到“重工业”阶段——需要海量的数据、大量以GPU为主的算力,而底层的芯片、训练框架等都需要重新做适配。
腾讯集团副总裁蒋杰事实上,能在短时间内做到这些能力,并非一蹴而就。“混元”大模型并不是在ChatGPT浪潮来临之后才出现的产品,真正的投入早在两年前才开始。蒋杰回忆,腾讯在2021年开始研发混元,一开始就用在了广告业务当中。“最早的混元并不是稠密的大模型,我们是基于稀疏结构的大模型,用于支撑我们的广告业务。”稀疏结构的大模型特点在于,具有非常大的容量,但只有模型的用于给定的任务、样本或标记的某些部分被激活,好处在于,让千亿甚至万亿的模型运行起来更容易。从人工智能的发展脉络来看,在以Transformer为主的大模型架构创新出来前,AI在工业界还是以CV(图像识别)为主应用方向,比如摄像头的人脸识别等等。在这样的场景中落地,基本是针对每个细分场景训练一个专有的模型,参数体量很少过亿。但大模型的体量大,需要高密度的,以GPU为主的算力。如果说机器学习、深度学习等流派让AI进入工业化时期,那么大模型的出现,则是让AI进入到“重工业”阶段——需要海量的数据、大量以GPU为主的算力,而底层的芯片、训练框架等都需要重新做适配。宛如建立一座堡垒,这两年间,除了混元的训练之外,腾讯在底层的服务器、高性能网络、训练框架到AI平台,都有单独的产品推出,一砖一瓦,为大模型搭建起新的基础设施底座。
只需用一句话,就足以描绘出中国大模型战局之紧张。“据公开数据,到7月底为止,国内大概有130个AI大模型。”腾讯集团副总裁蒋杰表示。在国内,不只是互联网巨头做通用大模型,还有垂直厂商做各种垂直行业的模型。在“刚出道就成红海”的竞争中,如何才能抓住用户,这是所有大模型玩家要面对的命题。在混元发布之前,腾讯唯一一次对大模型进行发声是在今年6月。腾讯先行推出了覆盖10个行业的超过50个解决方案。简单而言,腾讯相当于向前走了半步——用户不需从0到1构建一个模型,只需要在行业大模型上加入数据微调,即可得到一个自己专属的企业模型。而到了混元发布,腾讯如今也已经全面开放了API服务。混元将会作为腾讯MaaS(模型即服务)的基座,客户可以直接通过API调用混元,也可以将混元作为基底模型,为不同产业场景构建专属应用。之所以要在企业客户处抢占身位,一个重要的原因在于,ChatGPT引发的大模型热潮,会带动云计算行业进入新的时代。在过去,云计算如同标准化的水电煤,随取随用,产品也相对标准化。但如今客户需要的AI能力却是“大模型即服务”,对智能水平有更高的要求。比如,客服机器人能不能给出更人性化、更像人的答案、生成图像、文案是否能够满足人类员工的要求。客户则愿意为智能水平支付溢价——这会成为AI未来利润的来源。而无论是客服机器人、生成广告文案、在PPT中充当助手等等……其共通点在于,离客户“最后一公里”的服务,重要性前所未有地提高。不难得出,应用场景才是决胜的关键因素。“最务实的做法,还是回到每个企业自身的痛点,降本增效,用行业大模型去解决企业的问题。可能刚开始使用的版本只能解决问题的80%,但因为有很清晰的使用场景,用户的反馈能够形成反哺,让你不断打磨你的行业大模型,提升答题准确率。”汤道生解释。在硅谷,AI应用的热潮已经愈演愈烈。创业公司纷纷下场做新应用,但目前仍在早期,现在他们所面对的新用户更多是早期使用者(Early Adopter),挖掘更为广大的新客户还需要时间。更值得关注的现象是,大公司或者垂类巨头,都在拼命探索将生成式AI技术引入原有的业务里,这是一条稳健的路径。微软在To B领域已是巨头。在投资OpenAI并且达成深度合作后,微软在自家的Office 365套件中加入AI助手Copilot,定价每月30美元,基本是把商业用户Office服务的“实际定价”,提升了1-3倍,这也让微软的股价一度涨近4%,创历史新高。在垂类厂商里,Salesforce则是另一个让业务“焕发生机”的故事。作为CRM巨头,Salesforce旗下的Einstein原本只是一个不起眼的业务。但在2023年3月,Salesforce宣布推出CRM生成式AI工具EinsteinGPT,将GPT引入到Slack、Sales Service、Marketing、Commerce以及App构建工具之中。由此,这块业务摇身一变,成为Salesforce在AI时代的一个入口。腾讯的AI战略也有共通之处。“大模型的产业应用,可能不一定是很天马行空的、很‘嗨’的场景,也许就是怎么让你的售后服务高效,更快解答客户的疑问,虽然朴实但是有用。”汤道生解释道。事实上,基于自身的业务场景去构造产品,打磨产品,最后对外开放给企业用户——这是腾讯一直以来的创新路径。比如,由于内部在开会时总是遇到信号不稳、体验差等问题,腾讯组建起一支内部队伍,从0到1研发出腾讯会议,并且经历疫情时期的海量高并发考验。如今,腾讯会议已经服务了4亿多用户。AI大模型的高投入更是决定了,无论是AI原生的产品,还是将新技术引入到有业务中,都需要考虑商业层面的可持续发展。“腾讯混元大模型的建设,不是只为了在业界做发布、甚至评测打榜。从一开始,我们就是根据腾讯自身应用做研发和匹配,跟大模型深度结合,才能够去抵消整个大模型高昂的设备、训练、人员的成本。”蒋杰表示。上一波AI浪潮中,烧钱换市场增长的模式已经远去——在大模型新时代,企业将会迎来重塑商业模式、真正验证商业价值的时刻。在一场为期十年的AI长跑中,先扎根产业,以慢为快,无疑是当前中国AI赛道可见的一道务实解法。现在,混元不仅已经体系完备,MiniMax、智谱、百川智能等大模型创业企业都在使用腾讯云提供的算力。而在模型层,腾讯云在8月16日已经宣布,已经支持了20多款开源模型,包括如今开源领域受众最广泛的LLaMA2。面向产业,已是腾讯大模型的鲜明标签。一个细节是,在混元大模型进行应用场景展示时,会场里的几千个企业客户和合作伙伴,都纷纷拿出了手机拍照。这是一道有代表性的风景线。数千企业客户和生态合作伙伴,会成为腾讯开拓产业的重要同伴。这同样映照着国内大模型赛道的当下现状:“百模大战”激战半年后,首战已然结束,用AI画画、和AI对话已经不是新鲜事。到现在,谁能夺下场景,为客户提供足够多的产品,某种程度上更符合人们对国内大模型的下一阶段期待。
健康可持续更重要
走进AI新时代,是技术、产品的耐力战。而要支撑起这场战役的企业,还需要有一副“健壮的身体”。2023年8月,腾讯发布Q2财报,总营收1492亿元,同比增长11%。其中,ToB业务收入486亿元,同比增长15%。腾讯用“稳健”一词来形容这季的成绩。事实上,对腾讯而言,过去一年是一段“触底反弹”的时期——2022一整个财年,腾讯的收入和利润增速很长一段时间都不甚乐观。在互联网公司告别高增长,经济动荡的大环境下,变革已不能再等。早在“混元”慢慢积蓄力量、幻化成形之前,腾讯云自己这两年就在经历一场变革。心态上的转变是第一步。“以前做集成的时候,觉得自己在整个行业很多事都能做,签几个亿的单子会庆功,但真正做的时候,才是痛苦的开始。”腾讯集团副总裁、云与智慧产业事业群COO、腾讯云总裁邱跃鹏回忆起两年前的情景。 腾讯集团副总裁、云与智慧产业事业群COO、
腾讯集团副总裁、云与智慧产业事业群COO、
腾讯云总裁邱跃鹏
知道自己什么会、什么不会——这是腾讯在这两年中学到的重要一课。自家产品和技术问题都好说,实在不行,派产品团队派到一线驻场,总能解决。但冲在前头做集成,涉及大量的协调、管理、边界等等问题,完全不是产品和技术层面能够解决,造成的结果是——可能签了几个亿的单子,却很难交付,回款也很难。因此,过去两年里,腾讯开始坚定执行被集成战略,向后退一步,做自己擅长的事情。“我们在执行上非常坚决,在执行上也超出预期。”邱跃鹏说。高层的意志坚定,莫过于2022年12月的经典一幕——马化腾在内部大会中罕见喊话:“不要被人家奚落两句,说哎呀你这个云是不是被华为给超过了无所谓!我们不着急,千万不要上当!”而具体到一线业务中,腾讯也在大刀阔斧地调整战略,比起短期收入,腾讯更乐见长期的生意。“我们核心关注的点,第一是产品自身的竞争力,第二是产品是否很好地交付,让客户满意,第三是客户是否认可你的产品价值,愿意以合理的价格持续购买。”邱跃鹏表示。这也曾导致短暂的阵痛。腾讯集团副总裁、政企业务总裁李强记得,腾讯曾经有安防领域的合作伙伴,但腾讯因为执行被集成战略,放弃做一些项目后,“部分合作伙伴就从我们的合作伙伴平台里退出了。” 腾讯集团副总裁、政企业务总裁李强
腾讯集团副总裁、政企业务总裁李强
但通过这种“克制”,腾讯云反倒从原来大包大揽的千头万绪中,梳理出清晰的脉络,让业务跑得更加通畅。到今天,腾讯正在建立起与自己战略更契合,也更稳定的合作伙伴网络。据腾讯生态大会官方披露的数字,现在腾讯有超过11000家伙伴。成效也非常明显。自2022年下半年起,腾讯净利增速已经连续四季领先营收增速,2023年Q2的净利增速达33%,已是收入增速的三倍。向后退一步,建立起健康可持续的模式,反倒会为腾讯在下一个时代里积累起新的资本。如何建立起一套可持续的发展模式?汤道生总结了一套“721法则”:70%的资源投入在短期发展;20%是投入在发展中期的技术,可能再多两年就会有商业化变现,来补充成熟业务;最后的10%投在仍处于发展早期的前沿技术,面向未来机会布局,可能要三五年甚至更久才能带来商业回报。在大厂中,腾讯以做To C产品见长,等到做To B,腾讯继承了这一能力——腾讯文档、腾讯会议等国民应用就是证明。而在“721”这套机制下,腾讯的产品中心主义,在这两年间又续上了新的故事。基础设施的创新,对大模型而言意义更加重大。如今的大模型训练很大程度仍受限于基础设施,是一套“精密工程”。
在几年前,GPU在算力市场中占比不大,腾讯云副总裁王亚晨就曾在内部反复和客户讲:“和CPU的算力需求不同,GPU类似于新买一辆法拉利,如果要让它的性能充分发挥出来,直接在现在的城市里上路跑肯定不行,而一定要给它专有赛道——带宽要足够大,这是带宽对GPU性能的影响。”比如,AI大模型依靠GPU集群进行训练,数据交互有互相依赖关系,一个计算任务可能要几十块GPU芯片一起算,而芯片之间,都需要一定是等着最慢的那块芯片算完后,任务才算完成。而腾讯的研发团队经过测试发现,如果在这中间数据丢包率哪怕达到0.1%,GPU利用率基本一下就下降50%,对AI训练而言损失巨大。存储也存在类似的问题。大量计算节点会同时读取一批数据集,存储的性能同样会限制计算的性能,为了避免计算节点产生等待,需要尽可能缩短数据加载时长。简而言之,要搭建高性能的AI训练集群,计算、网络、存储,都不可有短板。因此,面对大模型带来的高性能网络需求,腾讯云开始建起了一条高速公路,也就是高性能网络平台“星脉”;并自研存储架构。而在此中间,更多的自研模块也能起到优化作用。比如腾讯云自研的高性能通信库TCCL,就能够感知到路径的拥塞情况,进行通信加速;而自研的端网协同的TiTa协议,就像一个“交通指挥官”一样,让GPU通信时选择最佳的数据调度路径,减少丢包现象。实测结果显示,搭载同等数量的GPU,3.2T星脉网络相较1.6T网络,集群整体算力提升20%。同时,腾讯云通过自研的存储架构,实现TB级吞吐能力和千万级IOPS,COS+GooseFS对象存储方案和CFS Turbo高性能文件存储方案,充分满足大模型场景下高性能、大吞吐和海量存储要求。“如果说大模型算力中的网络,是为GPU修了一条专业赛道。那么高性能存储,则是一个秒换轮胎的维修站,提前备好数据,尽量减少计算节点的等待,让集群性能进一步逼近最优。”腾讯云文件存储产品负责人马文霜表示。我们可以想象,如果维修站一下子来了太多需求,也会发生拥挤。腾讯云的高性能方案会智能把数据分层,最常用的轮胎(数据)放前排,没那么常用的,稍微放远一点,这样可以通过调度提升速度;也可直接把放轮胎的位置快速扩容,把所有轮胎都放到第一排,无论有多少车来都可以秒换轮胎。HCC高性能计算集群只是其中之一。今年,腾讯云还推出了向量数据库TencentCloud VectorDB等,这也被认为是大模型的“刚需”基础设施。一步步地从底层的服务器、框架都自研完成,再到如今“混元”的推出,腾讯的大模型产品矩阵已经初现雏形,路途依然漫长。“大模型是一场马拉松,目前才跑到一公里,To B业务的渗透,可能都是以十年作为单位。”汤道生如此形容。
