短视频推荐系统的核心目标是通过提升用户留存,牵引 DAU 增长。因此留存是各APP的核心业务优化指标之一。然而留存是用户和系统多次交互后的长期反馈,很难分解到单个 item 或者单个 list,因此传统的 point-wise 和 list-wise 模型难以直接优化留存。强化学习(RL)方法通过和环境交互的方式优化长期奖励,适合直接优化用户留存。该工作将留存优化问题建模成一个无穷视野请求粒度的马尔科夫决策过程(MDP),用户每次请求推荐系统决策一个动作(action),用于聚合多个不同的短期反馈预估(观看时长、点赞、关注、评论、转发等)的排序模型打分。该工作目标是学习策略(policy),最小化用户多个会话的累计时间间隔,提升 App 打开频次进而提升用户留存。然而由于留存信号的特性,现有 RL 算法直接应用存在以下挑战:1)不确定性:留存信号不只由推荐算法决定,还受到许多外部因素干扰;2)偏差:留存信号在不同时间段、不同活跃度用户群体存在偏差;3)不稳定性:与游戏环境立即返回奖励不同,留存信号通常在数小时至几天返回,这会导致 RL 算法在线训练的不稳定问题。该工作提出 Reinforcement Learning for User Retention algorithm(RLUR)算法解决以上挑战并直接优化留存。通过离线和在线验证,RLUR 算法相比 State of Art 基线能够显著地提升次留指标。RLUR 算法已经在快手 App 全量,并且能够持续地拿到显著的次留和 DAU 收益,是业内首次通过 RL 技术在真实生产环境提升用户留存。该工作已被 WWW 2023 Industry Track 接收。
作者:蔡庆芃,刘殊畅,王学良,左天佑,谢文涛,杨斌,郑东,江鹏论文地址:https://arxiv.org/pdf/2302.01724.pdf如图 1(a)所示,该工作把留存优化问题建模成一个无穷视野请求粒度马尔科夫决策过程(infinite horizon request-based Markov Decision Process),其中推荐系统是 agent,用户是环境。用户每次打开 App,开启一个新的 session i。如图 1(b),用户每次请求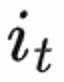 推荐系统根据用户状态
推荐系统根据用户状态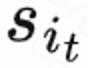 决策一个参数向量
决策一个参数向量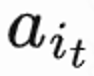 ,同时 n 个预估不同短期指标(观看时长、点赞、关注等)的排序模型对每个候选视频 j 进行打分
,同时 n 个预估不同短期指标(观看时长、点赞、关注等)的排序模型对每个候选视频 j 进行打分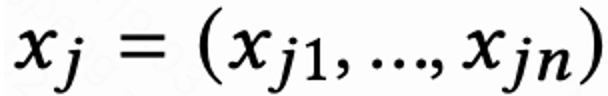 。然后排序函数输入 action 以及每个视频的打分向量,得到每个视频的最终打分,并选出得分最高的 6 个视频展示给用户,用户返回 immediate feedback
。然后排序函数输入 action 以及每个视频的打分向量,得到每个视频的最终打分,并选出得分最高的 6 个视频展示给用户,用户返回 immediate feedback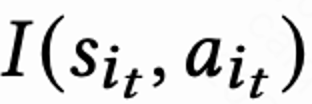 。 当用户离开 App 时本 session 结束,用户下一次打开 App session i+1 开启,上一个 session 结尾和下一个 session 开始的时间间隔被称为回访时间(Returning time),
。 当用户离开 App 时本 session 结束,用户下一次打开 App session i+1 开启,上一个 session 结尾和下一个 session 开始的时间间隔被称为回访时间(Returning time),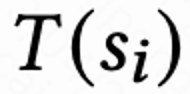 。 该研究的目标是训练策略最小化多个 session 的回访时间之和。
。 该研究的目标是训练策略最小化多个 session 的回访时间之和。
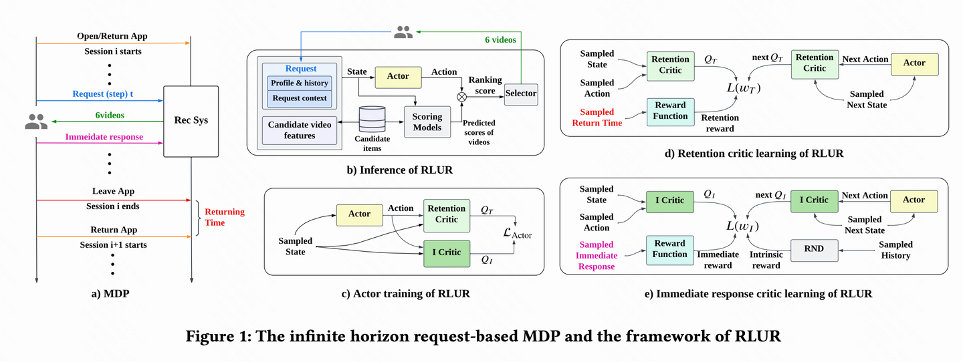
该工作首先讨论怎么预估累计回访时间,然后提出方法解决留存信号的几个关键挑战。这些方法汇总成 Reinforcement Learning for User Retention algorithm,简写为 RLUR。如图 1(d)所示,由于动作是连续的,该工作采取 DDPG 算法的 temporal difference(TD)学习方式预估回访时间。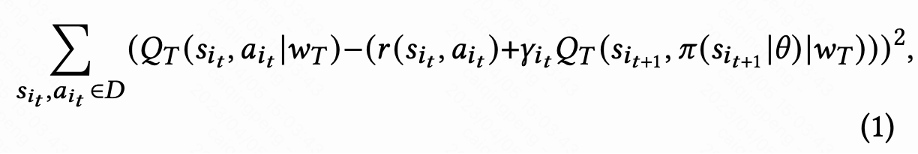
由于每个 session 最后一次请求才有回访时间 reward,中间 reward 为 0,作者设置折扣因子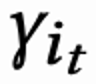 在每个 session 最后一次请求取值为
在每个 session 最后一次请求取值为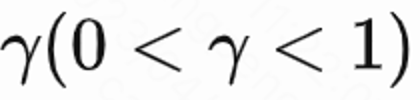 ,其他请求为 1。这样的设定能够避免回访时间指数衰减。并且从理论上可以证明当 loss(1)为 0 时,Q 实际上预估多个 session 的累计回访时间,
,其他请求为 1。这样的设定能够避免回访时间指数衰减。并且从理论上可以证明当 loss(1)为 0 时,Q 实际上预估多个 session 的累计回访时间,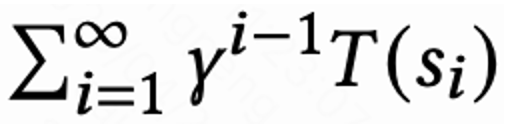 。 由于回访时间只发生在每个 session 结束,这会带来学习效率低的问题。因而作者运用启发式奖励来增强策略学习。由于短期反馈和留存是正相关关系,因而作者把短期反馈作为第一种启发式奖励。并且作者采用 Random Network Distillation(RND)网络来计算每个样本的内在奖励作为第二种启发式奖励。具体而言 RND 网络采用 2 个相同的网络结构,一个网络随机初始化 fixed,另外一个网络拟合这个固定网络,拟合 loss 作为内在奖励。如图 1(e)所示,为了减少启发式奖励对留存奖励的干扰,该工作学习一个单独的 Critic 网络,用来估计短期反馈和内在奖励之和。即
。 由于回访时间只发生在每个 session 结束,这会带来学习效率低的问题。因而作者运用启发式奖励来增强策略学习。由于短期反馈和留存是正相关关系,因而作者把短期反馈作为第一种启发式奖励。并且作者采用 Random Network Distillation(RND)网络来计算每个样本的内在奖励作为第二种启发式奖励。具体而言 RND 网络采用 2 个相同的网络结构,一个网络随机初始化 fixed,另外一个网络拟合这个固定网络,拟合 loss 作为内在奖励。如图 1(e)所示,为了减少启发式奖励对留存奖励的干扰,该工作学习一个单独的 Critic 网络,用来估计短期反馈和内在奖励之和。即 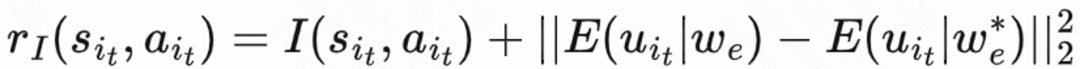 。由于回访时间受到很多推荐之外的因素影响,不确定度高,这会影响学习效果。该工作提出一个正则化方法来减少方差:首先预估一个分类模型
。由于回访时间受到很多推荐之外的因素影响,不确定度高,这会影响学习效果。该工作提出一个正则化方法来减少方差:首先预估一个分类模型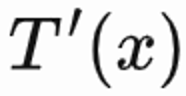 来预估回访时间概率,即预估回访时间是否短于
来预估回访时间概率,即预估回访时间是否短于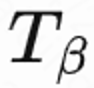 ;然后用马尔可夫不等式得到回访时间下界,
;然后用马尔可夫不等式得到回访时间下界,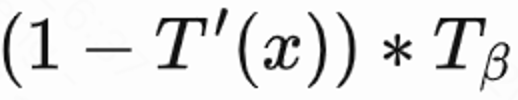 ; 最后用真实回访时间 / 预估回访时间下界作为正则化的回访 reward。
; 最后用真实回访时间 / 预估回访时间下界作为正则化的回访 reward。
由于不同活跃度群体的行为习惯差异大,高活用户留存率高并且训练样本数量也显著多于低活用户,这会导致模型学习被高活用户主导。为解决这个问题,该工作对高活和低活不同群体学习 2 个独立策略,采用不同的数据流进行训练,Actor 最小化回访时间同时最大化辅助奖励。如图 1(c),以高活群体为例,Actor loss 为: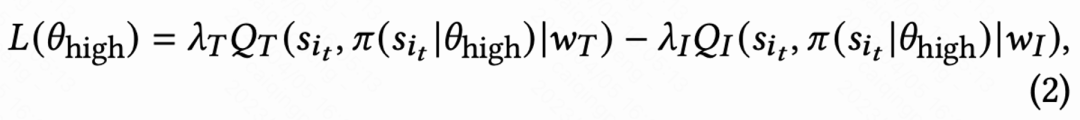
由于回访时间信号延迟,一般在几个小时到数天内返回,这会导致 RL 在线训练不稳定。而直接使用现有的 behavior cloning 的方式要么极大限制学习速度要么不能保证稳定学习。因而该工作提出一个新的软正则化方法,即在 actor loss 乘上一个软正则化系数: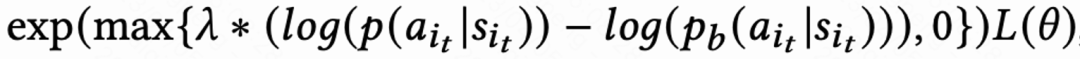
这个正则化方法本质上是一种制动效应:如果当前学习策略和样本策略偏差很大,这个 loss 会变小,学习会趋于稳定;如果学习速度趋于稳定,这个 loss 重新变大,学习速度加快。当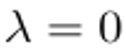 ,代表着对学习过程不加任何约束。
,代表着对学习过程不加任何约束。
该工作把 RLUR 和 State of the Art 的强化学习算法 TD3,以及黑盒优化方法 Cross Entropy Method (CEM) 在公开数据集 KuaiRand 进行对比。该工作首先基于 KuaiRand 数据集搭建一个留存模拟器:包含用户立即反馈,用户离开 Session 以及用户回访 App 三个模块,然后在这个留存模拟器评测方法。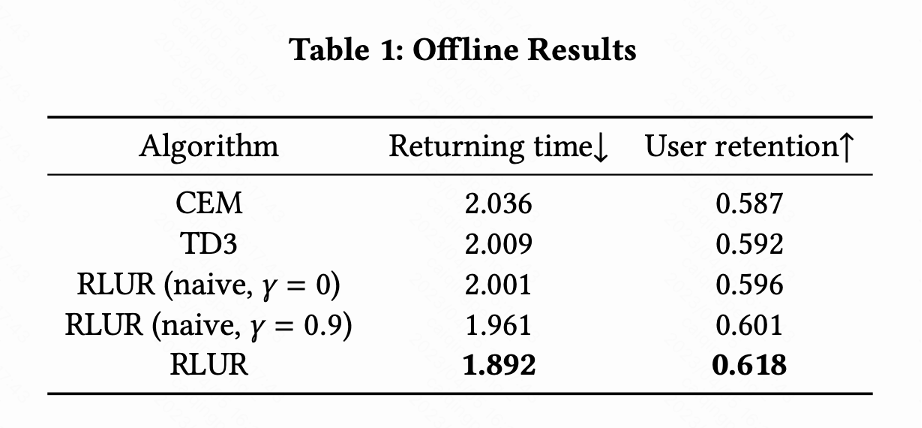
表 1 说明 RLUR 在回访时间和次留指标显著优于 CEM 和 TD3。该研究进行消融实验,对比 RLUR 和只保留留存学习部分 (RLUR (naive)),可以说明该研究针对留存挑战解决方法的有效性。并且通过 和
和 对比,说明最小化多个 session 的回访时间的算法效果优于只最小化单个 session 的回访时间。
对比,说明最小化多个 session 的回访时间的算法效果优于只最小化单个 session 的回访时间。
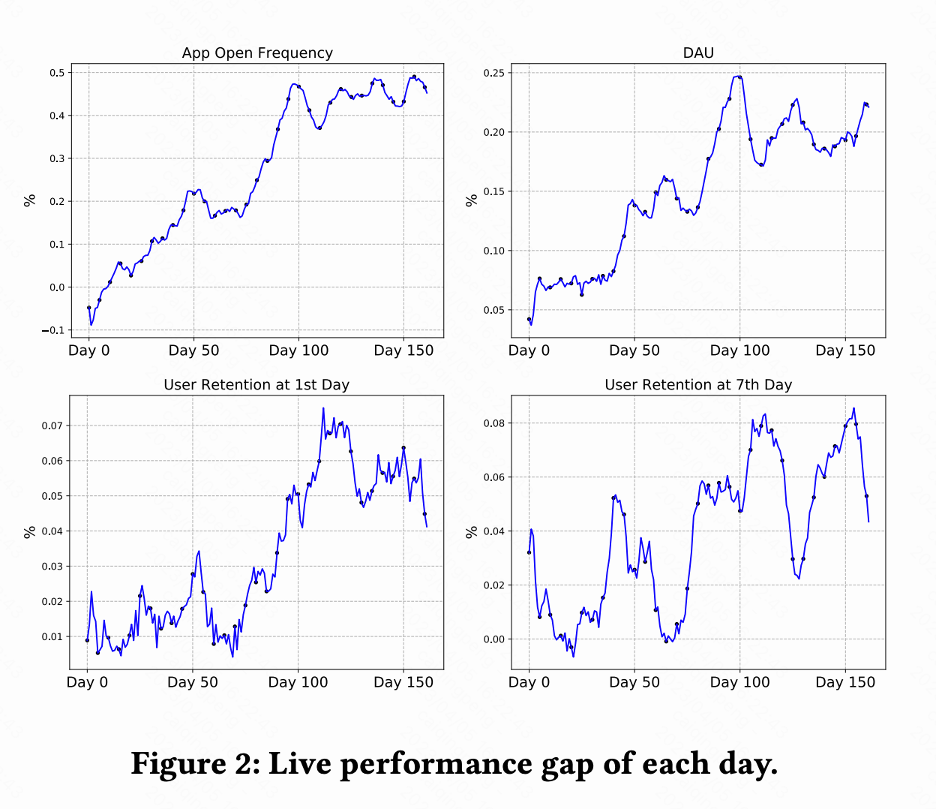
该工作在快手短视频推荐系统进行 A/B 测试对比 RLUR 和 CEM 方法。图 2 分别显示 RLUR 对比 CEM 的 App 打开频次、DAU、次留、7 留的提升百分比。可以发现 App 打开频次在 0-100 天逐渐提升乃至收敛。并且也拉动次留、7 留以及 DAU 指标的提升(0.1% 的 DAU 以及 0.01% 的次留提升视为统计显著)。本文研究如何通过 RL 技术提升推荐系统用户留存,该工作将留存优化建模成一个无穷视野请求粒度的马尔可夫决策过程,该工作提出 RLUR 算法直接优化留存并有效地应对留存信号的几个关键挑战。RLUR 算法已在快手 App 全量,能够拿到显著的次留和 DAU 收益。关于未来工作,如何采用离线强化学习、Decision Transformer 等方法更有效地提升用户留存是一个很有前景的方向。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:[email protected]