
©作者 | 汤凯华
单位 | 南洋理工大学
研究方向 | 计算机视觉
离开学校加入公司的业务部门已经半年多了,往后应该会努力抽时间做点开源项目,但暂时没什么计划再发一作论文了。这次介绍下我和我(前)实验室一位非常优秀的学弟 beier 合作的一篇 NeurIPS 2023 论文《Generalized Logit Adjustment: Calibrating Fine-tuned Models by Removing Label Bias in Foundation Models》,算是我入职前在学术界最后的回响吧。这次学弟的文章主要尝试解决我做长尾问题期间的一个始终萦绕在我脑袋里的疑虑,我觉得长尾领域最大的坎在于明明在研究一个普世的问题,但是学术界把问题模型简化后做出来的算法却只能在精心设计的实验数据集上生效。这次和学弟合作的这篇工作得益于模型自监督预训练带来的优秀 OOD 效果和我们提出的 GLA 算法对预训练模型在下游任务上偏见的矫正,我们第一次基于长尾问题本身的特性设计出了一个通用的提点算法,不仅能在狭义的传统 LT 数据集上生效,也能用于其他非 LT 设定的任务,比如我们的算法可以提升模型在原始的 ImageNet 测试集的效果,还有一些few-shot等其他任务。
论文链接:
https://arxiv.org/pdf/2310.08106.pdf
https://github.com/BeierZhu/GLA
大模型时代的长尾分布研究该何去何从
在当下这个大模型群星闪耀的时代,想必过去两三年中关注长尾任务的同学都面临着何去何从的困惑。长尾问题固然普世,除了狭义的类间长尾还有广义长尾问题 [1],但过去几年学术界中研究的主流长尾算法却并不同样普世。以最常见的图像长尾分类任务为例,要想大多数长尾分类算法能够生效,首先训练过程中的长尾分布就必须是显性的,要通过统计具体的类别分布来实现去偏。而大模型成功的根基,却恰恰也给传统长尾算法关上了大门,因为大模型所依赖的自监督预训练无法为下游任务提供一个显性的长尾分布去矫正。以大语言模型(如 GPT 等)和多模态模型(如 CLIP 等)为例,即便近来有一些论文尝试去研究大模型在下游任务微调时的下游数据偏见问题,但却并没有工作能够解决大模型预训练阶段本身的数据不均衡问题。但我们都知道在海量的预训练数据之下,数据的长尾分布是必然的。之所以鲜有人尝试去研究自监督预训练阶段本身的数据偏见,是因为要想在大模型的自监督预训练中研究长尾问题存在三大挑战:其一,原始文本数据的歧义性导致无法精准的统计类别的分布。比如以 CLIP 为例,其预训练目标是将图片与文本配对,而下游的视觉端 backbone 可以用作图像分类任务,但此时如果下游是一个 {human, non-human} 的二分类,我们并不能直接用 human 关键词的出现与否作为预训练数据分布的统计标准,比如包含 a worker 的图片虽然没有 human 这个词但也应该被统计为 human,因此文本天然的歧义和多意会给长尾分布研究带来极大的困难和偏差。其二,预训练任务与下游任务的弱耦合导致无法明确数据分布的统计方式。大模型的强大之处在于可以通过一个简单有效的预训练支撑花样百出的下游任务,然而这却大大增加了研究预训练数据偏见对下游任务影响的难度。比如 GPT 等大语言模型的预训练是预测下一个或是缺失的 Token,虽然我们可以统计 Token 的词频,但如果我们的下游任务是对文本的语气进行三分类 {positive, neutral, negative}。此时单纯统计 positive,neutral 和 negative 这三个词在预训练中的词频显然并不完全合适,因为这几个词出现的场景并非都是语气分类,要想精准统计不仅困难,其具体的下游任务更是无法在预训练阶段知晓的(下游任务太多了,模型提供者并不能知道模型被其他人拿到后会如何使用)。最后,也是最重要的,预训练数据的保密性也是不得不考虑的问题,出于用户隐私和商业机密的考量,一个开源公司即便开放了大模型参数往往也不会开放预训练数据,这使得研究预训练数据的分布变得几乎不可能。这也是目前鲜有该方面研究的主要原因之一。而在我们最新的工作中,我们不仅实现了在下游任务直接估计预训练的偏见,更是完全规避了对预训练数据本身的访问,使得我们可以在只有模型权重没有预训练数据的情况下实现对自监督预训练模型的去偏。
自监督预训练引入的数据偏见
▲ 图一:自监督预训练阶段引入的长尾数据偏见(可从 zero-shot 分类效果看出其对模型效果的影响)
目前大多数预训练模型鲁棒性相关的研究中,他们往往会把自监督预训练模型本身当作是一个无偏的基准,而强调模型在下游任务上微调时会引入下游任务的偏见,因此需要对下游任务去偏的同时尽可能保留预训练模型的鲁棒性,其中代表作有利用 zero-shot 模型和微调模型 Ensemble 的 WiSE-FT [2] 和利用梯度约束的 ProGrad [3]。但正如我上文说的,预训练数据的偏见同样无法忽视,这导致上述模型从理论上便不可能是最优的。事实上早在两年前,长尾问题领域便有人尝试利用自监督学习来提取特征,并认为无需显性标注的自监督 loss 可以大大缓解模型的长尾偏见问题。于是在我们的工作开始前,我们首先便要推倒这个假设。自监督预训练并不是一味万能药。如图一所示,我们将 CLIP-ViT/B16 预训练模型在下游的 ImageNet 测试集上的分类效果按我们估计的类别分布(可视化中进行了平滑处理)进行排序,我们发现自监督预训练模型同样有着明显的长尾偏见(zero-shot 结果),尾部类别的准确率会有明显的下滑。尤其是当我们将 zero-shot 结果和微调结果(fine-tune)对比时,我们就会看到他们的头部类别效果相当,而尾部类别 zero-shot 模型明显更差,也就是说自监督预训练模型的长尾问题其实很严重,模型在下游任务上微调时其实类似于在一个更均衡的数据集上微调去提升尾部效果。此时单纯 zero-shot 和 fine-tune 的 Ensemble 模型 WiSE-FT 更像一个 Trade-off,用尾部的损失去提升头部性能。而我们提出的 Generalized Logit Adjustment(GLA)通过在 Ensemble 之前先消除预训练 zero-shot 模型的长尾偏见来有效的实现了头尾全分布的同时提升。而我们之所以叫 Generalized Logit Adjustment 是为了致敬在经典的狭义长尾分布任务上的一个非常优雅且有效的算法 Logit Adjustment [4]。之所以无法简单的套用到自监督预训练上,其实最重要的一个难点就是我上面说到的预训练分布估计了。而仅利用模型参数不获取预训练数据就能在下游任务上估计预训练阶段数据偏见的算法也是我们文章的主要贡献之一。预训练数据中下游任务的类别分布估计
在本文中,我们主要以 CLIP 为引子,讨论以图文对比学习作为自监督预训练的多模态模型(主要是视觉端),不过本文提出的算法也可以推广至以文本自监督预训练为基础的大语言模型在下游文本分类任务上的偏见估计问题。在给出本文提供的预训练阶段数据偏见估计算法之前,我们需要回顾一篇我非常推崇的 Google 的 Logit Adjustment 长尾算法。在不考虑类内不均衡 OOD 样本的情况下,Logit Adjustment 研究已经从理论上提供了非常优雅的最优解:传统分类问题的概率模型 可以通过贝叶斯分解为如下形式 。那么在训练集与测试集独立同分布(IID)的情况下,我们自然而然可以得到如下的假设:,也就是说对于分类模型 ,唯一的类别 bias 来自 中的第二项 。那么问题就简单了,我们可以直接通过 来将类别分布从训练分布更改为测试分布。如果以类别均衡的验证集上的结果作为模型在无偏见下的表现的衡量标准, 就是平均分布,那么我们就可以去掉最后一项 。基于上文的 Logit Adjustment 长尾算法,我们不难发现,只要能给出自监督预训练模型的分布 ,我们就可以得到模型在类别均衡验证集上的理论最优解(给定模型 backbone 下)。那么换而言之,我们也可以利用这一特性来反向计算 ,如图二所示,只要能提供一个额外的类别均衡的子集,我们就可以通过最小化 Risk 去学习一个对模型输出的 logits 的偏置项,即通过最小化均衡子集上的误差去估计 。详细的理论推导和最优保证请参考我们的原文和原文的补充材料。

▲ 图二:以 Logit Adjustment 推导结果的理论最优解为前提,反向通过一个均衡子集去估计偏置项。
基于上述预训练偏见估计的算法,我们不仅不需要获取预训练数据,更不需要预训练过程是严格的传统分类 loss,任意分类模型都可以仅仅通过权重本身在一个均衡子集上估算出其训练阶段积累的偏见。为了更好的体现我们的去偏效果,我们也可视化了我们的去偏算法在 CLIP zero-shot 模型的去偏效果,详见图三。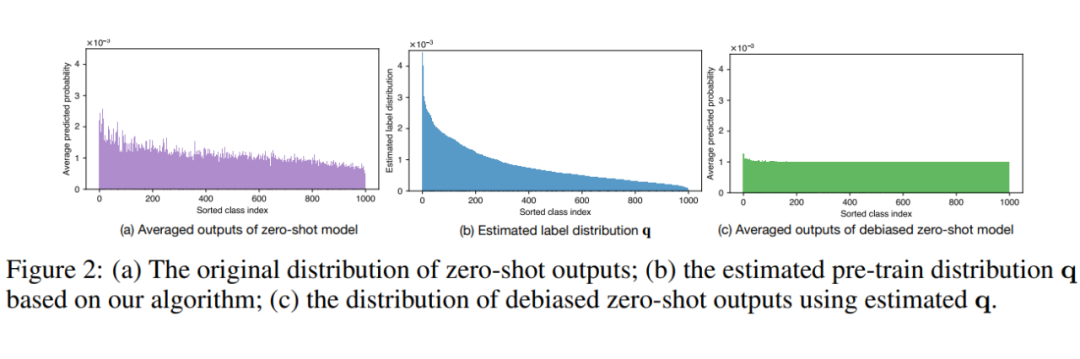
▲ 图三:模型在 CLIP 模型的 zero-shot 输出结果上的去偏效果通用Logit矫正算法(GLA)应用于任意下游数据分布上述偏见估计算法虽然提供了解决模型在 zero-shot 设定下的预训练偏见矫正问题,但是其取得的最优仅限于类别均衡的下游数据。但目前最优的模型还是利用 zero-shot 模型和微调模型 Ensemble 的 WiSE-FT [2],因为他们除了解决类间的不均衡,还通过微调更好的适配了下游数据分布 和 。那么微调模型的偏见又该如何解决呢?如果下游任务提供的微调数据本身还带有不均衡分布 ,且往往 ,我们还需要额外对微调模型 去偏,这里我们略过具体的推导和理论分析,先给出结论:我们认为如果微调模型在下游数据上收敛后,其所带的偏见就是下游数据 的偏见,可以用原始 Logit Adjustment 解决。综上,我们提出的 Generalized Logit Adjustment 框架就可以总结为如下公式: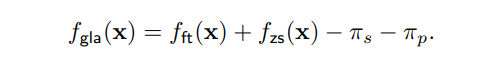
其中 为原始预训练模型的 zero-shot 预测, 为预训练模型在任意下游分布上微调后的预测, 为下游微调数据的分布(可直接统计), 为预训练模型累计的偏见(通过第三节提出的算法间接估计),而 就是最后的无偏最优估计。我们新提出的 GLA 算法在保留了原始 LA 算法的优雅和简介的同时,将该算法覆盖到更复杂的预训练+微调融合场景,解决了自监督预训练模型无法估计预训练数据偏见的问题。值得注意的是,GLA 算法据我所知是首个能“真正体现”长尾问题广泛性的算法,该算法以长尾问题为切入点,但最后得到的模型不仅在长尾分类任务上有提升,更在经典分类任务与数据上,在 few-shot 任务上等都有提升。是第一个做到利用长尾算法提升传统分类任务的工作。经典分类场景(非 Long-Tailed,Few-shot 等细分场景):在传统分类设定上,我们利用 CLIP ViT-B/32 和 ViT-B/16 两个模型,在 ImageNet,CIFAR100,Stanford Cars 和 SUN397 上都取得了显著的提升: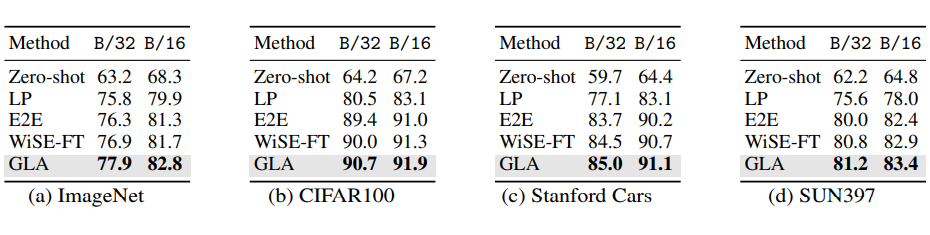
GLA 在 ImageNet 上提升的详细分析图表(根据估计分布将类别划分为 Head, Med, Tail,注意这里不是强行设置的 LT 设定,而是真实数据据分布);GLA 在多个基于 ImageNet 的鲁棒性测试子集上的效果,我们基本与 WiSE-FT 持平且互有胜负,证明我们的提升不是牺牲鲁棒性的过拟合。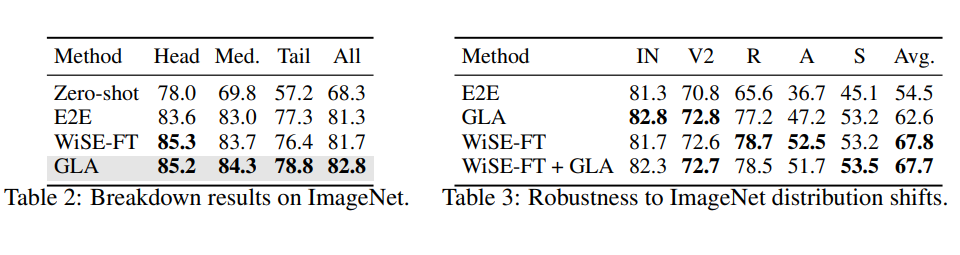
GLA 在 CLIP 的 11 个 few-shot 测试数据上的效果: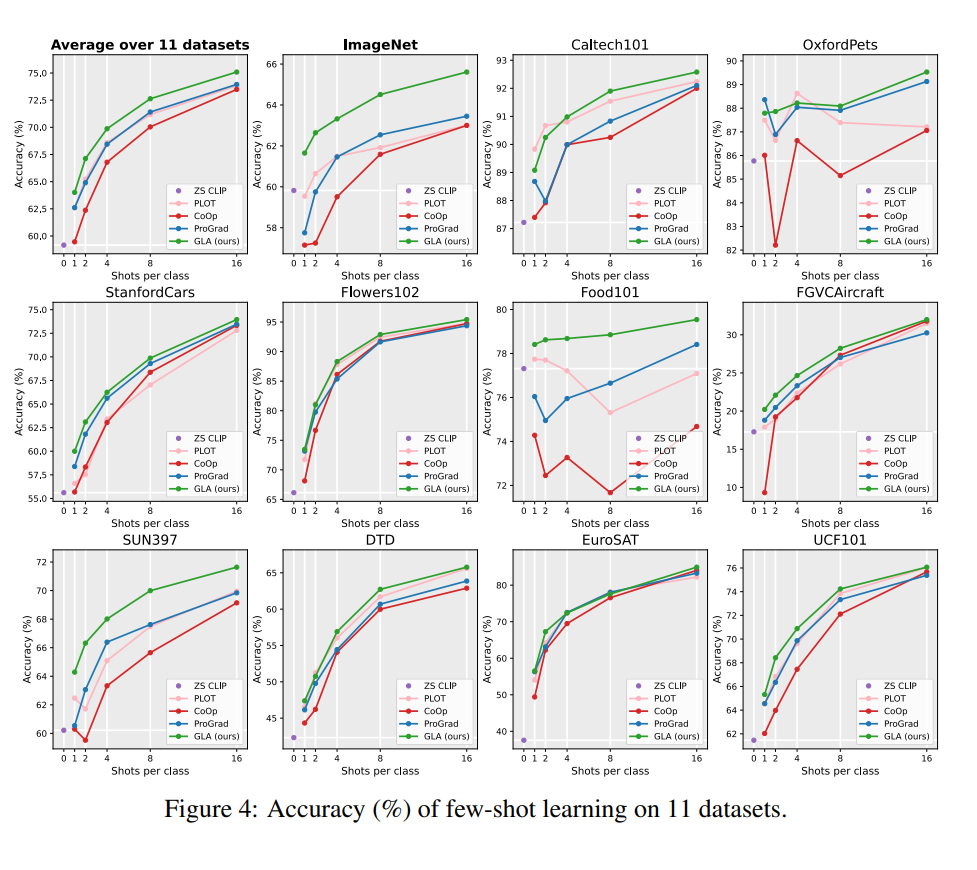
GLA 在 Few-shot 设定中的分布鲁棒性,以 16shot 为例;对比单纯的 Ensemble,我们可以发现 GLA 模型基本不会出现负提升的问题,这是因为我们对两个模型都进行了去偏,真正的做到了各取所长: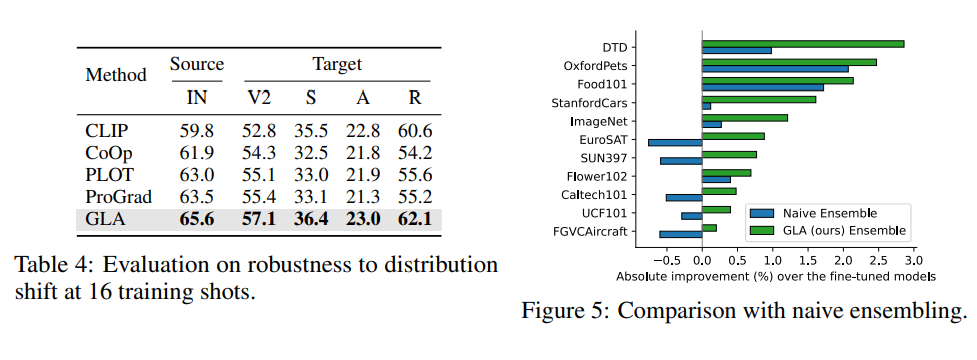
GLA 在传统 Long-Tail 设定数据集上提升: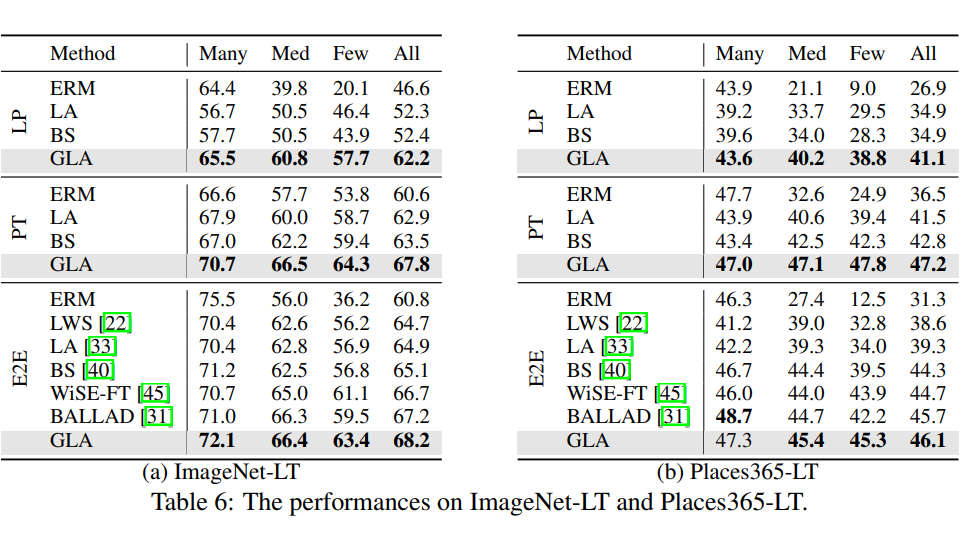
研究长尾问题对各个任务的具体影响可以说是贯穿我的博士生涯,从我研究开始该领域内便有个共识就是长尾问题是普世的,是任何实际问题都绕不开的坎。但奈何长尾问题却又无比复杂,不仅有类间长尾还有类内属性长尾,因此学术界不得不对任务做了很多简化,但这也导致了长尾问题明明是个普世的问题,该领域的算法却只能在精心设计的实验室环境下生效。
而如今大模型时代借助于预训练模型本身对于 OOD 的鲁棒性,以及我们提出的预训练偏见估计算法对于分布的矫正,我们终于拼上了最后一块拼图,第一次提出一个基于分布矫正和 Ensemble 的真正通用的长尾算法,可以在实际问题实际应用中提升各种任务的表现,而不仅限于精心设计的长尾数据集。
我们也希望这个研究可以为大模型时代的研究者打开一扇研究预训练分布偏见的大门,而不用因为无法访问预训练数据在大模型偏见研究的门口束手无策。希望这篇文章没有浪费大家的时间,能给大家以启发。
@inproceedings{zhu2023generalized,
title={Generalized Logit Adjustment: Calibrating Fine-tuned Models by Removing Label Bias in Foundation Models},
author={Zhu, Beier and Tang, Kaihua and Sun, Qianru and and Zhang, Hanwang},
journal={NeurIPS},
year={2023}
}
[1] https://arxiv.org/abs/2207.09504[2] https://arxiv.org/abs/2109.01903[3] https://arxiv.org/abs/2205.14865[4] https://arxiv.org/abs/2007.07314
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:[email protected]
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
