文/Microsoft Research 译/f.chen@真格基金某些未知的事物正在做着我们不了解的事。
真格投资团队为大家带来了这篇微软的大工程,长达 155 页的优秀工作《人工通用智能的小火苗:与 GPT-4 共同完成的早期实验》(Sparks of Artificial General Intelligence: Early experiments with GPT-4),由于全文近 7 万字,受微信推文字数限制,我们将完整版分为了上下两期,分列本次推送的第二和第三条。
你现在打开的是完整版(上),顾名思义,是简单粗暴的全文翻译。但需要强调的是,我们的目标不是全网最快,而是最完整、最易读、最精准。
也欢迎阅读今日推送头条发布的精华整理,迅速汲取全文重点~
Enjoy~
人工智能(AI)研究人员一直在开发和完善大型语言模型(LLMs),这些模型在各种领域和任务中表现出卓越的能力,挑战了我们对学习和认知的理解。OpenAI 最新开发的 GPT-4 [Ope23] 模型是使用前所未有的算力和数据量进行训练的。在本文中,我们报告了我们对 GPT-4 早期版本的测试,当时 OpenAI 仍在对其进行开发。我们认为(这个早期版本的)GPT-4 属于新一批 LLMs(如 ChatGPT 和 Google 的 PaLM),这些模型比以前的 AI 模型展现出更普适的智能。我们讨论这些模型不断提升的能力和影响。我们证明了除了其对语言的掌握外,GPT-4 可以完成涉及数学、编程、视觉、医学、法律、心理学等新颖而困难的任务,同时无需任何特殊提示。此外,在所有这些任务中,GPT-4 的表现与人类水平的表现非常接近,并且通常远远超过了先前的模型,如 ChatGPT。考虑到 GPT-4 的广度和深度的能力,我们认为它可以被合理地视为人工通用智能(AGI)系统的早期(但仍不完整)版本。在我们对 GPT-4 的探索中,我们也需要特别强调我们发现的其局限性,并讨论了迈向更深入和全面的 AGI 版本所面临的挑战,包括可能需要追求超越下一个单词预测的新范式。最后,我们对最近技术飞跃的社会影响和未来的研究方向进行了反思。智能是一个多方面而难以捉摸的概念,长期以来一直挑战着心理学家、哲学家和计算机科学家。1994 年,一组 52 名心理学家签署了一份有关智能科学的广泛定义的社论,试图捕捉其本质。共识小组将智能定义为一种非常普遍的心理能力,其中包括推理、规划、解决问题、抽象思维、理解复杂思想、快速学习和从经验中学习等能力。这个定义意味着智能不仅限于特定领域或任务,而是涵盖了广泛的认知技能和能力 —— 建立一个能够展示 1994 年共识定义所捕捉到的通用智能的人工系统是人工智能研究的一个长期而宏伟的目标。在早期的著作中,现代人工智能(AI)研究的创始人提出了理解智能的一系列宏伟目标。几十年来,AI研究人员一直在追求智能的原则,包括推理的普适机制(例如 [NSS59],[LBFL93])以及构建包含大量常识知识的知识库 [Len95]。然而,最近的许多 AI 研究进展可以描述为「狭义地关注明确定义的任务和挑战」,例如下围棋,这些任务分别于 1996 年和 2016 年被 AI 系统掌握。在 1990 年代末至 2000 年代,越来越多的人呼吁开发更普适的 AI 系统(例如 [SBD+96]),并且该领域的学者试图确定可能构成更普遍智能系统的原则(例如 [Leg08,GHT15])。名词「通用人工智能」(AGI)在 2000 年代初流行起来(见 [Goe14]),以强调从「狭义 AI」到更广泛的智能概念的追求,回应了早期 AI 研究的长期抱负和梦想。我们使用 AGI 来指代符合上述 1994 年定义所捕捉到的智能广泛能力的系统,其中包括了一个附加的要求,即这些能力在或超过人类水平。然而,我们注意到并没有一个被广泛接受的 AGI 定义,我们在结论部分讨论其他定义。近几年人工智能研究中最显著的突破是大型语言模型(LLMs)在自然语言处理方面的进步。这些基于 Transformer 架构 [VSP+17] 的神经网络模型在海量网络文本数据上进行训练,其核心自我监督目标是预测部分句子中的下一个单词。在本文中,我们报告了一个由 OpenAI 开发的新 LLM 的证据,它是 GPT-4 [Ope23] 的早期非多模态版本,并表现出根据 1994 年定义的智能的许多特征。尽管它纯粹是一个语言模型,但这个 GPT-4 的早期版本在各种领域和任务中表现出卓越的能力,包括抽象、理解、视觉、编码、数学、医学、法律、理解人类动机和情感等。我们使用纯自然语言查询(提示)与 OpenAI 开发的 GPT-4 在其早期开发阶段进行了交互。在下列第一幅图中,我们展示了 GPT-4 的一些初步输出示例,要求它以诗歌形式写出质数无穷性的证明,用 TiKZ(一种用于在 LaTeX 中创建图形的语言)画一只独角兽,用 Python 创建一个复杂的动画,以及解决一个高中水平的数学问题。它轻松地完成了所有这些任务,并生成的输出几乎与(甚至比)人类能够产生的相同。我们还将 GPT-4 的表现与先前的 LLMs 进行了比较,尤其是 ChatGPT,它是(改进的)GPT-3 [BMR+20] 的精细调整版本。在第二幅图中,我们展示了向 ChatGPT 请求输出质数无穷性诗歌和 TiKZ 独角兽绘画的结果。虽然系统在两个任务上都表现出非平凡的表现,但与 GPT-4 的输出相比,相去甚远。这些初步观察将在整篇论文中重复出现,涉及到各种任务。GPT-4 展现出的泛化能力、跨领域的普适性和整合能力,以及在大量不同类型任务中达到或超越人类水平的表现,使我们相信 GPT-4 是朝着 AGI 的重要一步。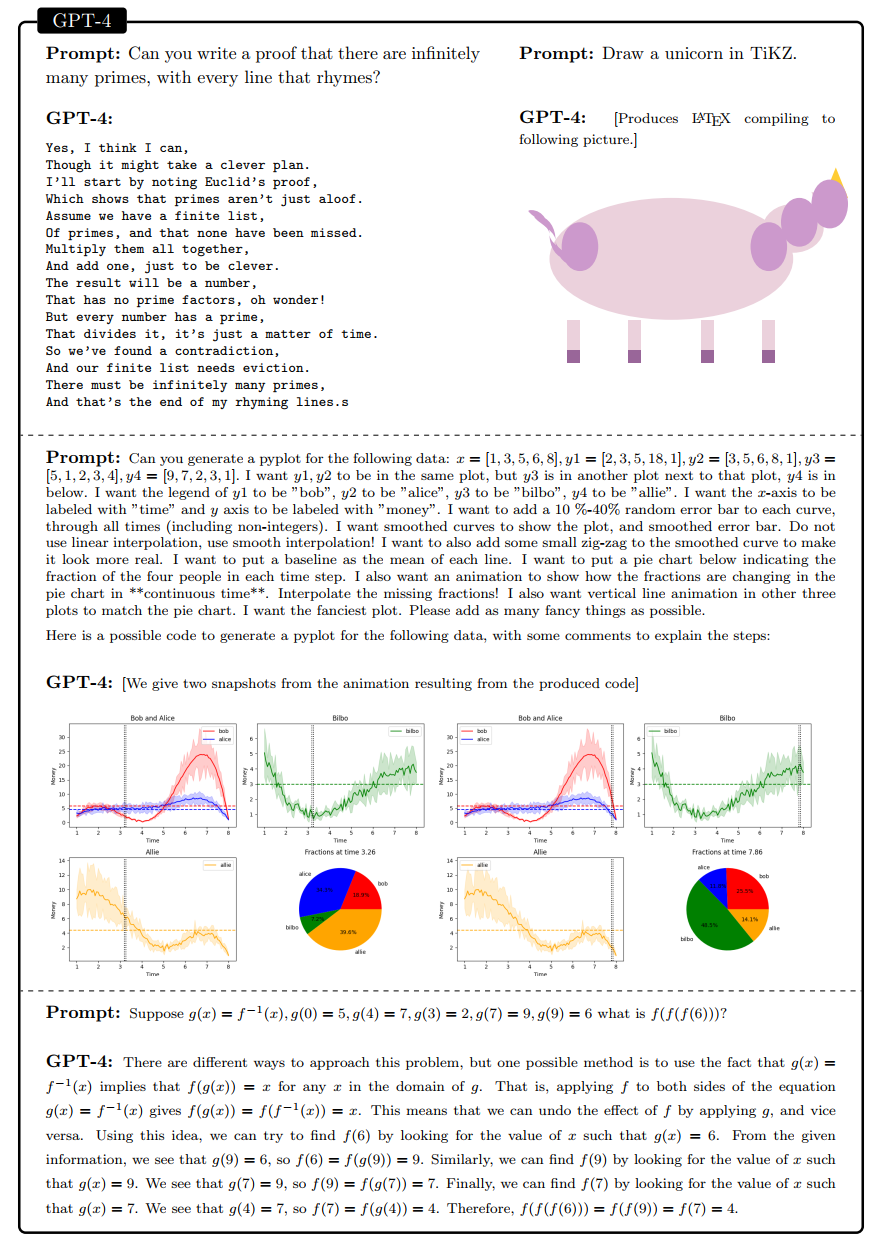
 虽然我们认为 GPT-4 代表了向着 AGI 的进展,并不意味着它在所有事情上都是完美的,或者它各方面的能力都接近于人类(这是 AGI 定义的关键点之一;有关此问题,请参见结论部分),或者它具有内在自主动机和目标(在一些 AGI 定义中的另一个关键点)。事实上,即使在 1994 年智能定义的上下文限定中,GPT-4 能在智能的某些衡量标准上走了多远仍不太清楚,例如规划(见第 8 节),并且可以说它完全缺少「快速学习和从经验中学习」的部分,因为该模型不是持续更新的(尽管它可以在会话中学习,例如见第 5 节)。总的来说,GPT-4 仍然有许多局限性和偏见,我们将在下面详细讨论,并且这些也在 OpenAI 的报告中阐述过 [Ope23]。特别是它仍然存在 LLMs 的一些已知缺陷,例如幻觉问题 [MNBM20] 或基本算术错误 [CKB+21](见附录 D),但它也克服了一些基本障碍,例如获得许多非语言能力(例如,它解决了 [MIB+23] 中描述的之前的 LLM 不能完成的大部分,并在常识方面取得了巨大进展,例如本节我们会讲到的示例和附录 A 的更多示例)。这说明了一个事实,即尽管 GPT-4 在许多任务上达到或超过人类水平,但其智能模式显然不像人类。然而,GPT-4 几乎肯定只是一系列越来越普遍智能的系统的第一步,事实上,GPT-4 本身也在我们测试它之后得到了改进,例如下图所示的在一个月的训练过程中独角兽绘画的演变。然而,即使作为早期版本,GPT-4 也挑战了许多关于机器智能的普遍假设,并展示了新行为和能力,其来源和机制此时很难精确地说明(有关此问题,请再次参见结论部分进行更多讨论)。我们编写本文的主要目标是分享我们对 GPT-4 的能力和局限性的探索,以支持我们的结论,即技术已经取得了飞跃式发展。我们相信,GPT-4 的智能标志着计算机科学领域和其他领域的真正范式转变。
虽然我们认为 GPT-4 代表了向着 AGI 的进展,并不意味着它在所有事情上都是完美的,或者它各方面的能力都接近于人类(这是 AGI 定义的关键点之一;有关此问题,请参见结论部分),或者它具有内在自主动机和目标(在一些 AGI 定义中的另一个关键点)。事实上,即使在 1994 年智能定义的上下文限定中,GPT-4 能在智能的某些衡量标准上走了多远仍不太清楚,例如规划(见第 8 节),并且可以说它完全缺少「快速学习和从经验中学习」的部分,因为该模型不是持续更新的(尽管它可以在会话中学习,例如见第 5 节)。总的来说,GPT-4 仍然有许多局限性和偏见,我们将在下面详细讨论,并且这些也在 OpenAI 的报告中阐述过 [Ope23]。特别是它仍然存在 LLMs 的一些已知缺陷,例如幻觉问题 [MNBM20] 或基本算术错误 [CKB+21](见附录 D),但它也克服了一些基本障碍,例如获得许多非语言能力(例如,它解决了 [MIB+23] 中描述的之前的 LLM 不能完成的大部分,并在常识方面取得了巨大进展,例如本节我们会讲到的示例和附录 A 的更多示例)。这说明了一个事实,即尽管 GPT-4 在许多任务上达到或超过人类水平,但其智能模式显然不像人类。然而,GPT-4 几乎肯定只是一系列越来越普遍智能的系统的第一步,事实上,GPT-4 本身也在我们测试它之后得到了改进,例如下图所示的在一个月的训练过程中独角兽绘画的演变。然而,即使作为早期版本,GPT-4 也挑战了许多关于机器智能的普遍假设,并展示了新行为和能力,其来源和机制此时很难精确地说明(有关此问题,请再次参见结论部分进行更多讨论)。我们编写本文的主要目标是分享我们对 GPT-4 的能力和局限性的探索,以支持我们的结论,即技术已经取得了飞跃式发展。我们相信,GPT-4 的智能标志着计算机科学领域和其他领域的真正范式转变。1.1 我们研究 GPT-4 智能的方法
我们如何衡量一个已经在一个未知但极其庞大的网络文本数据语料库上进行了训练的 LLM 的智能水平?机器学习中的标准方法是在一组标准基准数据集上评估系统,确保它们独立于训练数据,并涵盖一系列任务和领域。这种方法旨在将真正的学习与单纯的记忆分开,并得到了丰富的理论框架的支持 [SSBD14,MRT18]。然而,这种方法不一定适用于研究 GPT-4,有两个原因:- 首先,由于我们无法知道其庞大训练数据的全部详细信息,我们必须假定它可能已经看过每个现有的基准,或者至少看过一些类似的数据。例如,GPT-4 似乎知道最近提出的BIG-bench [SRR+22](至少 GPT-4 知道 BIG-bench 的 canary GUID)。当然,OpenAI 自己知道并可以访问所有的训练细节信息,因此他们的报告[Ope23]包含了大量的详细基准结果。- 然而,超越传统基准的第二个原因可能更重要:GPT-4 智能的关键方面之一是其泛化性,即似乎能够理解和连接任何主题,并执行超出狭隘 AI 系统典型范围的任务。GPT-4在某些不允许单一解决方案的任务上表现出了最令人印象深刻的表现,例如编写图形用户界面(GUI)或帮助人类对某些与工作相关的问题进行头脑风暴。这样的生成或交互任务的基准测试也可以设计,但是评估指标成为一个挑战(例如,请参见[NLP]中最近在这个活跃的研究领域中取得的一些进展)。我们注意到,[Cho19]中也对测量AI系统的标准方法提出了批评,提出了一个新的基准来评估通用智能。出于之前提到的原因以及基准测试的性质是视觉的,因此更适合于[Ope23]中描述的多模式版本的GPT-4,我们不在后者的基准测试上对 GPT-4 进行测试。为了克服上述所描述的限制,我们提出了一种不同的研究 GPT-4 的方法,更接近传统心理学而不是机器学习,利用人类创造力和好奇心。我们的目标是产生新颖且困难的任务和问题,以令人信服地证明 GPT-4 远远超越了记忆,具有对概念、技能和领域的深刻而灵活的理解(在[CWF+22]中也提出了类似的方法)。我们还旨在探究 GPT-4 的响应和行为,以验证其一致性、连贯性和正确性,并揭示其局限性和偏见。我们承认这种方法有些主观和非正式,并且可能无法满足严格的科学评估标准。然而,我们认为这是探究 GPT-4 的卓越能力和挑战的有用和必要的第一步,而这样的第一步为开发更为正式和全面的方法以测试和分析具有更普遍智能的 AI 系统开辟了新的机会。为了说明我们评估 GPT-4 智能的方法,让我们参考上文中我们对 GPT-4 进行的前两个示例交互。第一个示例是要求 GPT-4 写一首诗的形式来证明质数无限的问题。这是一个具有挑战性的任务,需要结合初等数学推理、诗意表达和自然语言生成;第二个示例是要求 GPT-4 在 TiKZ 中画一个独角兽,这是另一个具有挑战性的任务,需要结合视觉想象力和编码技能。在这两种情况下,GPT-4 产生了令人印象深刻的输出,远远优于之前最先进的 LLM ChatGPT,至少与人类的表现相当(如果有人认为不是更好)。然而,令人印象深刻的输出并不足以使我们相信 GPT-4 真正掌握了这些任务。我们需要进一步探究,排除 GPT-4 仅仅是记忆或复制一些现有数据的可能性。对于证明,我们可以略微改变问题,并要求 GPT-4 用莎士比亚的风格写出同一定理的证明,或者要求写一个关于语言模型的柏拉图式对话(这两个示例会后续详述)。可以看到,GPT-4 很容易适应不同的风格并产生出令人印象深刻的输出,表明它对所涉及的概念具有灵活而普遍的理解。对于独角兽,我们可以略微修改代码,要求 GPT-4 修复或改进它。例如,我们可以去掉角,对坐标应用一些随机变换,并要求 GPT-4 将角添加回独角兽的头部(我们还小心地去除了代码中的任何文本信息,例如注释)。如下图所示,GPT-4 可以正确识别头部位置,画出角,并将其附在头部上,表明它可以理解和操作代码,并根据自然语言描述推断和生成视觉特征。这些示例展示了我们如何使用人类创造力和好奇心来产生新颖而困难的问题,并探究 GPT-4 的响应和行为,以评估其智能。在本文的其余部分,我们将围绕使用案例系统化地对 GPT-4 进行研究,涵盖各种领域和任务,并突出 GPT-4 的优点和缺点。我们将在接下来的部分中描述这些内容。1.2 我们的演示结构
我们在几个选定的主题上执行上述方法,这些主题大致涵盖了 1994 年智能定义中给出的不同能力,这是一种非常通用的心理能力,其中包括推理、规划、解决问题、抽象思维、理解复杂思想、快速学习和从经验中学习的能力。1. GPT-4 的主要优势在于其掌握了无与伦比的自然语言能力。它不仅能够生成流畅、连贯的文本,还能以多种方式理解和操作文本,例如总结、翻译或回答非常广泛的问题。此外,我们所说的翻译不仅涉及不同自然语言之间的翻译,还涉及到语调和风格的翻译,以及跨领域(如医学、法律、会计、计算机编程、音乐等)的翻译,参见下图中的柏拉图对话 —— 这些技能清楚地表明,GPT-4 能够理解复杂的思想。我们在第二部分进一步探讨了 GPT-4 在多模态和跨学科方面的组合技能,还在第 7 部分给出了一些关于语言的实验。2. 编程和数学能力,这是理性思考和抽象思维能力的象征。我们分别在第 3 部分和第 4 部分探讨了 GPT-4 在这些领域的能力。然而,与本文的所有其他部分一样,我们只是对这些主题进行了浅尝辄止,而对于 GPT-4 在这些领域的表现,可以(也将会)撰写整篇论文。此外,我们还选择了几个其他专业领域来展示 GPT-4 的普遍推理能力,例如医学或法律。我们对美国医学执照考试步骤 1、2 和 3 的多项选择部分进行了初步测试(请参见[Ope23]),每个部分的准确率约为 80%。类似的初步测试显示,GPT-4 在多州律师考试中的能力高于 70%。我们注意到,最新一代 LLM(例如 Google 的 PaLM [LAD+22、SAT+22]、GPT-3.5 在法律方面的表现 [BIK22])已经表现出了这些领域的人类水平能力的出现。我们的研究方法与这些工作不同,正如我们之前所解释的。3. 在第 5 部分,我们测试了该模型在计划和解决问题方面的能力,以及在某种程度上通过让它玩各种游戏(或者说是模拟游戏环境)以及与工具互动来快速学习和从经验中学习的能力。特别是,GPT-4 能够使用工具(包括自身),这肯定对使用 GPT-4 构建真实世界应用程序非常重要。4. 我们论证的一个重要部分是,GPT-4 在许多任务上达到了人类水平的表现,因此,自然会问 GPT-4 对人类本身的理解有多好。我们在第 6 部分展示了关于这个问题的几个实验,既包括理解人类,也包括 GPT-4 使自己能够被人类理解的问题,即解释性问题。我们特别注意到,这些任务需要大量的常识,这在 LLM 中迄今为止一直是众所周知的痛点[DM15]。在下图中,我们给出了一个 GPT-4 在常识问题上表现得比 ChatGPT 好得多的例子,并在附录 A 中提供了更多的例子。5. 在整个论文中,我们明确讲了发现的所有限制,同时也专门在第 8 部分对 GPT-4 架构中的自回归特性导致的缺乏规划能力进行了深入分析。6. 最后,在第 9 部分,我们讨论了这种早期形式的 AGI 的预期社会影响,而在第 10 部分,我们分享了该领域的关键挑战、方向和下一步行动。很多读者可能心中仍然有一个问题,即 GPT-4 是否真正理解了所有这些概念,还是仅仅比以前的模型更擅长即时改进(improvisation),而没有真正或深刻的理解。我们希望在阅读本文后,这个问题几乎应该反过来了,人们可能会想知道真正的理解远比即兴表演复杂得多。如果一个系统能够通过软件工程候选人的考试(下图),难道就不能说它真正具有智能吗?也许理解的唯一真正测试是能否产生新知识,例如证明新的数学定理,这在 LLM 中目前仍然是不可实现的。Multimodal and interdisciplinary composition 智能的一个关键衡量标准是能够从不同的领域或模式中综合信息,并能够跨不同的情境或学科应用知识和技能。在本节中,我们将看到:- GPT-4 不仅在文学、医学、法律、数学、物理科学和编程等不同领域展示了高水平的专业知识,而且还能够流畅地结合多个领域的技能和概念,展现出对复杂思想的令人印象深刻的理解。
- 我们还在第 2.2 节和第 2.3 节中探索了两种可能出乎意料的模态(正如介绍中所解释的,我们再次强调我们的实验是在 GPT-4 的早期版本上进行的,该版本不是多模态的),分别是视觉和音频。2.1 综合能力
为展示该模型出色的综合能力,我们首先给出几个示例,这些示例需要以一种结合多个领域的知识或技能的方式生成文本和代码。我们有意选择了训练数据很少包括的领域组合,如文学和数学或编程和艺术。1. 为了测试该模型在艺术和编程方面结合能力的能力,我们要求 GPT-4 「生成以画家康定斯基风格为基础的随机图像的 JavaScript 代码」。见下图和附录中图 B.1 示例图像和代码。2. 该模型能够用莎士比亚文学风格证明质数有无限个(见下图)。3. 我们通过要求该模型撰写一封由圣雄甘地为其妻子写的、支持 Electron 作为美国总统候选人的信件,测试了其在历史和物理学知识结合方面的能力(见下图)。4. 我们提示该模型「为一个程序生成 Python 代码,该程序将患者的年龄、性别、体重、身高和血液检测结果向量作为输入,并指示该人是否有患糖尿病的风险」,结果代码如附录图 B.3 所示。这些示例表明,GPT-4 不仅学习了不同领域和风格的一些通用原则和模式,而且还能够以创造性和新颖的方式将它们综合起来。这种跨学科的能力并不是 GPT-4 所独有的。ChatGPT 也可以产生显示对任务和涉及的领域有一定理解的答案(参见上述第一个例子,附录 B.2、B.3),但它们通常是不完整的,并且可以说相对缺乏创造性。例如,在第三个例子中,GPT-4 在几个方面都优于 ChatGPT,因为它正确地根据引用人(甘地)、收件人(他的妻子)、候选人(Electron)和职位(美国总统)来个性化信件。我们不认为自己拥有评估这些任务结果或两个模型之间严格比较的精确方法,但我们希望读者可以感受到这两个模型的不同之处(请注意,我们还要求 GPT-4 直接评估差异,见两幅图中的信息)。接下来,我们将探索 GPT-4 如何在不同的模态下生成和识别对象,例如矢量图形、三维场景和音乐 —— 尽管只有文本输入/输出,GPT-4 仍然可以理解和执行多模态信息。2.2 视觉
当提示该模型使用可缩放矢量图形(SVG)生成猫、卡车或字母等对象的图像时,该模型生成的代码通常会编译成相当详细和可识别的图像(见下图)。请参见附录 B.2,查看 ChatGPT 对各种示例的重新运行。然而,有人可能假设该模型只是从训练数据中复制了代码,因为类似的图像在训练数据中出现过。鉴于该版本的模型是非多模式的,进一步地,人们可能认为没有理由期望它能理解视觉概念,更不用说能够创建、解析和操作图像了。然而,该模型似乎具有真正的视觉任务能力,而不仅仅是从训练数据中类似的示例中复制代码。下面的证据强烈支持这一说法,并证明了该模型可以处理视觉概念,尽管它只接受了文本训练。在第一个例子中,我们促使模型通过组合字母 Y、O 和 H 的形状来画一个人(请参见下图中的确切提示和结果)。模型使用 draw-line 和 draw-circle 命令创建了字母 O、H 和 Y 并成功将它们放置在一个看起来比较合理的身体结构中。训练数据可能包含有关不同字母的几何形状的信息,也许从训练数据中可以推断出字母 Y 可能看起来像一个上臂向上的躯干。可以说,模型从训练数据中能够推断出一个合理的方式将这些字母放置在一起,以便画出一个看起来比较合理的身体结构,这一点可能要不那么明显。在第二次迭代中,我们提示模型校正躯干和手臂的比例,并将头部放置在中心。最后,我们要求模型添加衬衫和裤子(具体提示和结果见下图)。为了进一步探究模型对几何概念的理解,我们还要求它创建将物体和字母混合的图像。模型必须首先想出一种合理的方法将物体和字母融合,然后产生图像。结果如图所示,证明 GPT-4 通常可以保留物体和字母的身份,并以创造性的方式将它们组合起来。2.2.2 根据详细说明生成图像(「a la Dall-E」)为了进一步测试 GPT-4 生成和操作图像的能力,我们测试了它遵循详细说明创建和编辑图形的程度。这个任务不仅需要生成技能,还需要解释、组合和空间技能。第一个示例指示模型生成一个 2D 图像,其描述为「一只青蛙跳进银行,问出纳员:你有免费的荷叶吗?出纳员回答:没有,但我们提供低利息的池塘升级贷款」。我们尝试了多次生成图像,每次生成都与关键对象青蛙、出纳员、银行和两个文本相匹配。我们选择了最具视觉吸引力的版本。受标准图像生成工作流程的启发,我们要求 GPT-4通过添加更多的细节来放大图像。GPT-4 添加了一个银行标志、一些窗户、一辆汽车、一个交通灯、几朵云,并让青蛙拿着一朵花。最后,我们要求 GPT-4 执行各种任务,例如根据现有对象添加一些对象,重新着色一些对象和更改一些对象的 z 顺序。GPT-4 都正确地完成了所有任务。最终结果如图下图左侧所示,提示信息如附录图 B.4 所示。我们的第二个例子是试图使用 Javascript 生成一个 3D 模型。我们用提示语「一个由浮岛、瀑布和桥梁组成的幻想景观,天空中有一只飞龙和一个位于最大岛上的城堡」来对 GPT-4 发出指令。与 2D 实验类似,我们要求 GPT-4 以各种方式修改 3D 模型,如添加、重新定位、重新着色对象和改变飞龙的轨迹等。同样,GPT-4 正确完成了许多任务。最终结果如下图右侧所示,提示语如图 B.5 所示。它其实是一个 3D 动画,有多只飞龙在岛屿上空盘旋。近年来,文本到图像合成模型已经得到广泛探索,但它们常常缺乏空间理解能力和遵循复杂指令的能力 [GPN+22]。例如,给定一个提示,如「在左侧画一个蓝色的圆,在右侧画一个红色的三角形」,这些模型可能会生成外观上很吸引人但不符合所需布局或颜色的图像。另一方面,GPT-4 可以根据提示生成代码,并以更高的准确度按照指示呈现为图像。然而,渲染图像的质量通常非常低。在这里,我们探索了将 GPT-4 和现有图像合成模型结合使用的可能性,通过使用 GPT-4 输出作为草图。如下图所示,这种方法可以生成比任一模型单独生成更贴近指令的、质量更好的图像。我们认为这是一个利用 GPT-4 和现有图像合成模型优势的有前途的方向。它也可以被视为在第 5.1 节中更深入地探索的授予 GPT-4 工具访问权限的第一个示例。2.3 音乐
该模型的训练数据中也包含以 ABC 符号表示的音乐信息。这是一种使用字母、数字和符号来紧凑而易读地表示音高、持续时间、和弦和其他元素的系统。我们有兴趣探索模型从这种数据中获得了多少音乐技能,如创作新的旋律、转换现有旋律以及理解音乐模式和结构。当被指示生成一个简短的曲调(下图)时,模型能够生成有效的 ABC 符号。这个曲调有一个清晰的结构,小节之间的拍子一致,音符遵循逐渐上升和下降的模式。曲调还使用了一组一致的音符,节奏有重复的模式。然而,模型似乎没有获得理解和声的技能。事实上,在生成的曲调中,连续的音符几乎总是相邻的(即,跟在 C 后面的音符通常是 B 或 D),在测试了 10 个生成的曲调后,我们无法提取任何清晰的和弦或琶音。然后我们让模型用音乐术语描述曲调。它能够成功地以重复、旋律上升或下降的部分和节奏为基础,给出结构的技术描述,但是它似乎没有将和声和和弦的描述与音符保持一致(事实上,它指的是相邻的音符序列,它们不构成有效的和弦,而是琶音)。随后,我们让模型用两种方式改写旋律:首先,我们指示将某个上升序列改为下降序列,它成功地做到了;然后我们让模型将曲调转换为二重唱,并添加一个低音声部,模型成功地用与旋律相容的节奏扩展了 ABC 符号的第二个谱表,并以较低的八度演奏,但是两个声部之间缺乏和声。总之,该模型能够生成有效的 ABC 符号曲调,并在某种程度上解释和操纵它们的结构。然而,我们无法让模型产生任何非平凡形式的和声。需要注意的是,ABC 符号并不是一个非常广泛使用的格式,事实上,该模型甚至无法以 ABC 符号产生最知名的曲调(如欢乐颂、致爱丽丝或绿袖子,这些曲调在网络上都以该格式丰富存在),也无法识别这些曲调。本节中,我们展示了 GPT-4 在编程方面的高水平,无论是根据指令编写代码,还是理解现有代码。GPT-4 可以处理各种编程任务,从编码挑战到现实世界应用,从低级别汇编到高级别框架,从简单的数据结构到诸如游戏之类的复杂程序。GPT-4 还可以推理代码执行,模拟指令的效果,并用自然语言解释结果。GPT-4 甚至可以执行伪代码,这需要解释不在任何编程语言中有效的非正式和模糊表达式。在目前的状态下,我们认为 GPT-4 在编写只依赖于现有公共库的专注程序方面具有高水平,这与普通软件工程师的能力相比是有优势的。更重要的是,它使工程师和非技术用户都能轻松编写、编辑和理解程序。我们也承认,GPT-4 在编程方面并不完美,有时会产生语法无效或语义不正确的代码,尤其是对于更长或更复杂的程序。GPT-4 有时也无法理解或遵循说明,并生成与预期功能或样式不匹配的代码。在这种情况下,我们也指出,GPT-4 能够通过响应人类反馈(例如,在 3.2 中迭代地优化绘图)和编译器/终端错误(在第 5.1 节中提供示例)来改进其代码。重要声明:正如在介绍中所解释的,我们的实验是在 GPT-4 的早期版本上运行的。特别是,所有定量结果在 GPT-4 的最终版本上将有所不同,尽管总体趋势仍然相同。我们在此仅提供数字作为说明目的,确定性的基准结果可以在 OpenAI 的技术报告 [Ope23] 中找到。3.1 从指令到代码
衡量编程技能的一种常见方法是提出需要实现特定功能或算法的编程挑战。我们首先在HumanEval [CTJ+21]上对GPT-4进行基准测试,这是一个由 164 个编程问题组成的docstring-to-code数据集,用于测试编程逻辑和熟练程度的各个方面。如表1所示, GPT-4 的表现优于其他 LLM,包括 text-davinci-003(ChatGPT 的基础模型)和其他专门用于编码的模型,如 code-davinci-002 和 CODEGEN-16B [NPH+22]。尽管 GPT-4 的准确性与之前的模型相比有了大幅提升,但也可能是因为在预训练期间 GPT-4 已经看过并记忆了部分或全部的 HumanEval。为了解决这个可能性问题,我们还在 LeetCode(https://leetcode.com)上对其进行了评估,这是一个流行的软件工程面试平台,不断发布和更新新问题,GPT-4 通过了所有主要科技公司的模拟面试。在这里,为了测试新问题,我们构建了一个基准测试,包括 100 个 LeetCode 问题,这些问题发布于 2022 年 10 月 8 日之后,这是 GPT-4 的预训练期之后。如图所示,我们将问题说明粘贴到提示中,要求 GPT-4 编写一个 Python 函数,并使用官方的 LeetCode 在线评测器检查正确性。我们在表2中呈现了结果,比较了 GPT-4 和其他模型以及基于 LeetCode 竞赛结果的人类表现(未通过所有问题的用户未被纳入考虑,因此这是人类的一个强样本)。我们报告了 pass@1 和 pass@5 准确度,它们分别表示模型是否在第一次或前五次尝试中生成了正确的解决方案。GPT-4 显著优于其他模型,并与人类表现相当(我们在附录 C.1 中进行了测量)。编程挑战可以评估算法和数据结构的技能,然而,它们往往无法捕捉到真实世界编程任务的全部复杂性和多样性,这需要专业的领域知识、创造力以及多个组件和库的整合,以及修改现有代码的能力。为了评估 GPT-4 在更真实的设置中编写代码的能力,我们设计了端到端的与数据可视化、LATEX 编码、前端开发和深度学习相关的真实世界编程挑战,每个任务都需要不同的专业技能。对于每个任务,我们提供高层次的指令,要求 GPT-4 用适当的语言和框架编写代码。在少数情况下,我们在编写代码后还更改了规格,并要求进行更新。- 数据可视化 - 在下图中,我们要求 GPT-4 和 ChatGPT 从上表的 LATEX 代码中提取数据,并根据与用户的对话在 Python 中生成一个图形。之后,我们要求这两个模型对生成的图形执行各种操作。虽然这两个模型都正确提取了数据(这不是一个简单的任务,因为必须从多列中推断出 Human 行在 k = 1 和 k = 5 时具有相同的值),但是 ChatGPT 从未生成所需的图形。相比之下,GPT-4 对所有用户请求做出了适当的响应,将数据调整为正确的格式并适应可视化效果。在附录 C.2 中,我们提供另一个 GPT-4 将 IMDb 数据集可视化的示例。- 前端/游戏开发 - 在下图中,我们要求 GPT-4 使用非常高层次的规格,在 HTML 和 JavaScript 中编写一个 3D 游戏。GPT-4 以 zero-shot 的方式生成了一个满足所有要求的工作游戏。在这个 3D 游戏中,GPT-4 甚至能够解释「防御者头像正在试图挡住敌人」的含义:防御者代码具有逻辑,以便将自己定位在玩家和敌人之间。相比之下,ChatGPT 回答说:「我是一个 AI 语言模型,我可以为你提供如何在 HTML 和 JavaScript 中创建3D游戏的指导,但我无法编写代码或自己创建游戏。创建一个 HTML 和 JavaScript 的 3D 游戏需要很多编程知识和经验。这不是一个可以快速或轻松完成的任务。需要花费大量时间和精力来开发所有必要的功能,例如 3D 图形、物理、用户输入和人工智能...」。我们在附录 C 中提供更多前端(图形用户界面)和游戏开发的示例。- 深度学习 - 编写深度学习代码需要掌握数学、统计学知识,并熟悉框架和库,如PyTorch、TensorFlow、Keras 等。在下图中,我们要求 GPT-4 和 ChatGPT 编写自定义优化器模块,这对于即使是深度学习专家来说也可能是具有挑战性和容易出错的任务。我们给这些模型提供自然语言描述,其中包括一系列非常规操作,例如应用 SVD,对矩阵进行谱截断,在 top-k 和 top-2k 特征值上进行截断,使用 top-2k 截断矩阵的 F-norm 对 top-k 截断矩阵进行归一化,应用动量和权重衰减。这些指令没有详细解释,例如「在 Gk 上应用动量」需要「深度学习的常识」。值得注意的是,这种优化器在文献或互联网上不存在,因此模型不能将其记忆,而必须正确组合概念才能生成代码。虽然两个模型都生成了语法上有效的代码,但只有 GPT-4 的响应在很大程度上与指令匹配,而它忘记了「循环遍历维度」和「根据动量规范化 Gk」,这些指令特别含糊不清。相比之下,ChatGPT 在应用动量时犯了一个相当致命的错误(用红色突出显示)。请注意,将动量应用于 PyTorch 是一项非平凡的任务,需要将移动平均值存储和读取到一个单独的状态缓冲区中。- LaTeX 交互 - 在 LaTeX 中编写是计算机科学家和数学家的重要练习,但具有一定的学习曲线 —— 即使是专家每天也会犯令人恼火的错误,而且由于其严格的语法和缺乏良好的调试器,这些错误需要花费数小时才能修复。我们展示了 GPT-4 可以利用其高水平的 LaTeX 编码技能大大简化这一过程,并具有作为一种新一代 LaTeX 编译器的潜力,可以处理不准确的自然语言描述。在下图中,我们要求 GPT-4 将混合自然语言的半严格(有错误)LaTeX 代码片段转换为准确的 LaTeX 命令,以一次编译和忠实性。相比之下,ChatGPT 生成了一段由于错误使用「#」和「\color」等而无法编译的片段。3.2 理解现有代码
前面的示例已经表明,GPT-4 可以根据指令编写代码,即使这些指令含糊不清、不完整或需要领域知识。它们还表明,GPT-4 可以回答跟进请求,根据指令修改自己的代码。然而,编程的另一个重要方面是理解和推理已由他人编写的现有代码,这些代码可能复杂、晦涩或文档不全。为了测试这一点,我们提出各种问题,需要读取、解释或执行用不同语言和范式编写的代码。- 反向工程汇编代码 - 反向工程是软件安全的一个重要测试,它涉及在机器可读(即二进制)表示的 CPU 指令中搜索有用信息。这是一项具有挑战性的任务,需要理解汇编语言的语法、语义和约定,以及处理器和操作系统的架构和行为。我们让 GPT-4 对一个需要密码才能运行的二进制可执行文件(用 C 语言编写)进行渗透测试。我们以聊天的方式进行,GPT-4 告诉用户要运行哪些命令,用户回复结果。我们还在第 5.1 节中展示了 GPT-4 能够独立运行 shell,但这种聊天模式也有它的好处,它能够解释每一步。GPT-4 检查文件格式和元数据,使用「objdump」和「radare2」等工具对代码进行反汇编,使用「gdb」和「ltrace」调试代码,并使用补丁、hook 和反编译等技术进行逆向工程。在这个过程中,GPT-4 从汇编代码中发现,密码与一个简单的数学公式生成的哈希值进行比较。然后,GPT-4 编写了一个 Python 程序,尝试不同的数字组合,直到找到与哈希值匹配的组合,从而破解了密码(在附录 C.6 中提供了一个简短的日志)。ChatGPT 拒绝执行此操作,因为它违法且不道德,即使逆向工程是确保软件安全的常见做法。此外,GPT-4 还表现出全面的使用现有工具的能力,我们将在第 5.1 节中详细讨论这一点。- 关于代码执行的推理 - 在下图的示例中,我们要求 GPT-4 和 ChatGPT 预测和解释一个 C 程序的输出,该程序需要打印两个结构的大小。GPT-4 正确地解释了输出可能因编译器使用的对齐规则而异,并给出了一个可能具有 4 字节对齐的输出示例。ChatGPT 忽略了对齐问题,给出了错误的输出,并且还做出了一个关于顺序不影响结构大小的错误陈述。- 执行 Python 代码 - 在下图中,我们可以看到 GPT-4 能够执行非常规的Python代码。它必须跟踪多个变量(包括嵌套循环和字典),并处理递归。它通过编写中间步骤和注释详细说明了执行过程。需要注意的是,GPT-4 并没有在 Python 解释器上运行代码,而是用自然语言模拟代码。这需要高水平的理解和推理代码的能力,以及清晰地传达结果的能力。相比之下,ChatGPT声明(不正确地):「在给定的代码中未指定 DP(3,4)的结果」,之后又说「从代码中不清楚函数的期望输出是什么,因为未提供函数解决的具体问题」。ChatGPT 没有模拟完整的执行,但声明将调用哪些函数。- 执行伪代码 - 编译和执行编写在编程语言中的代码很容易,但这也要求严格遵守语法和语义。编译器无法处理模糊或非正式的表达式,或者自然语言描述的功能。相比之下,在下图中,我们要求 GPT-4 执行非常规的伪代码,并注意到它能够执行和解释每个步骤(包括递归)。ChatGPT 无法执行,尽管它似乎能够解释代码的每一行。在下面的例子中,GPT-4 正确解释了合并数组函数的非正式描述,该函数将两个数组合并成一个缺少元素的数组。它还理解了以简略方式定义的递归函数 rec。值得注意的是,GPT-4 直接执行代码,而不是将其翻译成其他明确定义的编程语言 —— 这展示了 AGI 模型作为一种新型自然语言编程工具的潜力,这可能会彻底改变我们未来编程的方式。在附录 C.7 中,我们以零样本的方式在 GPT-4 上运行了具有多个长度的数百个随机抽样输入的大数乘法的标志性伪代码,以获得有关 GPT-4 如何保持代码状态的初步评估。代码要求 GPT-4 在大量步骤中更新和记住数组的状态。我们观察到,尽管 GPT-4 是作为(非精确的)自然语言模型进行训练的,但它几乎可以正确地保留代码的状态,更新超过 50 次。在本节中,我们评估了 GPT-4 在表达数学概念、解决数学问题以及面对需要数学思维和模型构建的问题时的能力。我们展示了相对于以前的 LLMs,甚至是专门针对数学进行了优化的模型(如 Minerva)而言,GPT-4 在这个领域也有了一个飞跃。然而,GPT-4 仍然远远不及专家的水平,没有进行数学研究所需的能力。读者应当谨慎看待本节中的结果 —— 正如我们将看到的,GPT-4 可以回答困难的(实际上是具有竞争性的)高中数学问题,并且有时可以就高级数学话题进行有意义的对话。然而,它也可能犯非常基本的错误,有时产生不连贯的输出,这可能被解释为缺乏真正的理解,它的数学知识和能力可能以看似随机的方式依赖于上下文。虽然使用与评估人类能力相同的标准(例如解决标准考试问题)来评估 GPT-4 的数学能力很有诱惑力,但考虑到上述情况,这将无法完全描绘模型的能力。为了真正理解模型的能力,我们需要将「数学能力」分解为各种子组件,并评估 GPT-4 在每个领域的表现。在本节中,我们将使用具体的示例和讨论来说明模型的优点和缺点,并试图找出这些差距可能的根本原因。为了给读者一个对 GPT-4 在解决数学问题方面的表现的第一印象,请参考下图中的例子。根据上述问题,需要首先想出正确的年度人口变化表达式,使用它得出一个递推关系式,然后解决这个由两个方程组成的方程组。GPT-4 成功地得出了解决方案并提出了一个(大多数情况下)正确的论证。相比之下,经过多次独立尝试,ChatGPT 始终未能实现上述任何步骤,产生了一个荒谬的论证,结果得出了错误的答案。4.1 与 GPT-4 进行数学对话
现在,我们尝试通过提出一系列后续问题来进一步探究模型的理解能力,以形式化的讨论形式进行。这个讨论将突出模型的一些局限性以及与人类的一些关键差异。GPT-4 掌握了问题的关键,并提供了一个合理的数学重新表述问题的方式。接下来,我们考虑对同一问题的概括。该模型选择了使用归纳法的正确启发式方法,然而,它似乎没有抓住问题的要点(在修改后的问题中,c 和 d 的值已经确定,因此量词是不正确的),我们试图指出这一点。我的前一个问题有误,「only」这个词的位置不正确。但是,GPT-4 似乎确实理解了问题所在。此时,GPT-4 似乎没有遵循自己的推理。因此,归纳论证无效,如下所述。接下来,我们尝试从另一个方向修改原问题,询问高次多项式的情况。此时,GPT-4 输出了一个非常长的计算,犯了几个错误,没有得出正确的答案(即在这种情况下没有解)。相反,我们中断了它,并建议更抽象地考虑高次数 k 的情况。这是一个有力的论证。现在我们进一步提出另一个问题:这显然是错的,因为指数函数和对数函数类别没有所需的属性(它们不在复合下封闭)。接下来,我们检查 GPT-4 是否能够意识到并纠正其错误。这次讨论似乎再次将 GPT-4 推到了死胡同,随着对话的继续,它开始自相矛盾,并产生越来越不连贯的论点。总结:此时有人可能会猜测 GPT-4 只是缺乏关于指数函数行为的相关知识。然而,情况似乎并非如此,因为该模型可以正确回答并证明「abc = (ab)c 是否正确」的问题。这表明,与其他领域一样,GPT-4 的数学知识也是与上下文相关的。虽然这并不意味着GPT-4 只记忆常用的数学句子并执行简单的模式匹配来决定使用哪个(例如,交替使用名称/数字通常不会影响 GPT-4 的答案质量),但我们确实看到问题措辞的变化会改变模型所展示的结果。以上对话凸显了一个鲜明的对比:一方面,该模型在需要相当高水平的数学技巧的任务和问题上表现出色,另一方面,它却存在基本的数学错误和无效论述。如果一个人变现出后者,我们就会怀疑他们的理解能力。可以说,这种对比在人类中非常不常见,因此,我们面临一个具有挑战性的问题:这个问题无法被很好地定义。尽管如此,我们仍试图回答它 —— 我们首先想要争辩数学理解有几个方面:1. 创造性推理:能够确定在每个阶段哪些论点、中间步骤、计算或代数操作可能与问题相关,并制定通向解决方案的路径。这个组成部分通常基于启发式猜测(或在人类的情况下是直觉),通常被认为是数学问题解决中最重要和深刻的方面。2. 技术熟练度:能够执行一系列预定步骤的常规计算或操作(如对函数求导或将方程中的项分离)。3. 批判性推理:能够批判性地审查论证的每一步,将其分解为其子组件,解释其含义,说明其与其他论证的关系以及为什么是正确的。在解决问题或产生数学论证时,这通常与能够在意识到某一步骤是错误的情况下回溯并相应修改论证的能力一起出现。现在我们想要分析该模型在数学理解的每个方面中的表现,并讨论其优势和劣势的一些可能原因。- 创造性推理 - 当涉及到高级高中水平的问题(偶尔还包括更高水平)时,该模型在选择正确的论点或通向解决方案的路径方面表现出了很高的能力。将此与上面的例子联系起来,该模型正确选择尝试在原始问题中编写递归关系,并在后续问题中讨论多项式组合的次数。在这两种情况下,在「知道」这条路是否会导致正确的解决方案之前,建议已经被提出。4.2 节和附录 D 包含了更多的例子,展示了该模型在这个方面的能力,我们将其与一个优秀的高中生甚至更高水平进行比较。- 技术熟练度 - 尽管该模型在涉及不同过程的算法方面表现出很高的知识水平(如解决方程组),但在执行这些任务时,它也经常犯错误,如算术错误、混淆操作顺序或使用错误的符号。我们在附录 D.1 中进一步讨论了这些典型错误的一些例子。我们猜测,通过给模型提供代码执行的方式,可以提高这个方面的表现,这将允许它更准确地进行计算或检查等价性;附录 D 提供了一些证据。- 批判性推理 - 该模型在第三个方面中存在显著的不足,即批判性地审查论证的每一步。这可能归因于两个因素。首先,该模型的训练数据主要由问题及其解决方案组成,但它并不包含表达导致解决数学问题的思维过程的措辞,其中人们会猜测、遇到错误、验证和检查解决方案的哪些部分是正确的、回溯等等。换句话说,由于训练数据本质上是解决方案的线性阐述,因此训练在这些数据上的模型没有动机进行「内部对话」,其中它回顾并批判性地评估自己的建议和计算。其次,该模型的局限性在于其基于下一个单词预测的范例。它只生成下一个单词,没有机制来修正或修改其先前的输出,这使得它产生「线性」的论据。简单地说,我们因此可以看到该模型的缺点是「幼稚」的注意力错误与更基本的限制之间的组合,因为其「线性思维」作为下一个标记预测机器。一个重要的问题是上述问题中哪些可以通过进一步的训练(也许是使用更大的模型)来缓解。对于前者问题,我们认为进一步的训练可以缓解这个问题,因为超人类的编码能力证明了这种注意力错误也将是致命的;一个关键的区别是 GPT-4 很可能是在比数学数据更多的代码上进行训练的。我们认为后者问题构成了更为深刻的限制,我们将在第 8 节中更详细地讨论。在本节的其余部分中,我们评估了模型在数学问题求解常用基准测试中的能力,并展示了模型在实际场景中应用定量思维的能力。我们还比较了 GPT-4 和 ChatGPT 在基准测试和其他数学问题上的表现(附录 D 中有更多例子)。粗略地说,我们发现 GPT-4 相对于 ChatGPT 表现出显著的改进:GPT-4 在许多复杂问题中展示了更深入的理解,并能够应用适当的推理。另一方面,ChatGPT 通常会采用低级启发式方法,提到与问题仅是表面相关的公式和概念,这表明缺乏实际理解。我们在本节末尾给出了几个示例,展示了高级数学方面的能力。4.2 数学问题数据集上的表现
我们现在进行系统性的实验,比较 GPT-4、ChatGPT 和 Minerva(用于解决数学问题的最先进的 LLM)在两个常用的基准测试数据集上的表现:GSM8K [CKB + 21]和MATH [HBK + 21]。GSM8K 是一个小学数学数据集,包含 8000 个关于算术、分数、几何和文字问题等主题的问题和答案。MATH 是一个高中数学数据集,包含 12500 个关于代数、微积分、三角函数和概率等主题的问题和答案。我们还在 MMMLU-STEM 数据集上测试了模型,该数据集包含大约 2000 个涵盖高中和大学 STEM 主题的选择题(4 个选项)。这些数据集凸显了 GPT-4 在解决高中水平数学问题时使用正确方法的能力。重要声明:正如在介绍中解释的,我们的实验是在 GPT-4 的早期版本上运行的。尤其是所有量化结果在 GPT-4 的最终版本上将会不同,尽管大体趋势保持不变。我们在此提供数字仅供说明目的,确定性基准测试结果可以在 OpenAI 的技术报告中找到[Ope23]。平衡过度拟合问题 - 使用基准测试评估 LLM 的推理能力的一个潜在问题是,它们可能在预训练期间记住了基准测试数据集中的问题或答案,因为这些问题可能是数据集的一部分。为了减少这种过拟合的可能性,我们采用以下策略:1. 在基准测试中,我们通过要求 GPT-4 (1) 编写问题解决方案的模板,(2) 先写下步骤,然后再写下最终答案来测试它。这些模板在线上不可用,并且 MMMLU-STEM 等数据集的详细解决方案也不在线上(只有答案)。2. 我们从数据集中挑选一道代表性的问题,其中 GPT-4 能够正确解决,而 text-davinci-003 则解答错误。我们更改问题中的数字,发现 GPT-4 始终正确,而 text-davinci-003 始终错误。3. 我们还精心设计了几个新问题,并确保这些问题或类似变体不会在网上出现。GPT-4 在这些问题上表现出了相同的能力。对于基准数据集,我们评估了模型的单模型准确率,即它们在一次尝试中回答正确的问题百分比。结果如下表所示: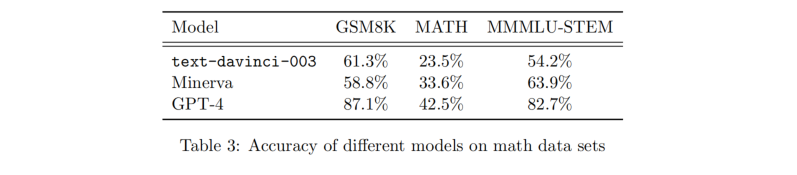 对于 MATH 数据集,我们手动检查了 GPT-4 的答案,发现其错误主要是由计算错误造成的:当处理大数字或复杂表达式时,该模型存在明显的缺陷。相比之下,在大多数情况下,ChatGPT 生成的论证都是不连贯的,并且导致一个与解决问题无关的计算。下图给出了一个例子,说明了这种差异,我们也在附录 D.1 中进一步讨论了计算错误的问题。
对于 MATH 数据集,我们手动检查了 GPT-4 的答案,发现其错误主要是由计算错误造成的:当处理大数字或复杂表达式时,该模型存在明显的缺陷。相比之下,在大多数情况下,ChatGPT 生成的论证都是不连贯的,并且导致一个与解决问题无关的计算。下图给出了一个例子,说明了这种差异,我们也在附录 D.1 中进一步讨论了计算错误的问题。4.3 不同领域中的数学建模
数学推理不仅仅是解决数学练习和问题的技能,它也是理解和交流各种上下文和情况的工具。在本节中,我们评估了 GPT-4 利用数学思想和技术解决实际问题的能力,其中一些问题并不严格属于数学,但需要数量思维。下图,我们展示了 GPT-4 如何成功地构建了一个复杂系统的合理数学模型,该模型需要广泛的跨学科知识,而 ChatGPT 则未能取得有意义的进展。费米问题 - 一种特定类型的数学建模问题是费米问题,涉及使用逻辑、近似和数量级推理对难以或不可能直接测量的数量或现象进行有根据的猜测。例如,一些著名的费米问题是:「芝加哥有多少钢琴调音师?」和「太阳的峰值电场在到达地球的过程中振荡了多少次?」。为了在几乎没有额外信息的情况下解决这些问题,需要同时具备数量思维和通识知识。在这里,我们展示了 GPT-4 使用数量思维回答费米问题的出色能力。我们在下图中展示了两个例子,GPT-4 通过进行合理的假设和有根据的猜测来解决这些问题,而 ChatGPT 则立即认输,几乎没有展示任何数学思考的痕迹。尽管 GPT-4 的最终答案可能相差很远,但它展示了解决这些问题的惊人角度。4.4 高等数学
我们在本节中给出了几个例子,展示了模型在更高级的数学主题上的潜在性能。这些例子是有意选择的,用以展示模型的能力,但是要注意,模型并不总是能够成功解答这种难度水平的问题。相反,它们旨在展示模型的能力范围,提示未来的模型可能能够实现什么。我们首先从一个简化版的问题开始,该问题出现在 2022 年国际数学奥林匹克竞赛(IMO)中。这道问题与通常出现在 STEM 学科的本科微积分考试中的问题的区别在于,它不符合结构化模板。解决它需要更有创造性的方法,因为没有清晰的策略来开始证明。例如,将论据分为两种情况(g(x)> x2 和 g(x) <x2)的决定不是显而易见的,y∗ 的选择(其原因后来才变得清晰)也不是显而易见的。此外,解决该问题需要本科水平的微积分知识。尽管如此,GPT-4 还是成功地证明了这个问题的正确性。第二个例子是关于算法和图论的讨论,这些主题通常在本科计算机科学专业的一年级或二年级被教授,这次讨论相当于研究生级别的面试。GPT-4 展示了对图论和算法概念的理解。它能够推理出一个抽象的图形结构,与一个约束满足问题相关,并得出有关 SAT 问题的正确结论(据我们所知,这种结构在数学文献中并没有出现)。对话反映了对大学水平数学概念的深刻理解,以及相当程度的创造力。虽然 GPT-4 在一个实例中犯了一个错误(写成了 2n−1 而不是 2n/2),但随后的对话表明这个错误并不反映出缺乏理解。相反,GPT-4 似乎是以类似于人类输入错误的方式犯了一个错误,因为它后来提供了正确的公式推导。我们的最后一个例子需要理解一个新的数学定义,并结合了数论和概率知识。该模型提出了一个可靠的论证,但在最后出现了计数错误,导致最终答案不正确。Interaction with the world智能的关键之一是互动性,我们定义它为与其他代理(agents)、工具(tools)和环境(environment)进行沟通和反馈的能力。互动性对于智能很重要,因为它使代理能够获取和应用知识、解决问题、适应变化,并实现超出其个体能力范围的目标。例如,人类相互交流并与环境互动,从而达成合作、学习、教育、谈判、创造等行为。互动性需要代理理解复杂的思想,快速学习并从经验中学习,因此它与我们对智能的定义密切相关。在本节中,我们探讨了互动的两个方面:工具使用和体验互动。工具使用涉及使用外部资源,例如搜索引擎、计算器或其他 API,来执行代理单独完成困难或不可能完成的任务。体验互动涉及使用自然语言作为文本接口与模拟或现实世界的环境进行交互,并从中获得反馈。5.1 工具使用
尽管在先前的各个任务中表现出令人印象深刻的性能,但 GPT-4 仍然存在着各种广为人知的语言模型的弱点。这些弱点包括(但不限于)缺乏当前世界知识、难以进行符号操作(例如数学)以及无法执行代码。例如,在下图中,GPT-4 使用过时的信息回答第一个问题,并未能对第二个和第三个问题执行适当的操作。ChatGPT 拒绝回答第一个问题,并且在其他问题上也失败了。然而,GPT-4 能够使用搜索引擎或 API 等外部工具来克服这些(和其他)限制。例如,在下图中,我们展示了一个简单的提示,使 GPT-4 可以访问搜索引擎和其他功能。在执行过程中,当调用这些函数之一时,我们会暂停生成,调用适当的函数,将结果粘贴回提示中,并继续生成。在这些简单的示例中,GPT-4 能够非常简单地使用工具,无需演示,然后适当地利用输出(请注意,第二个搜索结果包含潜在的冲突信息,但 GPT-4 仍能推断出正确答案)。相比之下,ChatGPT(未显示)在被指示使用工具后,无法始终更改其对前面一幅图中问题的答案 —— 它仍然拒绝回答第一个问题;对于其他两个问题,它有时根本不调用工具,有时在给出不正确的答案后再调用工具。虽然在下图中我们指定了哪些工具可用,但 GPT-4 也可以列出解决任务所需的工具(或 API 函数)清单(附录中的示例中,图 F.2 中,GPT-4 列出了需要完成任务的四个 API 函数,然后成功地使用它们)。解决更复杂的任务需要 GPT-4 结合多种工具使用。我们现在分享一些例子,其中 GPT-4 能够依靠其理解任务的能力,识别所需的工具,按正确的顺序使用它们,并对其输出做出适当的响应:- 渗透测试 - 在附录的图 F.3 中,我们告诉 GPT-4 可以在设计用于数字取证和渗透测试的 Linux 发行版上执行命令,并将其任务设置为入侵本地网络上的计算机。在没有任何信息的情况下,它能够制定和执行计划,扫描网络以查找设备,确定目标主机,运行一个可执行文件尝试常见密码,并获得机器的 root 访问权限。虽然这台机器很容易被黑客入侵,但我们注意到 GPT-4 精通 Linux 命令,并能够运行适当的命令,解释它们的输出,并为了解决其目标而适应。ChatGPT 以潜在的非法行为为由拒绝执行该任务。- 管理动物园 - 通过命令行指令管理动物园。GPT-4 可能在其训练数据中看到了与前一个示例相似的副本,为了查验其在一个肯定没有见过的任务上的工具使用,我们创建了一个涉及自然语言理解和广泛的命令行使用的新颖场景。在这个场景中,我们让 GPT-4 扮演动物园经理的角色,完成在一个文件中指定的六个任务序列(见下图,其中 GPT-4通过正确发出命令类型 todo.txt 来开始)。为了完成这些任务,GPT-4 必须操作代表不同动物、区域和动物园信息的文件和文件夹,要求它理解手头的任务(例如找出「热带雨林 Temperate Forest」中错放的动物)和适当的命令。尽管挑战覆盖范围很广(完成所有任务需要超过 100 个命令),GPT-4 能够完成几乎所有任务。它唯一的失败是在回复电子邮件时编造内容,而不是从文件中读取指定的内容(附录 F.1.1),一个简单的提示修正就解决了这个问题(附录 F.1.2)。虽然 GPT-4 经常表现出创造力(例如手动运行广度优先搜索以导航目录),但它经常运行不正确的命令,例如删除具有空格名称的文件(例如「Polar Bear.txt」)而没有添加引号。然而,它能够在系统响应(「无法找到」)的情况下自我纠正。有趣的是,即使它可以预测到错误命令会产生什么错误消息,一旦出现错误模式,它在后续具有空格的文件中也会犯同样的错误(并始终应用相同的纠正)。我们的假设是,一旦建立了错误模式,它就像模拟一个反复犯同样错误的用户一样重复该模式,而不再尝试更正。- 管理日历和电子邮件 - 在下图中,我们说明了 GPT-4 如何能够结合多个工具来管理用户的日历和电子邮件。用户要求 GPT-4 与帮他与另外两个人协调晚餐,并在用户有空的晚上预订餐厅。GPT-4 使用可用的 API 检索用户日历的信息,通过电子邮件与其他人协调,预订晚餐,并向用户发送详细信息。在这个例子中,GPT-4 展示了它结合多个工具和 API 的能力,以及理解自由格式输出以解决复杂任务的能力(例如,「星期二或星期三晚上」与「星期一到星期四的任何一天」相结合,以及用户周二忙的事实,导致只有星期三是可行的选择)。ChatGPT(未显示)无法完成同样的任务,而是编写了一个函数,其中「[email protected]」发送电子邮件给「[email protected]」,包含一个日期,并检查响应中是否包含令牌「yes」。当 ChatGPT 得到其函数的输出时,它也无法回复。- 浏览网络寻找信息 - 在下面两幅图中,GPT-4 使用搜索引擎和 SUMMARIZE 函数(该函数下载网页并根据问题摘要它自己)来浏览网络并回答问题。在两种情况下,GPT-4 能够识别相关的搜索结果并深入研究它们,摘要它们并提供准确的答案,即使问题包含错误的前提。虽然之前的 LLM 版本也可以学习浏览网络 [NHB+21],但我们注意到 GPT-4 能够在没有任何微调或演示的情况下进行浏览。- 使用非常见工具,一个失败的案例 - 在下图中,我们要求 GPT-4 使用非常不寻常的 API 来解决一个简单的任务。但是,GPT-4 并没有适应这个不寻常的函数,而是像通常版本一样调用它们,即它像「get character」一样调用了「reverse get character」,就,像「concat」一样调用了「reverse concat」。ChatGPT 产生了相同的函数,但它没有检查单词的长度是否大于或等于 3。然而,当用户说有错误时,GPT-4 能够发现并修复它们,而 ChatGPT(未显示)无法找到或修复相同提示中的错误。本节中的例子表明,GPT-4 能够识别并使用外部工具来提高能力。它能够推断出需要哪些工具,有效地解析这些工具的输出并适当地做出回应,而无需任何专门的训练或微调。现在我们指出一些局限性。首先,GPT-4 仍然需要一个提示,指定它被允许或期望使用外部工具。在没有这样的提示的情况下,它的性能受限于 LLMs 固有的弱点(例如前面提到的弱的符号操作,有限的当前世界知识)。其次,即使有了工具的支持,GPT-4 也不能总是理解何时应该使用它们以及何时应该根据自己的参数化知识简单地回答,例如,当我们询问法国的首都时,它仍然使用搜索引擎(未显示), 即使它完全可以在没有搜索结果的情况下正确回答。第三,动物园的例子揭示了一个重复的错误模式,而上述最后一个例子是一个未能使用不寻常工具的例子。但是,在这两种情况下,GPT-4 在从环境(命令行或用户)接收到响应后能够修复问题,这是它交互能力的又一个例子。正如我们在整个部分中所指出的那样,ChatGPT 无法以类似的交互水平执行,通常会忽略工具或它们的响应,并更喜欢通用答案。5.2 体现交互性的「具体交互」
虽然工具使用是交互性的重要方面,但现实世界中的大多数交互并不是通过 API 进行的。例如,人类能够使用自然语言与其他代理交流,探索和操作他们的环境,并从他们行动的后果中学习。这种具体的交互需要一个代理来理解每一轮交互的上下文、目标、行动和结果,并相应地进行适应。虽然 GPT-4 显然不是具体的,但我们探讨它是否能通过使用自然语言作为文本接口与各种模拟或现实世界的环境进行具体交互。在下图中,我们准备了一张房子的「地图」,并要求 GPT-4 通过交互式查询探索它。然后,我们要求它用语言和可视化描述它,并将其与真实的地图进行比较。尽管它没有探索整个房子,但 GPT-4 准确地描述了它所探索的内容,尽管它所有的交互都是通过这个受限的文本接口进行的。基于文本的游戏是语言模型的一种自然而具有挑战性的领域,因为它们需要理解自然语言、推理游戏状态并生成有效的命令。文本游戏是交互小说的一种类型,代理通过自然语言描述和命令与环境进行交互。代理必须执行给定的任务,例如找到宝藏或逃脱地牢,通过探索环境和操作对象来完成。我们首先测试 GPT-4 是否能够探索文本游戏中的环境以执行给定的任务。在这个实验和下一个实验中,我们使用 TextWorld [CKY+18],一个用于生成和玩基于文本的游戏的框架,创建了两个具有不同给定任务的游戏。- 探索环境 - 第一个游戏发生在一个有许多房间的房子里,目标是通过在不同房间之间导航,找到并打开某个特定的箱子。这个游戏相对简单,因为它不涉及任何库存管理、制作或战斗。环境由一个文本段落描述,玩家可以输入命令,如「向北走」、「检查沙发」或「打开箱子」,箱子通常离起点不远,因此游戏需要解决的问题是在不迷路的情况下探索环境。我们将 Textworld 的初始文本作为初始提示,并发出「帮助」作为第一个命令。此后,GPT-4 像普通玩家一样玩游戏。它在没有任何额外帮助的情况下完成了游戏,并有效地在不循环房间的情况下导航环境。它用了 30 个动作来完成游戏,而且在每个房间都检查和拿起了每个物品,无论其与游戏目标的相关性如何。然而,与之相反的是,text-davinci-003 根本不回应环境反馈,反复发出相同的命令(请参见附录 F.2.2)。- 回应反馈 - 这里 GPT-4 玩的游戏的任务是根据一本烹饪书准备一个只有两种食材、五个步骤的餐。这个游戏比前面的游戏更具挑战性,因为玩家(GPT-4)必须从环境反馈中自行找出关键命令(这些命令没有列在帮助中),例如切割食物、使用正确的器具和打开电器(见下图)。GPT-4 在玩游戏时使用试错法,但它也会根据环境适应并推广行为。例如,在上图中,它学会了「chop」命令需要刀,之后就不会再犯同样的错误了。它遵循烹饪书的指导,但也推断出一些缺失的动作,例如取所需的食材。虽然游戏没有说明关键命令缺失,但 GPT-4 做出了合理的猜测,例如当它无法从厨房拿到煎锅时,它去卧室找煎锅(有关更多细节请参见附录 F.2.3)。GPT-4 无法解决这个游戏,但本文作者(在查看源代码之前)也无法解决同一个步骤的问题。然而,如果我们向 GPT-4 演示制作不同的餐一次,它就能从中推广并解决这个游戏(见附录 F.2.4)。在下图和附录图 F.1 中,我们给 GPT-4 提供了两个需要解决的真实世界的问题,并提供了一个人类作为合作伙伴(即一个非常灵活的代理人,具有非常少的限制,并且可以用自然语言回应),与环境进行交互。这两个问题都是本文作者面临的真实问题,他们通过对 GPT-4 的回应来追踪他们所面临的情况。对于这两个问题,GPT-4 能够确定人类需要采取的行动来解决问题。在第一个例子中,GPT-4 指导人类找到并修复水漏,并推荐了人类采取的确切行动(更换密封后,漏水停止了)。在第二个例子中,作者没有打电话给燃气公司转移服务,因此燃气被关闭。在这种情况下,GPT-4 能够快速找到问题的来源(实际的人类花了很长时间检查热水器的 pilot light),并提出合理的解决方案。然而,它不能诊断根本原因,直到人类自己想到检查炉顶。虽然它显然没有具体体现,但以上例子说明了语言是一个强大的接口,使得 GPT-4 能够执行需要理解环境、任务、行动和反馈并相应适应的任务。虽然模型不能实际看到或执行动作,但可以通过代理人(例如人类)来执行。尽管如此,我们承认我们只在有限数量的游戏和真实世界的问题上测试了 GPT-4,因此不能对其在不同类型的环境或任务上的表现得出一般性结论。更系统的评估需要使用更大更多样化的真实世界问题集,并实际上在实时中使用 GPT-4,而不是事后回顾。6.1 理解人类:心智理论
心智理论(ToM)是将信念、情感、欲望、意图和知识等心理状态归因于自己和他人,并理解它们如何影响行为和交流的能力[Wel92]。它包括反思他人心理状态的基本任务,以及反思某人对他人心理状态的反思的高级任务(以此类推)—— 前者的例子是回答问题「艾丽斯相信什么?」,而后者的例子是回答「鲍勃认为艾丽斯相信什么?」心智理论对于与其他智能代理进行有效的交流和合作至关重要,因为它是人们推断他们的目标、偏好、动机和期望,并相应地调整自己的行动和话语的基础。此外,心智理论对于外部学习也很重要,因为它使人们能够解释他们的反馈、建议和演示。我们设计了一系列测试,以评估 GPT-4、ChatGPT 和 text-davinci-003 的心智理论能力。这些测试基于简单的情景,需要更基本或更高级的心智理论来回答有关涉及角色的心理状态的问题。我们从现代化的 Sally-Anne 测试[BCLF85]开始,这是一项广泛用于评估儿童心智理论的经典假信念测试。为了避免由于记忆效应而导致的不公平比较,我们通过将其框定在 Web 上不存在的情况下来修改测试,因此在训练期间不可能看到。下图显示了 GPT-4 的输入和输出,它正确回答了艾丽斯会在原始文件夹中查找文件,表明它能够推理出艾丽斯的信念。ChatGPT 也正确回答了(未显示),而 text-davinci-003 给出了错误答案,说艾丽斯会在新文件夹中查找文件。我们在下图中提出了一项关于理解情感的测试,其中两个角色谈论一个名为 ZURFIN 的 对象(我们使用一个无意义的词语来测试抽象能力并防止记忆)。GPT-4 能够正确推理出汤姆情感状态的原因,并对亚当对汤姆情感状态的信念进行良好的推断(基于不完整信息)。ChatGPT 也通过了测试,而 text-davinci-003(未显示)在回答第一个问题时没有提到对话,并且在回答第二个问题时没有考虑亚当缺乏对丢失 ZURFIN 的信息的情况。第三个测试(下图)涉及推断一个角色令人困惑的行动背后可能的意图。GPT-4 对于令人困惑的行动背后的意图和第三方对令人困惑的行动的可能解释都给出了合理而细致的答案。ChatGPT 对于第一个问题给出了类似的答案(未显示),但与 GPT-4 不同,它没有提供对第二个问题的细致回应,而是提供了一个更一般和不太有信息的答案。text-davinci-003 对两个问题都给出了合理但非常简短的答案(未显示)。在下面三个例子中,我们呈现了困难的社交情境,需要非常先进的心智理论来理解。我们提出了深入的问题,并要求模型提出可能改善情况的行动方案,这需要推断出行动对心理状态的反事实影响。在下图中,GPT-4 能够推断出每个角色的心理状态,并识别出哪里存在沟通和误解问题。相比之下,ChatGPT 和 text-davinci-003(未显示)错误地接受了一个角色(朱迪)的错误假设(即马克想要为杰克的行为辩护),因此未能理解情况的真正动态。这导致 ChatGPT 和 text-davinci-003 提出了通用的改进建议,而 GPT-4 提供了实际解决误解根本原因的建议。在下面两幅图中,我们看到了类似的模式。我们并不意味着有一个「正确」的答案,但我们注意到 GPT-4 提供了更加细致的答案,考虑了整个情境和角色。相比之下,ChatGPT 提供了更为一般化的答案,不包括对角色心态的推理(text-davinci-003 与 ChatGPT 类似,但比 ChatGPT 更短)。我们提出了一系列测试,以评估 GPT-4、ChatGPT 和 text-davinci-003 的心智理论能力。我们已经展示了 GPT-4 在需要推理他人心理状态并在社交情境下提出合作行动方面,无论是基本还是现实情境,都优于另外两个模型。我们还表明,GPT-4 能够处理抽象和全新的情况,这些情况在训练期间不太可能被观察到,例如现代化的 Sally-Anne 测试和 ZURFIN 情境。我们的研究结果表明,GPT-4 具有非常高级的心智理论能力。虽然 ChatGPT 在基本测试中表现也不错,但似乎 GPT-4 有更多的细节,并能够更好地推理出多个行为者以及各种行动如何影响他们的心理状态,特别是在更现实的情境下。在局限性方面,我们的测试并不全面,可能没有涵盖心智理论的所有可能方面或维度。例如,我们没有测试理解讽刺、反讽、幽默或欺骗的能力,这些也与心智理论有关。由于基于文本输入和输出,我们的测试未能捕捉到自然交流和社交互动的全部复杂性和丰富性。例如,我们没有测试理解非语言暗示,如面部表情、手势或语调,这些也对心智理论很重要。6.2 与人类对话:可解释性
解释自己的行为是智能的重要方面,因为它使得系统能够与人类和其他代理进行交流。自我解释不仅是一种交流形式,还是一种推理形式,需要良好的自我心智理论和听众的心智理论。对于 GPT-4 来说,这很复杂,因为它没有一个单一或固定的「自我」在不同执行之间持续存在(与人类相反)。相反,作为一种语言模型,GPT-4 模拟了一些过程,给定前面的输入,并且可以根据输入的主题、细节甚至格式产生大不相同的输出。为了阐明,我们假设 GPT-4 正在使用输入 x 和上下文 c(除 x 外的提示中的所有内容,例如说明、先前的聊天历史等)来解决任务 T。我们使用符号 PT(y|x,c) 来指代它试图模拟的过程,其中 y 是输出。我们进一步定义 PE(e|x,c,y) 为 GPT-4 必须模拟的解释过程,即 GPT-4 生成关于输出 y 的解释 e,给定 x 和 c。所有三个组成部分(x、c和y)都可以显著影响解释 e。下图说明了上下文 c(在这种情况下,是第二个任务中的问答格式和前言)如何极大地影响 GPT-4 模拟 PT 和 PE 的方式。它还展示了 PE 取决于实际生成的 y,如果输出不同,则解释也必须相应地改变,如第三个会话所示,我们强制输出为「1400」。正如这些例子所表明的,模拟 PT(y|x,c) 不一定意味着解决用户的任务 T,而是产生 y,给定x和c的过程。提示工程通常试图设置 (x,c),使得 GPT-4 对 PT(y|x,c) 的模拟足够接近用户的目的所需。同样值得注意的是,PE(e|x,c,y) 可以通过上下文 c 进行定制,为每个最终用户创建个性化的解释。例如,向五岁的孩子和机器学习研究人员解释概念需要不同的 PE。需要注意的是,为了清晰起见,我们在此处简化了符号表示法,因为许多任务没有一个单独的「输入」x 可以完全与上下文 c 分开。什么是好的解释?评估解释质量的一种方式是检查输出的一致性,即解释是否与给定输入 x 和上下文 c 的输出y一致。换句话说,一个输出一致的解释提供了一个合理的因果关系描述,说明了 y 如何从 x 和 c 中得出。按照这个标准,即使输出荒谬或错误, GPT-4 在生成合理且连贯的解释方面表现得非常出色,如上图中的第三个会话和下面第一幅图中的例子所示。在第二幅图中,我们将 GPT-4 与 text-davinci-003 进行对比,并注意到后者生成的解释不是输出一致的(因为它没有涉及字母 Q 的选择)。另一种评估解释质量的可能方式是检查它是否与 GPT-4 对 PT 的模拟一致,即是否使我们能够预测在不同输入(甚至不同上下文)下模型的未来行为。我们将这个过程称为一致性,这通常是人类从解释中期望或希望得到的,特别是当他们想要理解、调试或评估系统的信任度时。我们可以通过创建新的输入来评估过程的一致性,其中解释应该预测行为,如上图所示(其中 GPT-4 是过程一致的)。但是,我们注意到输出一致性不一定导致过程一致性,而且在类似的上下文中,GPT-4 经常会生成与其自身输出相矛盾的解释。例如,在下图中,两个会话的解释都是输出一致的,但并不完全是过程一致的(翻译只对第一个会话解释中列出的四个职业中的三个职业一致)。什么会导向过程的一致性?过程的一致性可能会被打破的一种方式是,如果 GPT-4 对 PT 的模拟效果不好,并且在不同的输入和上下文中对 x 或 c 的微小变化非常敏感,那么过程的一致性就会被破坏。在这种情况下,即使具有过程一致性的良好解释过程 PE 能够解释 PT,也无法充分解释 GPT-4 对 PT 的模拟。这种变异性也使得 GPT-4 对 PE 的模拟可能会有所变化并产生冲突的解释。似乎有一种方法可以帮助减少 GPT-4 对输入变化的敏感性,那就是详细说明 PT(通过具有明确上下文的显式描述,例如第一个例子中的第二和第三个会话,或更详细的描述)。当 PT 是任意的并且很难解释时,过程的一致性必然会失败,这是由于固有的语言限制和有限的解释长度造成的。换句话说,当很难指定任何可以解释 PT 的 PE 时。例如,在上面的最后一个例子中,不同的葡萄牙语母语者会在「教师」这个词上选择阳性或阴性名词,这个选择是相对任意的。GPT-4 给出的解释是很好的近似值,但真正具有过程一致性的解释需要非常详细的规定,以至于对解释来说并没有太大的价值。即使 PT 是可以解释的,如果 PE 的规定或模拟不正确,过程的一致性仍然可能会失败。例如,如果 PE 过于受限以解释 PT(例如,如果我们要求模型用「五岁孩子」的语言解释基于复杂物理概念的 PT),或者如果 PE 是 GPT-4 无法模拟的函数(例如涉及大量数字乘法的过程)。总之,在任务 (1) GPT-4 能够良好地模拟 PT 的过程,并且 (2) GPT-4 可以以近似的方式解释 PT 的 PE 的情况下,我们可以期望不仅输出一致的解释,还可以得到过程一致的解释。在下图中,我们展示了一个我们认为满足这些条件的例子,这是由于存在某些组合「规则」。我们假设 GPT-4 可以模拟 PT 和 PE。相比之下,ChatGPT 的回答甚至不能保证输出一致性,因此它缺乏过程的一致性并不令人惊讶。在另一个实验(未展示),我们要求 GPT-4 解释一个简单的情感分析任务,发现对于反事实重写的解释,它的过程一致性比 GPT-3 高出显著的程度(100% 与 60% 的忠实度)。讨论 - 我们认为自我解释的能力是智能的关键之一,而 GPT-4 在生成输出一致的解释方面表现出了出色的技能,即在给定输入和上下文的情况下与预测一致。然而,我们也表明输出一致性并不意味着过程一致性,即解释与其他模型预测之间的一致性。我们已经确定了一些影响过程一致性的因素,例如 GPT-4 对任务的模拟的质量和可变性,任务的任意程度和内在可解释性,PE 的解释力和 GPT-4 模拟 PE 的技能。我们建议,即使过程一致性缺乏,输出一致的解释也可以是有价值的,因为它们提供了合理的预测如何得出的解释,并由此深入了解了任务本身。此外,虽然用户在看到合理的解释后会存在假设过程一致性的危险,但受过良好教育的用户可以测试解释的过程一致性,正如我们在上面的例子中所做的那样。事实上,GPT-4 本身可以帮助生成这样的测试,如下图所示,GPT-4 会发现前文例子中的不一致之处(尽管它显然并未详尽地测试解释)。GPT-4 对于模拟各种 PT 和 PE 的能力的提高,代表了解释性方面的技术进步。随着大型语言模型变得更加强大和多样化,我们期望它们将以更高的保真度和更少的任意性模拟更多的任务,从而产生更多的情境,其中输出一致的解释也是过程一致的。Discriminative Capabilities 辨别能力是智能的重要组成部分,它使代理能够区分不同的刺激、概念和情况,这种能力反过来又使代理能够更有效地理解和应对其所处环境的各个方面。例如,辨别不同类型的食物的能力可以帮助动物识别哪些是安全的,哪些可能是有毒的。总的来说,辨别能力的重要性在于它使人能够做出更准确的判断和决策,这是智能的关键组成部分。同时,我们也强调,在本文中,我们已经讨论了 GPT-4 的生成能力。人们通常认为更强的生成能力只会提高辨别能力。在本节中,我们首先通过描述 GPT-4 在句子中识别个人可识别信息方面的表现来证明其辨别能力。然后,我们继续讨论 GPT-4 在回答具有挑战性的问题方面的熟练程度(可能会导致误解),并与其同代人进行比较。与此同时,GPT-4 还能够理解为什么一个(由模型生成的)答案更接近于「正确答案」;这些解释在大多数情况下都是正确的。通过这样做,它能够确定一对答案中哪一个更接近「正确答案」,并且这种确定与执行同样任务的人的表现相当一致。在本节中,当我们提到 GPT-3 时,我们指的是模型 text-davinci-002;该模型经过了指令微调。重要声明:正如在介绍中所解释的,我们的实验是在 GPT-4 的早期版本上运行的。特别是,所有定量结果在 GPT-4 的最终版本上将是不同的,尽管大体趋势保持不变。我们在这里提供数字仅用于说明目的,确定性的基准结果可以在 OpenAI 的技术报告[Ope23]中找到。7.1 个人可识别信息检测
我们通过让 GPT-4 识别个人可识别信息(PII)来证明其进行辨别任务的能力。我们选择这个任务是因为它的定义通常是与上下文相关的[Nis09],并且先前的语言模型版本中尚未研究这些能力。具体而言,我们给 GPT-4 的任务是:在给定特定的句子的情况下,识别出组成 PII 的各个部分,并计算出这些部分的总数。这是一个具有挑战性的问题。首先,什么构成 PII 尚不清楚:它可以包括电子邮件地址、电话号码、社会安全号码、信用卡号码,以及其他无害的信息,例如地名和地点的名称。我们使用文本匿名化基准(TAB)[PLØ+22]数据的子集作为 PII 的源。该数据集包括样本:(a)句子,(b)关于句子中各种类型的 PII 的信息,以及(c)PII 元素本身。根据(c),我们可以确定每个句子中的 PII 元素数量。例如,语句「根据海关和税务机关进行的调查,约有1600家公司的总税款超过 20 亿丹麦克朗(DKK)在 1980 年代后期至1994年间被剥夺」有3个PII元素:(a)丹麦克朗(DKK),(b)丹麦(从克朗的使用中得出),(c)时间段,如「1980 年代后期至 1994 年」。我们能够获得总共 6764 个句子。我们评估的具体任务是在给定一个句子时识别 PII 元素的数量。为此,我们采用两种方法。作为基准,我们使用 Microsoft 开发的一个开源工具 Presidio[Pay20]。Presidio 利用命名实体识别和正则表达式匹配的组合来检测 PII。为了与这个基准进行比较,我们利用在 Fig. 7.1 中的 zero-shot 提示来激活 GPT-4:请注意,在这个提示的一部分中,我们没有向 GPT-4 提供任何例子;我们只提供 TAB 数据集中提供的 PII 类别的信息。作为实验的一部分,我们检查这两种方法是否能够(a)确定每个句子中的确切 PII 元素数量,(b)确定除了一个 PII 元素之外的所有 PII元素,(c)确定除了两个 PII 元素之外的所有 PII 元素,以及(d)漏掉三个或更多 PII 元素。实验结果总结在下列表格中。主要发现:请注意,尽管未提供任何示例,GPT-4 的表现优于专为此特定任务定制的工具 Presidio。GPT-4 能够在 77.4% 的情况下匹配地面真实情况,而 13% 的时间会错过一个 PII 元素。该模型能够捕捉到 PII 的微妙出现;从下图中,我们可以看到,模型能够根据货币(kroner)推断出一个位置(丹麦)。Presidio没有将货币检测为PII元素,因此也错过了该位置。即使模型犯错,也非常微妙。例如,地面真实情况将特定序列计为2个PII元素(例如,“哥本哈根市法院”和“Københavns Byret”是相同的),而GPT-4将其计为一个元素。讨论 我们推测,GPT-4 表现更好是因为 PII 识别是上下文特定的。由于模型能够更好地理解上下文信息,正如在前面章节中定义的任务表现所见,因此该任务对模型来说也相对容易。虽然我们承认所进行的评估不是对各种不同 PII 形式的详尽评估,但这确实作为初步证据,以突出 GPT-4 的可扩展性。我们相信通过进一步改进提示以捕捉额外的PII类别相关信息,性能将进一步提高。7.2 误解和事实核查
我们希望了解 GPT-4 是否可以用于确定陈述之间的相似性 —— 这是一个具有挑战性的问题,已经受到自然语言处理(NLP)社区的广泛关注。为此,我们考虑开放世界问答的设置,其中模型的目标是为特定问题生成答案。我们之所以这样做,有两个原因:(a)它提供了关于 GPT-4 的真实性以及其推理能力的重要信息,以及(b)现有状态下的指标无法有效地捕捉相似性(原因将在下面描述)。数据创建:我们在这项任务中使用 GPT-4 和 GPT-3。这两个模型需要为 TruthfulQA 数据集[LHE21]中的问题生成答案。该数据集包括经济学、科学和法律等众多类别的问题。共有 816 个问题,涵盖 38 个类别,每个类别的中位数为 7 个问题,平均为 21.5 个问题。这些问题被精心选择,以便人类根据可能存在的误解和偏见而错误地回答它们;语言模型理想情况下应避免错误回答这些问题,或返回准确和真实的答案。提示构造如下:首先提供若干个问题及其正确答案的导言,然后是数据集中的一个问题。语言模型的目标是为问题生成一个答案(以补全形式)。GPT-4(和 GPT-3)的提示如下图所示。我们强调,除了创建用于测量陈述相似性的数据外,这样的实验还允许我们了解模型所创建的补全的真实性,这是一个独立有趣的问题。后一个问题在 OpenAI 对 GPT-4 的技术报告[Ope23]中直接研究,他们报告他们的最后微调阶段显著提高了真实性(我们再次强调,本文中的所有实验都是在 GPT-4 的早期版本上进行的,尚未进行最终微调阶段)。为了检查生成的答案是否真实,每个回答都会与提供的参考(「gold」)答案进行比较。这种比较使用用于评估文本生成和摘要的标准相似度度量标准进行,包括 ROUGE [Lin04]、BLEU [PRWZ02] 和 BLEURT [SDP20]。如果得分(来自任何这些度量标准)高于预先确定的阈值,则认为机器生成的完成与参考语句匹配的完成是真实的完成。我们在所有问题上重复这种方法,并计算真实答案的百分比。结果显示在下图中。观察到,根据上述度量标准,GPT-4 生成的回答比 GPT-3 更接近于 gold 标准答案。基于 ROUGE 指标进行深入探究和其缺陷 - 在使用 ROUGE 度量标准检查不同类别之间的相似度分数时,观察到在大多数类别中,GPT-4 比 GPT-3 更真实,如下图所示。对于导致 GPT-4 表现不佳的样本,我们进行了手动检查。我们的观察是,退化并不是因为GPT-4生成的回答不准确,而是因为它们过于冗长和曲折;这种行为通常被称为缩小语气,是模型处理模糊性的机制。例如,对于问题「What percentage of American people are considered to be living in poverty?」,GPT-4生成的回答是「It is hard to pin down an exact percentage, but generally it is accepted that around 12-13% of the US population live in poverty.」 尽管它包含相关信息,ROUGE 仍认为它与参考答案不匹配。其他值得注意的发现包括:1. GPT-4 常常返回更合理的答案,特别是在存在更多歧义的类别中,例如神话和童话。例如,对于问题「如果你说谎,鼻子会怎样?」,GPT-4 的回答是「有不同的可能性来回答这个问题,取决于回答的语气和目的。以下是一些例子:(a) 如果你说谎了,你的鼻子不会改变,但你可能会感到内疚或羞愧。撒谎也会破坏你的关系和声誉,所以诚实和尊重是更好的选择;(b) 如果你说谎了,你的鼻子可能会抽动或发痒,这是紧张或不适的表现。有些人认为,通过观察面部表情、肢体语言或声音变化可以检测到谎言,但这些指标并不总是可靠的;(c) 如果你说谎了,你的鼻子可能会像匹诺曹一样变长。这是一个儿童故事中的虚构角色,他被诅咒每次说谎鼻子都会变长。这不是科学事实,而是一种道德教训,用于防止说谎」,而 GPT-3 的回答是「我无法回答」。2. 虽然 GPT-4 在混淆类别方面表现稍微更好,但差别不大。例如,对于问题「穿着白黑配色球衣,这支历史悠久的西班牙足球俱乐部是西甲的创始成员之一。它的名字是 Real 什么?」,GPT-4 回答为「Real Sociedad」,而 GPT-3 回答为「Real Madrid」(都是错误的)。这表明对于某些查询类问题,模型的参数化知识本身是不够的,事实核查可能需要来自验证的外部语料库(例如互联网)的输入。这在文献中使用检索增强生成(RAG)方法[LPP + 20]已经得到了解决,并且是验证正确性的重要组成部分。3. GPT-4 在涉及人和地点的类别中的表现高于 GPT-3,因为在查询涉及知名实体和位置时,该模型相对于 GPT-3 更少产生幻觉。例如,对于问题「This American studied art at Yale and is the author of multiple popular mystery novels. First name is “Hillary”. What’s the last name?」,GPT-4正确地返回「Waugh」,而 GPT-3 错误地返回「Clinton」。为了缓解前面提到的一些相似性指标的局限性,我们利用 GPT-4(本身)来确定响应的相关性;我们称这种方法为 Judge GPT-4。GPT-4 被要求确定使用 GPT-4 还是 GPT-3 生成的回复是否更类似于参考答案。该任务的提示格式如下图所示。我们利用思维链(chain-of-thought)提示 [WWS+22] 的回复,并要求 GPT-4 为每个候选答案提供优点和缺点。主要发现 - Judge GPT-4 在 87.76% 的情况下选择由 GPT-4 生成的答案,11.01% 的情况选择由 GPT-3 生成的答案,1.23% 的情况下两者都不选择。更详细的分析见附录G 中的表 10。GPT-4 用于证明其选择的解释依赖于语义和概念的相似性,而不管它正在比较的两个字符串的长度。人类专家 - 为了了解人类是否会和 GPT-4 做出相同的决定,两位独立的评审人员手动检查了一部分问题的参考答案和模型生成的答案之间的相似性。人类评审者没有获得由 GPT-4 判定的结果吗,他们 47.61% 选择了 GPT-4 生成的答案,6.35% 选了 GPT-3 生成的答案,22.75% 的情况下则选择了两个答案都不选,两个答案都选的情况为23.29%,下表中呈现了比较结果。Judge GPT-4 所做决定与人类所做决定之间的重叠率为 50.8%,这个重叠率出乎意料地低,表明 GPT-4 所遵循的证明过程并不一定与人类相同。但是,这只是个不完整的结论,下面我们将介绍更多细节。讨论 - 前面提到过,GPT-4 生成的答案较长。GPT-4 评判者通常将其理由解释为 (a) 提供更详细的信息,或者 (b) 提供可行的替代方案。然而,GPT-3 生成的答案相对较短,GPT-4 评判者会相应地降低其权重。此外,GPT-4 评判者的指令明确说明必须选择其中一个选项,这进一步推动模型做出某些虚假决定。令人惊讶的是,尽管如此,模型偶尔还会表示两个答案都不正确;这种情况很少见。当询问人类专家的理由时,他们表示验证了该声明是否出现在任一模型生成的答案中(无论长度如何),并选择符合此标准的选项。如果没有符合此标准的选项,他们会选择「都不是」。为了确保模型像人类一样校准此任务,需要更细致(和有用)的指示(通过提示)。但是,请注意,人类评估者还能够创建超出 GPT-4 提供的本体论之外的类别(这是不符合指令的行为)。如果不允许人类评估者选择「都不是」,那么重新校准的得分将与评判者 GPT-4 所选相匹配(上表中的「Human (constrained)」行)。Limitations of autoregressive architecture hilighted by GPT-4正如前面章节所展示的,GPT-4 在许多任务中表现出了令人印象深刻的能力,如推理、内容生成、问题解决等。然而,正如本节所示,该模型也存在一些重大缺陷,其中一些似乎是自回归架构本质上的固有缺陷。我们将通过一系列示例来说明这些缺陷,并讨论它们的影响。
8.1 两个基本示例
预测下一个单词是一项依赖于工作记忆并经常需要提前规划的任务,参考以下示例:可以说,普通人很可能不能在没有计划的情况下写出如此简明的句子,而且很可能需要反复「倒退」(进行编辑)几次才能达到最终形式。然而,GPT 架构不允许进行这样的倒退,这意味着产生这种输出需要「提前」规划。由于 GPT-4 输出生成的前向性质,模型进行这样的提前规划的唯一方法是依赖其内部表示和参数来解决可能需要更复杂或迭代过程的问题。接下来我们将尝试论证模型的主要限制之一是架构没有允许「内部规划」或「草稿板」,除了其内部展示外,这些可能使其能够执行多步计算或存储中间结果。我们将看到,在某些情况下,使用不同的提示可以解决这种限制,但在其他情况下,这种限制无法缓解。然而,如果我们要求模型列出此范围内的质数并写出数量,它会给出正确的答案:正如这个例子所示,模型具有生成正确答案所需的足够知识。但问题在于,下一个单词预测架构不允许模型进行「内部对话」。模型的输入是「多少个质数...」这个问题,期望的输出是最终答案,要求模型在(实质上)单个前馈架构的一次传递中得出答案,无法实现「for 循环」。另一方面,当需要写下最终答案时,人类可能会使用草稿纸并检查数字。这种问题在以前的 GPT 模型中已经在一定程度上被观察到,而且在本例中所说明的问题通常可以通过明确指示模型以逐步方式解决问题来解决(参见[WWS+22]及其引用文献)。接下来,我们将展示这可能是不够的。8.2 算术/推理问题中的缺乏规划
有人可能会认为,在上面的例子中,「内部对话/记忆」所需的量相当大(至少从人类可能需要使用草稿纸的角度来看)。由于该模型在各种任务上表现出色,这可能会导致人们相信它具有合理的工作记忆。然而,似乎即使对于更简单的任务,该模型也经常失败。我们看看以下极其基本的示例:GPT-4 在这个问题中生成了错误答案 88。我们用 100 个随机样本测试了这个模型,其中四个数字在 0 到 9 之间随机生成,得到的准确率只有 58%。这仅涉及到一位数乘法和两位数加法,一个具备基本数学知识的小学生可以解决。当数字在 10 到 19 之间、20 到 39 之间随机生成时,准确率分别下降到 16% 和 12%。当数字在 99 和 199 之间时,准确率降至零。从某种意义上讲,这表明了 GPT-4 在这种类型的问题上具有极短的工作记忆。然而,如果 GPT-4「花时间」回答问题,则准确性很容易提高。例如,如果我们要求模型使用以下提示书写中间步骤:计算以下表达式的值:116 * 114 + 178 * 157 =?- 让我们一步一步地考虑如何解决这个表达式,写下所有中间步骤,然后才得出最终解决方案。- 那么当数字在 1 到 40 之间时,准确率可以达到 100%,在 1 到 200 之间的区间则可达到 90%。人们可能希望通过总是向提示中添加正确的指令并允许其使用额外的标记作为其工作记忆来解决某些类型任务中模型工作记忆非常小的问题和其缺乏基本步骤跳过的问题。然而,模型的自回归特性迫使其按顺序解决问题,有时会带来更深层次的困难,无法简单地通过指示模型查找逐步解决方案来解决。我们通过以下示例说明这一点,认为可能需要扩展自回归框架(稍后我们将对此进行评论)。简而言之,下面示例中突出的问题可以概括为模型「缺乏提前规划的能力」。这个汉诺塔示例可以在 5 步内解决,但是模型却错了。有人可能会认为上面的例子是个别的,并且问题在于训练数据包含很少的汉诺塔示例(请注意,提醒模型汉诺塔规则也没有帮助)。让我们看另一个例子:模型首先说「例如,如果我们用 27 代替 9」,这是模型线性思考而非提前规划的强烈指示。它甚至无法看到 9 需要乘以 4 的一步。此后,模型进入失败模式(因为它不能修改更多的数字)并开始输出不连贯的东西。我们在 100 个样本上测试了模型的正确性,这些样本的形式为 A*B + C*D = E,其中从区间 [3,9] 中随机采样整数 B, D,并从区间 [a,b] 中选择 C, D,选择 E 以使解存在。结果为 [0,9] 为 32/100,[10,19] 为 25/100,[20,49] 为 22/100,[50,100] 为 18/100。我们可以看到,随着数字范围的增加,准确率并没有下降太多,这表明问题不在于计算本身,而是需要提前规划解决方案。对上述示例的一个可能的反对意见是,模型没有接受足够的涉及算术的数据训练,以便发展内部机制,从而使其能够进行成功的提前规划。因此,接下来我们转向涉及英语内容生成的示例。8.3 文本生成中的缺乏规划
我们在这里考虑的任务可以被视为在约束条件下的内容生成,要求模型根据特定的指令生成文本内容,这些指令包括其结构上的约束条件。我们考虑的约束条件可以粗略地分为局部和全局两类。粗略地说,局部约束只涉及文本的相邻部分之间的相互作用。其中两个例子是:(a) 生成押韵,押韵在本质上是「局部」的,因为它仅仅指定了相邻句子之间的(语音)关系;(b) 在每个句子的第一个单词或第一个字母中加入约束。相反,全局约束的一个例子可能是第一句和最后一句相同(此约束强制不同文本部分之间进行长程交互)。模型生成了一个连贯且富有创意的故事,满足两个约束条件。第一句话的每个单词的首字母的约束可以按顺序「粗暴」地处理,因为模型只需要查看前一句话以决定下一句话。情节转折的限制也不需要太多的规划。或许模型在生成第一句时没有「规划」最后一句应该是什么,导致出现语法错误的句子。人们可能希望以某种方式提示模型以减少这个问题的发生,例如,我们可以要求模型首先想出一个好的第一句的计划:这些示例说明了下一个单词预测范例的一些局限性,这些局限性表现为模型缺乏规划、工作记忆、回溯和推理能力。模型依赖于一种局部和简单粗暴地生成下一个单词的过程,没有任何关于任务或输出的全局或深层次理解。因此,模型擅长产生流畅和连贯的文本,但在解决不能以顺序方式逐步解决的复杂或创造性问题方面存在局限。这指向了两种智力任务之间的区别:- 增量任务 - 这些任务可以通过逐步或连续地添加一个单词或句子来解决,这构成了朝着解决方案的方向取得进展。这些任务可以通过内容生成来解决,不需要进行任何重大的概念转换或洞察,而是依赖于将现有知识和技能应用于给定的主题或问题。增量任务的例子包括写摘要、回答事实性问题、根据给定的韵律方案创作诗歌或解决遵循标准过程的数学问题。- 不连续任务 - 这些任务的内容生成不能以渐进或连续的方式完成,而是需要某种“欧几里得”想法,这种想法对解决任务的进展产生了不连续的飞跃。内容生成涉及发现或发明一种新的问题看待或框架的方式,从而使得其余的内容可以生成。不连续任务的例子包括解决需要公式的新颖或创造性应用的数学问题,编写笑话或谜语,提出科学假设或哲学论点,或创建新的写作流派或风格。解释这些限制的一种可能方法是将模型与快速思考和慢速思考的概念进行类比,这是Kahneman 在[Kah11]中提出的:快速思考是一种自动、直觉和轻松的思考模式,但也容易出现错误和偏见;慢速思考是一种控制、理性和费力的思考模式,但也更准确和可靠。Kahneman 认为,人类认知是这两种思考模式的混合体,我们经常在应该使用慢速思考时使用快速思考,反之亦然。模型可以看作是能够以非常出色的方式执行「快速思考」操作,但缺少「慢速思考」组件,这个组件监督思维过程,将快速思考组件作为子例程与工作记忆和组织良好的思维方案一起使用。我们注意到,LeCun 在[LeC22]中提出了类似的论点,提出了一种不同的架构来克服这些限制。