这篇文章中探讨了联邦学习中的关键学习期(CLP)问题。
关于关键学习期问题,我们之前撰写过这样一篇文章深度学习中的关键学习期(Critical learning periods)。生物学领域的研究人员已经确定,人类或动物存在关键期的原因是对神经元可塑性窗口的生物化学调控(the biochemical modulation of windows of neuronal plasticity)[1]。从生物学角度来看,关键期(critical periods)是指出生后早期发育的时间窗口,在这期间,感知缺陷可能导致永久性的技能损伤。生物学领域的研究人员已经发现并记录了影响一系列物种和系统的关键期,包括小猫的视力、鸟类的歌曲学习等等。对于人类来说,在视觉发育的关键时期,未被矫正的眼睛缺陷(如斜视、白内障)会导致 1/50 的成人弱视。而文献 [2] 中,作者提出了这样一个概念:对于深度神经网络来说,与动物和人类的学习过程类似,其对于技能的学习过程也存在一个 “关键学习期”。他认为,深度神经网络学习中存在的 “关键期” 可能来自于信息处理,而不是生化现象。具体是指,在深度神经网络的训练过程中,早期阶段与其它阶段具有不同的 “特点”。类似的,我们在这篇文章中讨论联邦学习中的关键学习期。联邦学习(Federated Learning,FL)是一种利用分散数据训练机器学习(ML)模型的流行技术。已有大量著作对 FL 最终训练得到的全局模型的性能进行了研究,但仍不清楚训练过程如何影响最终测试的准确性。此外,FL 的执行与传统的 ML 有很大不同,客户端之间的数据特征不尽相同,涉及更多的超参数。因此,有研究人员分析,FL 的最终测试准确度会受到训练过程早期阶段的显著影响,即 FL 会出现关键学习期,在此期间,微小的梯度误差会对最终测试准确度造成不可挽回的影响 [3]。在明确 FL 中存在关键学习期的基础上,我们进一步探讨如何利用关键学习期优化联邦学习,具体包括增强联邦学习客户端选择 [4] 和防御模型中毒攻击 [5]。
本文通过系统的实验和理论分析,发现 FL 中的关键学习期,并强调抓住关键学习期以提高 FL 训练效率的必要性。具体来说,通过对不同的 ML 模型和数据集进行一系列实验,作者观察到 FL 训练过程中存在关键学习期。作者进一步提出了一种名为 "Federated Fisher Information Matrix (FedFIM)" 的新指标来描述和解释这一现象。FedFIM 是基于 Fisher 信息矩阵(FIM)这一经典统计概念计算出来的,它能有效近似 FL 中损失面的局部曲率。本文研究表明,可以使用 FedFIM 的迹来解释 FL 的关键学习期现象,该迹反映了从 FL 训练开始时每个客户端的局部曲率。作者首先做出假设:FL 得到的全局模型的最终准确度会受到初始学习阶段的显著影响,我们称之为 FL 的关键学习期。考虑一个具有损失函数 l (x; w) 的模型,使用 FedAvg 在整个训练数据集 D 上对 N 个分散客户端进行优化,l 达到最小损失 l_loss,测试准确为 l_acc。此外,考虑在前 M 轮通信中仅使用本地训练数据集 D'_j ⊂ Dj , ∀j ∈ N 的子集对所有客户端的 FedAvg 进行优化,之后再使用整个训练数据集 D。然后,l 达到最小损耗 l'_loss (M),测试准确度为 l'_acc (M)。关键学习期表明,存在 M1 和 M2,当 M1 ≤ M2 时,l'_acc (M1)≥ l'_acc (M2)。初始学习阶段是决定 FL 最终性能的关键,无论进行多少额外的训练,都无法克服关键学习期训练不足的影响。为了展示 FL 中的关键学习期,作者在 CIFAR-10 、 CIFAR-100 上针对 ResNet-18 和 CNN 两个模型进行了实验。为了说明 FL 中关键学习期的存在,作者使用了 FL 领域最经典的 FedAvg [6],作者具体考虑了 FedAvg 在整个训练过程中基于全部训练数据集训练,以及每个客户端上只有训练数据集的一个子集参与前 M 轮通信时的性能。作者将 M 称为 “Recovering Round”,并将 R 表示为参与训练的本地数据集的比率。考虑一个具有 N=64 个客户端的系统,FedAvg 在每轮中随机选择 12 个客户端的子集。批大小为 16。初始学习率设置为 0.01,每轮衰减 0.97。对于权重衰减为 5×10^−4 的学习率,作者采用了使用 exponential annealing scheduling 的 SGD solver。- 目的:想知道早期使用部分数据和前多少个 epoch 是关键时期对模型的影响
图 1(上)报告了受部分训练数据集影响的 FL 的最终性能。其中,不同比率 R 是 recover round M 的函数。所有结果一致表明,关键学习期存在于所有环境中。在早期学习阶段涉及的本地数据集比例不同的前提下,如果训练数据集没有恢复到整个数据集,最早在第 20 轮通信中,FL 的最终测试准确度与标准 FedAvg 相比会严重下降。比较早期训练阶段本地数据集的不同比例 R,我们不难发现,早期训练阶段本地数据集的比例 R 越低,越容易清晰展示出关键学习期。作者进一步评估了实现相应最终准确度所需的总通信轮次,如图 1(下)所示。
图 1. FL 表现出的关键学习期。(上)ResNet-18 使用 FedAvg 在 IID 和 Non-IID CIFAR-10 上实现的最终准确度,使用部分局部数据集(其中 R 表示局部数据集的比率)进行训练,作为将部分训练数据集恢复为整个训练数据集的通信轮次的函数。如果训练数据集没有足够早地恢复到整个训练数据集,无论进行多少轮额外的训练,FL 的测试准确度都会受到永久性的损害。(下)通信轮次与恢复轮次(RC#)。实现相应最终准确度所需的总通信轮次作为恢复轮次的函数显著增加
- 实验 2:Constant Learing Rate
- 目的:这个实验说明固定的初始学习率与训练性能关系并不大:如果学习率与关键训练时期有关系,那么随着 recover round 不断增加,不同学习率的曲线 recover round=0 的差值 <....<recover round=80 的差值 <....<recover round=200 的差值
接下来,作者进行了与图 1 中相同的实验,但使用了恒定的学习率而不是退火方案。具体将恒定学习率分别设置为 0.001 和 0.003。由图 2,即使学习率不变,我们仍然观察到 FL 中存在关键学习期。因此,作者分析,FL 中的关键学习期现象不是由后面几轮中的退火学习率引起的,并且不能仅根据下式中优化的损失来解释: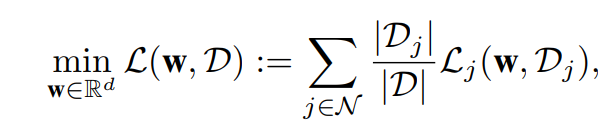
其中,w 表示模型参数,N 表示客户端集,D_j 是客户端 j∈N 的局部数据集,整个训练数据集为 D=∪_(j∈N) D_j,L_j (w,D_j) 是客户端 j 的局部损失函数。- 目的:这个实验说明固定的 batch size 与训练性能关系也不大,结果同实验 2:如果 batch_size 与关键训练时期有关系,那么随着 recover round 不断增加,不同 batch_size 的曲线 recover round=0 的差值 <....<recover round=80 的差值 <....<recover round=200 的差值
图 3 给出了说明批大小影响的类似结果。同样,无论批大小的选择如何,关键学习期都始终存在。这进一步表明,FL 关键学习期的现象不能简单地用批大小的差异来解释。
图 2. FL 中关键学习期的存在:FedAvg 在 ResNet-18 上使用 IID 和 Non-IID CIFAR-10 进行训练,学习率不变
图 3. FL 中关键学习期的存在:FedAvg 在 ResNet-18 上使用不同批大小(BS)的 IID 和 Non-IID CIFAR-10 进行训练- 目的:加入不同的 weight decay,各个曲线的性能如何
类似地,图 4 给出与图 1 相同但权重衰减不同的实验结果。我们仍然观察到了如图 1 中存在的关键学习期,但令人惊讶的是,关键学习期的形状对权重衰减值是鲁棒的,即,改变权重衰减不会影响关键学习期形状。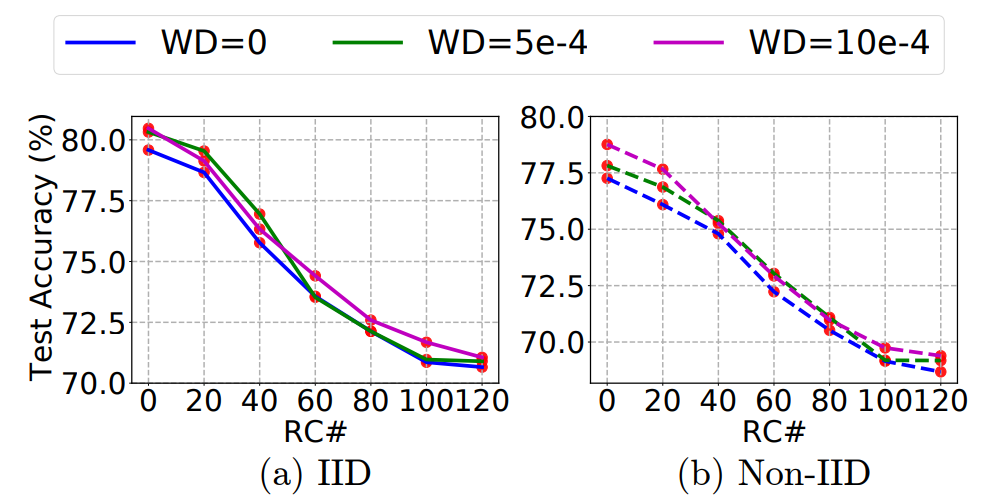
图 4. FL 中关键学习期的存在:FedAvg 在 ResNet-18 上使用 IID 和 Non-IID CIFAR-10 进行训练,具有不同的权重衰减(WD)通过上文大量的实验,作者分析,已经能够表明训练过程的初始学习阶段对 FL 的最终测试准确度起着关键作用。进一步,作者通过本节中展示的工作表明,上文实验中展示出的现象可以通过联邦 Fisher 信息矩阵(FedFIM)的迹来解释,FedFIM 的迹反映了从 FL 训练开始每个客户端的局部曲率。中心化训练的 Fisher 信息矩阵(FIM)如下式所示: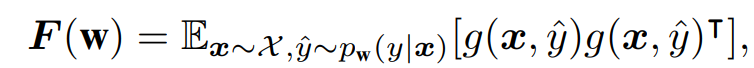
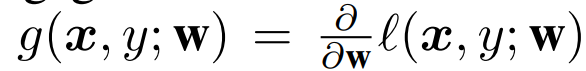
其中,I (x, y; w) 为针对输入 x 和标签 y 计算出的交叉熵损失函数。FIM 可以被视为权重扰动对网络输出影响程度的局部度量,也可以被视为损失函数的 Hessian 近似,因此也可以被看作是训练期间特定点 w 处损失 landscape 的曲率近似。下面介绍在联邦环境中 FIM 的计算。客户端 j 的 FIM 为:
其中,X_j 是客户端 j 的本地数据集 D_j 的经验分布。F_j (w) 是使用局部数据集 D_j 上的全局模型 w 来计算的,并且可以被认为是从客户端 j 的角度测量全局模型的扰动如何影响 FL 训练性能的局部度量。因此,全局模型扰动对最终输出的总体影响,作者将其定义为 FL 的联邦 Fisher 信息矩阵(FedFIM)FedF,可以使用所有客户端的本地 FIM 的加权平均值来计算: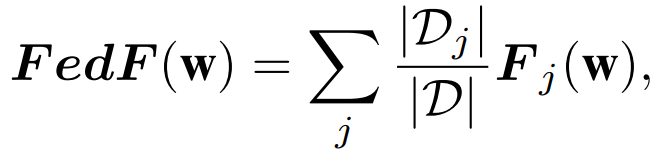
将 FedF 的迹表示为 Tr (FedF)。根据这个公式,我们可以看到 FIM 的变化由 2 部分组成:参数变化很大时会导致梯度比较大进而导致 FIM 比较大;梯度稳定后如果数据不断增加同样会导致 FIM 增加。本章节继续给出实验结果,用 FIM 解释 FL 关键学习期。- 实验 5 和实验 6(IID 和 Non-IID):取 R=0.3,然后取不同的 recover rounds

图 5. FL 中的关键学习期与 ResNet-18 在 IID CIFAR-10 和 FedAvg 上实现的联邦 Fisher 信息之间的联系,使用 30% 的本地数据集进行初始训练,并在恢复时恢复到整个数据集。(a) 测试准确度与恢复轮次(Recovering Round):如果训练数据集最早在第 20 轮次没有完全恢复,最终测试准确度将永久受损;(b) FedFIM 的迹与恢复轮次。在早期训练阶段,FedFIM 的迹急剧增大;(c) FedFIM 迹与恢复轮次的加权累积和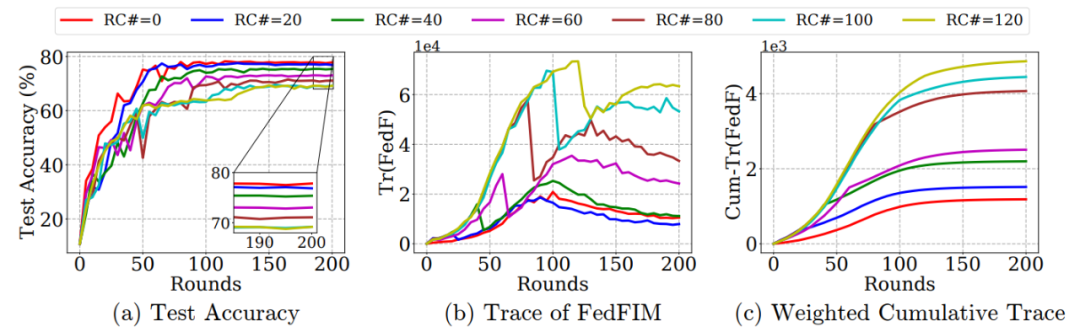
图 6. FL 中的关键学习期与 ResNet-18 在 Non-IID CIFAR-10 上使用 FedAvg 实现的联邦 Fisher 信息之间的联系,使用 30% 的本地数据集进行初始训练,并在恢复轮次后恢复到整个数据集由图 5 和图 6 的实验结果,我们从 (a) 是可以发现:recover round 不同时,当训练结束后还是性能有所差距,存在关键训练周期;其次,由 (b) 我们能看到三个变化趋势:(1)在训练初期 FIM 均会剧烈的增加,因为准确度在不断上升,梯度变化很大;(2)当准确度平稳时,平稳趋近定值,梯度的变化越来越小导致 FIM 又在减少;(3)逐渐增加最终趋于平稳,这是因为刚开始使用部分数据,现在使用完整数据,数据量增加了导致 FIM 变大。不过,我们也看到,在 recover round 不断增加时,准确度在减小,即使后期采用完整数据集,性能还是没法超越 recover round 小的情形。最后,从 (c) 可以更加直观的看到:recover round 越大,平稳性越差,而且 FIM 越大对应模型信息越少,后期恢复导致更大的 weight cumulative trace 。此外,图 b 是直接加和得到的,图 c 是加权聚合得到的(可以防止噪声,根据数据量作为加权衡量标准可以增加模型的鲁棒性)。图 c 中使用到的公式如下: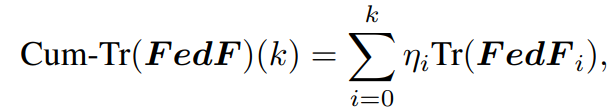
最后,作者想要进一步的探讨如何使用关键学习期来提升训练效率,如探讨客户端选择对于性能的影响以及数据使用情况对于性能的影响。作者设置了 6 种策略进行讨论(分别对应图 7 和图 8 中的 6 条曲线):3. 启发式算法:所有客户端在关键学习期参加训练,之后采样的客户端(例如,60%)参与训练。5. 部分数据:每个客户端仅使用部分本地数据集(例如,25%)。6. 启发式算法:每个客户端在关键学习期使用其整个本地数据集,之后仅使用其部分本地数据集。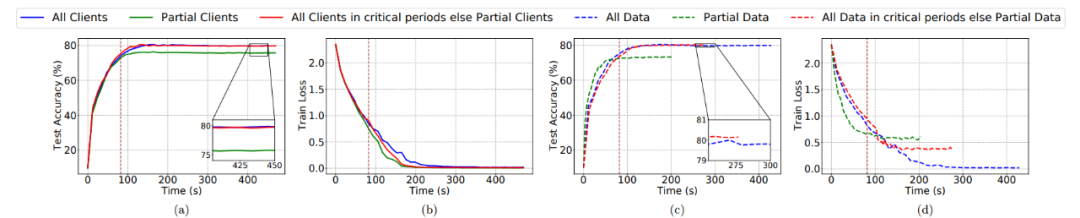
图 7. 利用 IID CIFAR-10 上的 ResNet-18 分析 FL 训练的关键学习期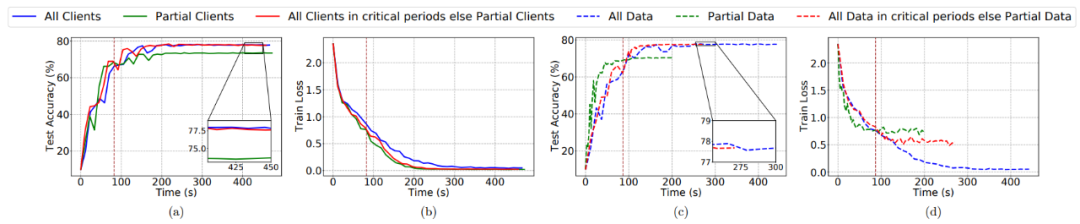
图 8. 用 ResNet-18 在 Non-IID CIFAR-10 上分析 FL 训练的关键学习期从由实验 7 和实验 8 图,(a)可以看出:第一种和第三种性能 > 第二种,而且第三种在后期只有部分客户端参与训练,所以第三种是最优的;(b)可以看出:三种方法在 loss 上并没有什么差别,而方法 3 最优;(c)可以看出:第 4 种和第 6 种性能 > 第 5 种,而且第 6 种在后期只使用部分数据集参与训练,所以第 6 种是最优的;(d)可以看出:loss:第 4 种 < 第 6 种 < 第 5 种;通信消耗:第 4 种 > 第 6 种 > 第 5 种。总体而言,当在 IID 和 Non-IID CIFAR-10 数据集上训练 ResNet-18 时,我们可以节省 40%-50% 的训练时间和 50%-65% 的总客户端数量,但可以实现接近最终的模型准确度。1. 初期训练对于模型性能有很大影响:特别是初期只使用一部分数据集对性能损害是最大的,所以我们选择在初期训练每个客户端使用全部数据集,再经过初期训练后可以使用部分数据集(实验 7 和 8),这样并不会损害性能而且可以提升通信效率;2. weight decay 对初期训练具有鲁棒性,即不需要反复调整 weight decay 这个超参数,它的调整对模型性能影响很小;3. Batch_size 和 Constant learning rate 影响也不大,可以做小幅度调整;4. 我们不仅仅要关注模型的性能例如通信效率,也要分析模型的泛化性能,例如本文的 Fish information。在上一章中,我们分析了一篇联邦学习的实验论文,具体探究了早期训练对最终模型性能的影响。既然我们通过实验发现了联邦学习中存在关键学习期,那么我们是否能利用关键学习期来优化联邦学习呢?本章我们通过两篇论文,探讨可能的优化途径。
联邦学习(FL)是一种分布式优化范式,它从分布在多个客户端的数据样本中学习。根据客户端训练进展来适应性地选择客户端参与全局训练已成为提高 FL 效率的主要趋势,但目前尚未研究的非常清晰。大多数现有的 FL 方法,如 FedAvg 及其变体,都假设 FL 训练过程中的所有学习阶段都同样重要。由上一篇我们分析的联邦学习中的关键学习期( critical learning periods, CLP)的研究结果,这一假设被证明是无效的。本文提出了 CriticalFL,这是一个 CLP 增强的 FL 框架,使用 CLP 自适应地增强现有的 FL 方法。本文证明,利用 CLP 指导客户端选择,能够显著提高联邦学习的性能。本文提出利用 federated gradient norm (FGN) 检测关键学习期。考虑单个数据样本的训练损失差异 ξ,利用下式表征 ξ 上损失函数的梯度:
在对该样本执行步骤 SGD 之后,如下的训练损失可以通过使用泰勒展开的梯度范数来近似: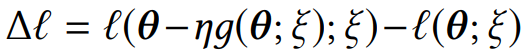
因此,第 t 轮的总体训练损失(将其定义为 FGN),可以使用所有选定客户端的训练损失的加权平均值来近似:
然后,作者开发了一个简单的基于阈值的规则来检测基于 FGN 的 CLP,如下所示: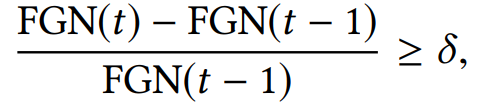
作者在文中提出的 CriticalFL 框架是以 FedAvg 为基础的,作者也表示,该框架可以很容易地与其他现有方法相结合。根据上一篇文章中通过大量实验结果对 CLP 的分析,初始阶段如果没有足够的客户端参与 CLP,无论 CLP 之后进行了多少额外的训练,最终模型的准确度都会受到永久性的损害。因此,CriticalFL 将 FedAvg 的选定客户端数量从 n_0 增加到 2n_0,这意味着有更多的客户端在 CLP 期间的下一轮中参与改进全局模型。使用从上一轮学习到的模型 θn_0 作为初始模型,选择的 2n_0 个客户端使用 FedAvg 继续学习以获得全局模型 θ2n_0。当通信轮次仍在 CLP 中时(如下算法中的第 5 行和第 8 行),上述增加所选客户端数量的过程继续进行,直到所选客户端的集合包含所有可用的 M 个客户端。不过,由于在 CriticalFL 中的 CLP 期间选择了更多的客户端,这不仅使直接与 FedAvg 进行效果比较不公平,而且还导致客户端和中央服务器之间的通信更多。为此,作者提出两个方法来解决这两个问题。一方面,CriticalFL 在 CLP 之后开始逐渐减少所选客户端的数量(如下算法中的第 12 行),这是因为使用部分数据集的最终准确度与使用 CLP 之后的所有数据集的准确度相似。这不仅使 CriticalFL 中每轮选择的客户端的平均数量与 FedAvg 相当,而且提高了通信效率。另一方面,CriticalFL 中所选的客户端只向中央服务器发送其更新的具有最大梯度的本地模型的 L 个参数。为了简单起见,将客户端 k 的本地更新参数 θk 中的位置指示符表示为 mk,因此只有 θk⊙mk 与中央服务器共享,而不是 θk 本身(算法 2 中的第 6 行)。这是由于观察到并非所有参数在训练过程中都很重要,可以利用稀疏化方法进一步提高 CriticalFL 的通信效率。从另外的角度分析,CriticalFL 在学习过程的初始阶段利用了比每轮 FedAvg 固定数量的客户端更多的客户端,以更快地达到更高准确度的全局模型,因为初始学习阶段在 FL 性能中起着关键作用。通过这样做,在 CLP 期间,SGD 能够定位到全局模型 loss surface 的较陡部分,因为大量的数据样本对全局模型有贡献。然而,这种方法的通信开销相对较大,因为在每一轮通信中都有更多的客户端参与 FL 训练。通过在 CLP 期间仅与中央服务器共享每个客户端的前 L 个本地参数,并在 CLP 之后逐渐减少所选客户端的数量,CriticalFL 的通信开销得到了改善,而不会损害最终模型的准确度。关键是在最初的学习阶段有更多的客户端加入训练过程,而 CLP 之后只需要少量的客户端。因此,CriticalFL 在保持比 FedAvg 更好的通信效率的同时,持续提高了模型的准确度。
备注 1。由于 CriticalFL 提供了一个通用框架,以在联邦学习设置中使用已识别的 CLP 来改进客户端选择,因此需要指定内部优化子程序(例如,算法 2 中的第 2、4、7 和 11 行),以量化所提出方法的改进。特别是,作者在算法 2 中将子程序设置为 FedAvg,因为它是最常见的算法,也是联邦学习中许多变体方法依托的基础构建块。此外,CriticalFL 中的每个客户端仅在 CLP 期间向中央服务器发送其更新的本地模型的前 L 个参数(算法 2 中的第 6 行)。然而,CriticalFL 并不局限于此,并且可以很容易地用其他稀疏化方法进行推广。为了评估 CriticalFL 框架性能,作者拟完成如下实验:1. 在最终测试准确性和通信效率方面,与 FedAvg 相比,使用我们的 CriticalFL 框架有什么好处?2. 当 CriticalFL 框架的内部优化子程序(例如,算法 2 中的第 2、4、7 和 11 行)被其他现有技术所取代时,其泛化性能如何?3. 不同的超参数如何影响 CriticalFL 框架的性能?实验考虑两个任务:(i)CIFAR-10 和 CIFAR-100 以及 Fashion MNIST 数据集的图像分类;(ii)《威廉・莎士比亚全集》(莎士比亚)数据集的下一个人物预测。作者使用了四个具有代表性的 DNN 模型:用于 CIFAR-10 和 Fashion MNIST 的 AlexNet 和 VGG-11,用于 CIFAR-100 的 ResNet-18,以及用于 Shakespeare 的堆叠字符级 LSTM 语言模型。- 实验 1:CriticalFL 和 FedAvg 的测试准确度和通信效率
- 目的:通过对比 CriticalFL 和 FedAvg ,讨论 CLP 的重要作用
表 1 中总结了 CriticalFL 和 FedAvg 在 Non-IID 分区数据集上的最终测试准确度,FedAvg 每轮选择 16 个客户端(两列对应于 FedAvg)。由表 1 中的实验结果,CriticalFL 在所有场景中都始终优于 FedAvg,最终测试准确度提高了 9%。当使用参数为 0.1 的 Dirichlet 分布在客户端之间划分数据集时,其优势尤其明显,即,客户端之间的数据集高度 Non-IID。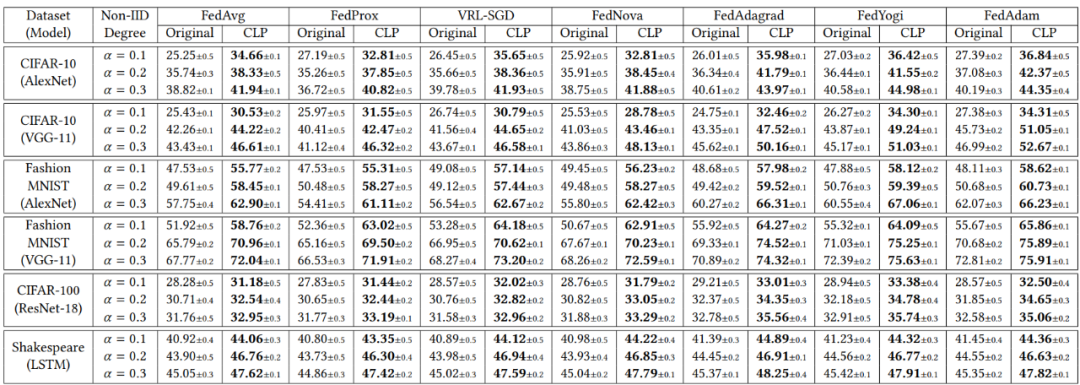
表 1. 利用 CriticalFL 框架,使用具有不同模型的各种 Non-IID 数据集,对最先进的 FL 算法(“Original” 列)和相应的 CLP 增强方法(“CLP” 列)的最终测试准确度通过通信效率进一步体现了 CriticalFL 的优势。作者进一步报告了 FedAvg 和 CriticalFL 为实现给定目标准确度所需的通信轮次。由于 CriticalFL 的最终测试准确度高于 FedAvg,作者将目标准确度设置为 FedAvg 的最终测试准确度(如表 1 所示)。从表 2 中可以清楚地看出,CriticalFL 需要更少的通信轮次就可以实现相同的测试准确度。同样,这一优势在高度 non-IID 的数据集上更加明显。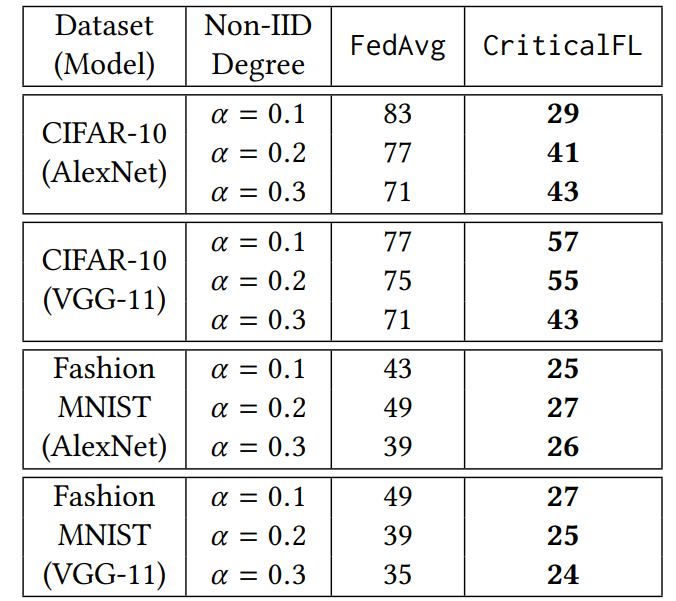
表 2. FedAvg 和 CriticalFL 所需的通信轮次,以实现 Non-IID CIFAR-10 和 Fashion MNIST 的目标准确度作者具体研究了 CriticalFL 的泛化性能,并考虑了六种现有技术,即 FedProx、VRL-SGD、FedNova,以及 FedOPT,使用了三种方法,即 FedAdagrad、FedYogi 和 FedAdam。作者将相应的 CLP 增强方法分别称为 CriticalProx、CriticalVRL、CriticalNova、CriticalAdagrd、CriticalYogi 和 CriticalAdam。我们注意到,FedProx 的性能取决于超参数 µ,即与每个局部目标的近端项相关的系数。作者使用网格搜索来调整这个参数,并报告 AlexNet 实验的最佳值 µ=0.01,所有其他模型的最佳值为 µ=0.001。表 1 展示了 128 个客户端的 Non-IID 数据集的最终测试准确度,其中 FedProx、VRL-SGD、FedNova、FedAdagrad、FedYogi 和 FedAdam 在每轮中选择了 16 个客户端。如图 9 所示,与相应的基线 FedProx 相比,CriticalProx 实现最终测试准确度的总体通信成本较小,同时保持每轮参与的客户端的平均数量相当。类似地,CriticalProx 需要更少的通信轮次来实现目标准确度,如表 3 所示。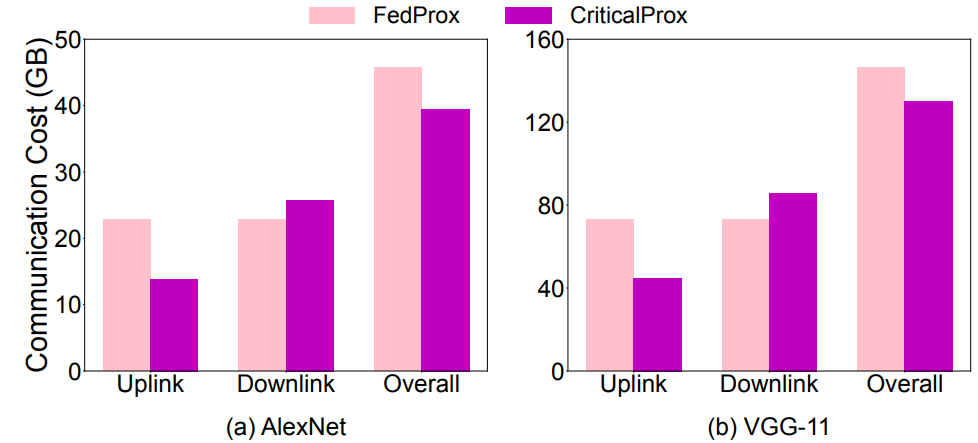
图 9. FedProx 和 CriticalProx 在 Non-IID CIFAR-10 上的通信成本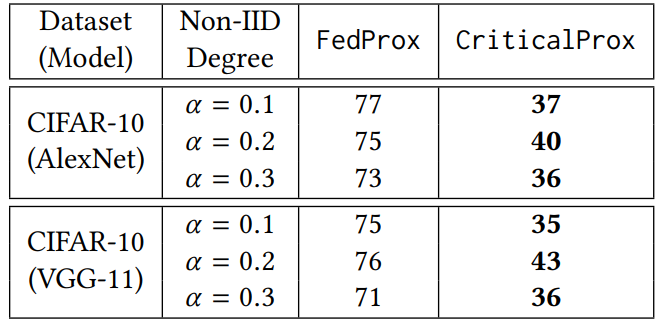
表 3. FedProx 和 CriticalProx 要求的通信轮次,以实现 Non-IID CIFAR-10 的目标准确度- 目的:评估超参数对 CriticalFL 性能的影响
Detection Thresholds. 评估用于声明 CLP 的阈值 δ 的灵敏度。候选值为{0、0.01、0.03、0.05、0.2、0.35、0.5},在 Non-IID CIFAR-10 和 Fashion MNIST 上使用 AlexNet 的 CriticalFL 的相应最终测试准确度如图 10 所示。当 data partition 高度 Non-IID(即,α=0.1)时,由 δ 确定的 CLP declaration 对最终准确度有明显影响。这是因为随着 δ 变得更大,在初始阶段宣布为 CLP 的轮次更少。因此,CLP 增强对最终测试准确度的影响变小了,因为与 FedAvg 相比,CriticalFL 在更少的轮次中使用了更多数量的客户端。另一方面,CriticalFL 对检测过程是鲁棒的,即,当数据分区不是高度 Non-IID 时,可以容忍具有不同阈值的检测错误。
Non-IID Degree. 使用 AlexNet 评估 E( local training epochs )对 Non-IID CIFAR-10 和 Fashion MNIST 的影响,其中 α=0.1。作者考虑的候选 local epoch 是 E∈{1,2,3,4,5}。由图 11,增加 local epoch 的数量通常会提高最终测试的准确度,而 CLP 的增加会在 E 的所有值上持续提高最先进方法的最终测试准确度。由于测试准确度的增益随着 local epoch 数量的增加而表现出 “递减回报效应”,作者在实验中设置 E=2。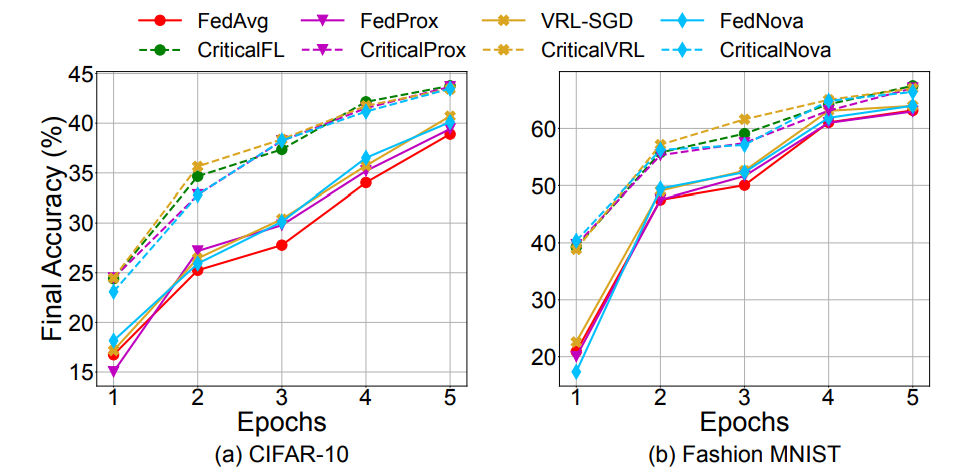
图 12. local training epochs 的影响此外,作者还针对 Weight Decay 、 Number of Clients 、 Client Participation Rate 、 Randomly Increasing and Decreasing the Number of Selected Clients、 Number of Local Parameters 以及 Relations between the Number of Selected Clients and the FGN 等进行了大量的消融实验,充分证明了 CriticalFL 框架的泛化性能,感兴趣的读者可以阅读原文。
联邦学习容易受到模型中毒(model poisoning)攻击,恶意客户端在 FL 训练过程中通过向中央服务器发送被操纵的模型更新来影响全局模型的准确度。现有的防御手段主要集中在拜占庭鲁邦的 FL 聚合上,而在很大程度上忽略了用于 FL 训练的底层深度神经网络(DNN)的影响。受 DNN 中关键学习期(CLP)的启发,本文提出了一种新的防御方法,称为 CLP 感知的 FL 中毒防御( defense against poisoning of FL,DeFL)。DeFL 的关键思想是通过易于计算的联邦梯度范数向量( federated gradient norm vector,FGNV)度量来测量 DNN 模型更新之间的细粒度差异。使用 FGNV,DeFL 可以同时检测恶意客户端并识别 CLP,进而引导从聚合中自适应删除检测到的恶意客户端。因此,DeFL 不仅减轻了对全局模型的模型中毒攻击,而且对检测错误具有鲁棒性。 Federated Gradient Norm Vector 现有的检测中毒模型更新的防御措施一般都基于将 DNN 视为黑盒的度量,例如余弦或 L2 范数。一些研究表明,不同的 DNN 层对模型中毒攻击表现出不同的脆弱性,因此可能在保护 FL 免受模型中毒攻击方面发挥不同的作用。作者设计了一种新的度量,称为联邦梯度范数向量(FGNV),该度量允许分析用于 FL 训练的 DNN,并测量模型更新之间的细粒度差异。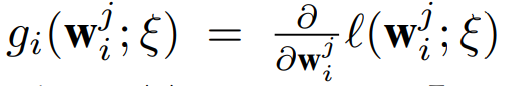
上式表示在 ξ 上评估的客户端 i 在∀j=1,・・・,L 层上的梯度更新。在对该样本执行步骤 SGD 之后,客户端 i 在层 j 上的训练损失或全局模型更新差异为: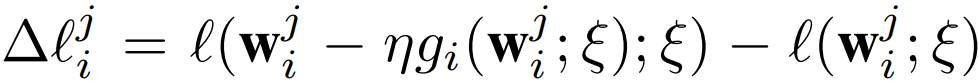
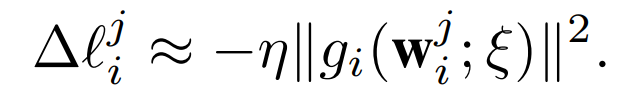
作者将其称为客户端 i 在层 j 上的 FGNVi: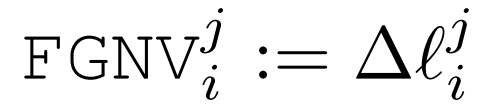
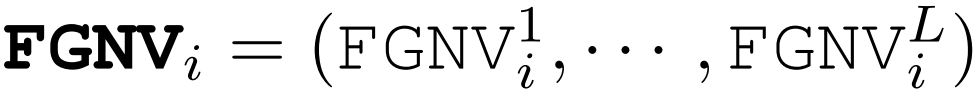
上式表示客户端 i 的联邦梯度范数向量,其表示客户端 i 在 DNN 的每一层上的全局模型更新差异。然后,可以使用所有选择的客户端上的 (FGNV_i)^j 的加权平均值来近似第 t 轮的每一层 l 上的全局模型更新差:
作者开发了一个简单的基于阈值的规则来识别基于 FGNV 的 CLP,如下所示:如果满足
则当前训练轮次 t 在 CLP 中,其中 δ 是用于在联邦设置中声明 CLP 的阈值。作者在实验中将 δ=0.05 设置为默认值。将 FGNV 方法确定的 CLP 与我们在上文介绍的 FedFIM 方法进行了比较。当在 non-IID CIFAR-10 和 Fashion MNIST 上训练 AlexNet 时,我们观察到这两种方法产生了类似的结果,如图 13 所示。FGNV 在计算上要高效得多(计算速度快几个数量级),并且可以在 FL 训练过程中以在线方式在每一轮次中轻松地利用它来防御模型中毒攻击。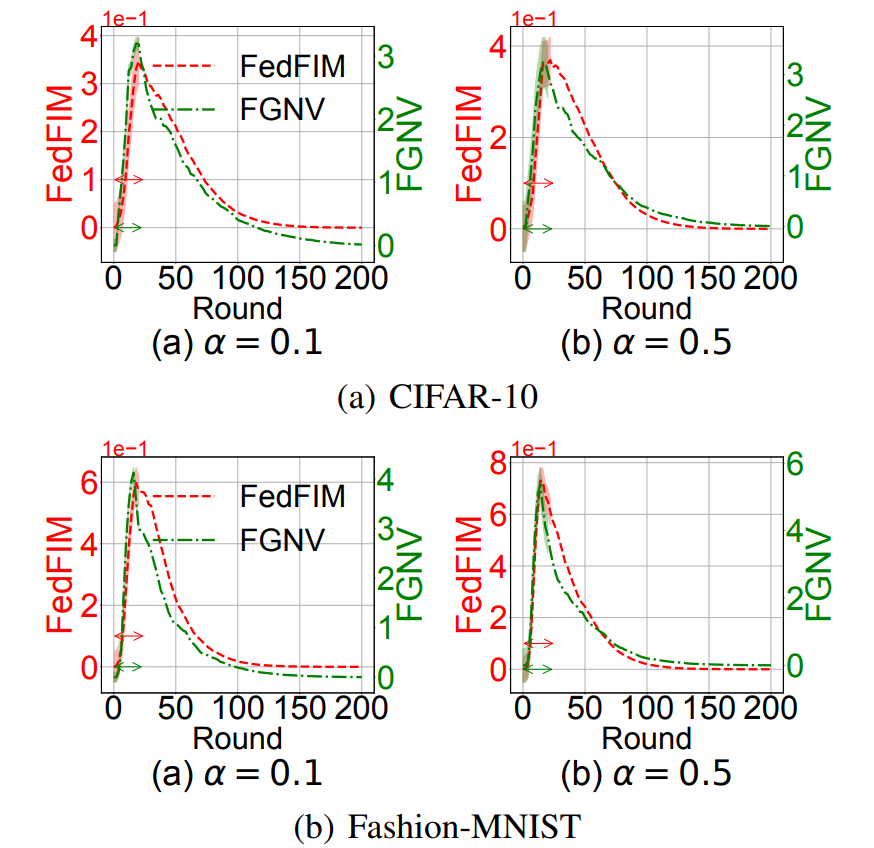
图 13. 使用 δ=0.05 的 FGNV 和 FedFIM 在联邦设置中检测 CLP 的比较,其中阴影和双箭头表示已识别的 CLP。结果使用 AlexNet 在(a)CIFAR-10 和(b)FashionMNIST 数据集上进行,这些数据集分别使用 Dirichlet 分布 Dir32 (0.1) 和 Dir32 (0.5) 在 32 个客户端上进行分区在每一轮次 t 中,我们基于上面讨论的 FGNV 来识别恶意客户端。具体来说,将恶意客户端检测视为统计异常值检测问题。与现有的将 DNN 视为黑盒的防御不同,FGNV 测量 DNN 每一层的细粒度差异。为此,作者在每个训练轮次 t 的统计轮廓检测问题中,将 FGNVi 分配给每个客户端 i 作为其特征向量,并通过利用大规模无监督异常值检测(MOOD)的统计方法来开发一种基于轻量级投票的方法,以确定客户端是否为异常值。MOUD 算法的输入是每个客户端 i 的每一层 j 上的 (FGNV_i)^j 。MOOD 算法的输出是每一层中的异常值。通常,MOUD 比较每个客户端 i 在层 j 上的全局模型更新差异的相似性,即 (FGNV_i)^j 相对于从所有参与的客户端观察到的参考,以确定客户端 i 在第 j 层上的更新是否是异常值。具体来说,每一轮次 t 中 MOOD 的计算包括以下步骤:1)基于 FGNVi,∀i∈N(t),在每一层 j 上生成参考向量为: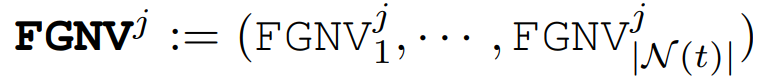
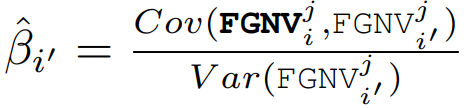
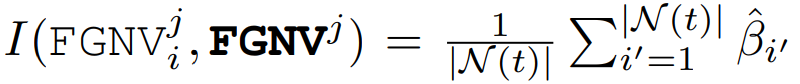
如果客户端 i 的值显著偏离其他层,则将其输出为异常值。进一步的,基于对每个客户端 i 的每个层 j 的检测,作者开发了一种简单的投票方法来确定客户端 i 是否是异常值。为了减少检测误差并提高鲁棒性,利用自适应阈值(作为从 MOUD 中声明为异常值的层数)进行投票。具体地说,首先将阈值设置为 L,即,如果 MOUD 将客户端 i 的所有 L 层输出为异常值,则客户端 i 在第 t 轮次中被声明为异常值。如果没有客户端被检测为恶意,则将阈值设为 L−1,并重复上述过程,直到至少一个客户端被确认为 “恶意”。作者将基于 FGNV 的 MOUD 与投票策略相结合的检测方法称为 MOUD Vote。根据 CLP 理论,如果全局模型在早期训练阶段受到严重影响,无论在这段时间后进行多少额外训练,最终模型的准确度都将永久受损。因此,一旦识别出 CLP,DeFL 就会从模型聚合中删除所有检测到的恶意客户端。然而,在现有的检测方法中,经常会出现误报率(false positive rate ,FPR),即良性客户端可能被误报为恶意客户端。因此,如果 DeFL 在整个训练过程中严格从模型聚合中删除所有检测到的恶意客户端,可能会损害最终模型的准确度。为此,我们进一步使用贝叶斯模型来估计客户端根据我们检测到的 CLP 和 MOUD 投票提供良好模型更新的概率。客户端提供良好模型更新的能力可以被建模为隐马尔可夫模型。在每一轮 t,客户端 i 提供良好更新的概率 pi (t) 如下所示: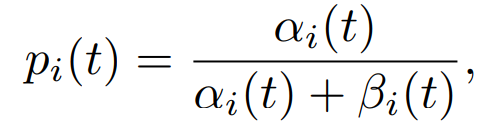
其中,αi 和 βi 是 Beta 分布的参数,如果客户端 i 在第 t 轮被 MOUD 投票声称为良性客户端(即提供良好的更新),则 αi (t)=αi (t-1)+1;否则,βi (t)=βi (t-1)+1。完整的算法见 Algorithm 1。DeFL 在学习过程的初始阶段(即检测到的 CLP)严格从模型聚合中删除所有检测到的恶意客户端,以避免对全局模型的中毒攻击,因为初始学习阶段在 FL 性能中起着关键作用。然而,恶意客户端检测可能会受到 FPR 的影响,并且从全局模型聚合中删除太多客户端可能会降低最终模型的准确度。为了解决这些问题并提高 DeFL 对 FPR 的鲁棒性,使用贝叶斯模型来增强 DeFL,以学习将 “良好” 的更新概率与每个客户端相关联。在 CLP 之后,将较小的聚合权重与全局模型聚合中检测到的恶意客户端相关联,而不是完全删除它们。同样,在 CLP 之后的全局模型聚合中,将更大的聚合权重分配给检测到的良性客户端。因此,DeFL 能够保护 FL 免受模型中毒攻击,并且对检测方法的 FPR 是鲁棒的。
作者在实验中使用 CIFAR-10、MNIST 和 Fashion MNIST 作为评估数据集。作者通过考虑数据点数量和类比例不平衡的异构分区来模拟 non-IID FL 场景。作者通过对 pi~DirN (α) 进行采样,将异构分区模拟为 N 个客户端,其中 α 是 Dirichlet 分布的参数。当 α 增加时,不同客户端的本地数据集之间的异质性水平可以降低。作者选择 α=0.1 作为默认参数。考虑三个具有代表性的 DNN 模型:AlexNet、VGG-11 和全连接网络(FC)。使用 AlexNet 和 VGG-11 分别作为 CIFAR-10 的全局模型架构,FC 用于 MNIST 和 AlexNet 用于 Fashion MNIST。作者考虑的防御手段包括:FLDetector、FLTrust、AFA、Multi-krum 和 Trimmed mean,以及以下文献中最强的四种模型中毒攻击,即 Fang、LIE、Min-Sum 和 Min-Max。此外,作者考虑了关于对手知识的两种设置:(a)完全(Full):对手知道良性客户端的梯度;(b)部分(Partial):对手对良性客户端共享的梯度更新是不可知的。作者评估了 DeFL 防御最先进的模型中毒攻击的性能,并将其与最先进的防御方法进行了比较。表 4 总结了当对手已知或未知良性梯度时,由这些防御方法进行防御时,这些攻击的影响。由于空间限制,作者仅在图 14 中显示了使用 AlexNet 对 Non-IID 分区的 CIFAR-10(α=0.1)的测试准确度。从表 4 中可以清楚地看出,DeFL 显著减轻了文献中这些最强模型中毒攻击的影响,并且 DeFL 对这些攻击的有效性比所考虑的最佳防御方法高出 12.04 倍。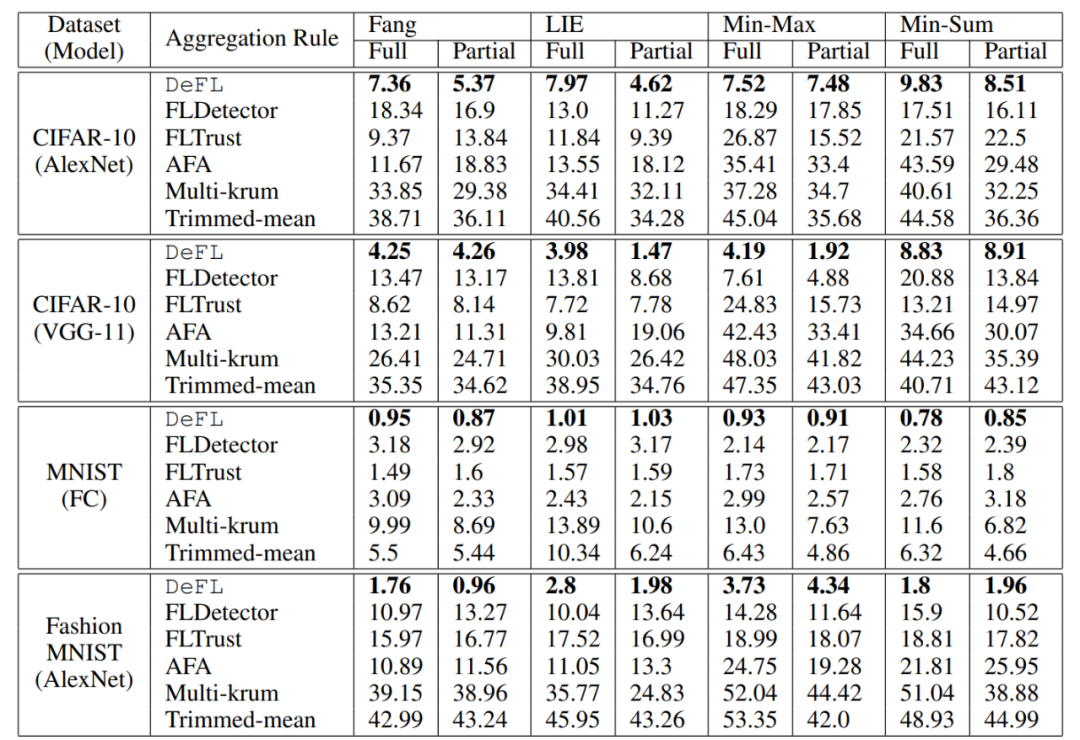
表 4. 使用 α=0.1 的 Non-IID 分区数据集,当良性梯度对对手已知(完全)或未知(部分)时,由 DeFL 和最先进防御方法防御模型中毒攻击的影响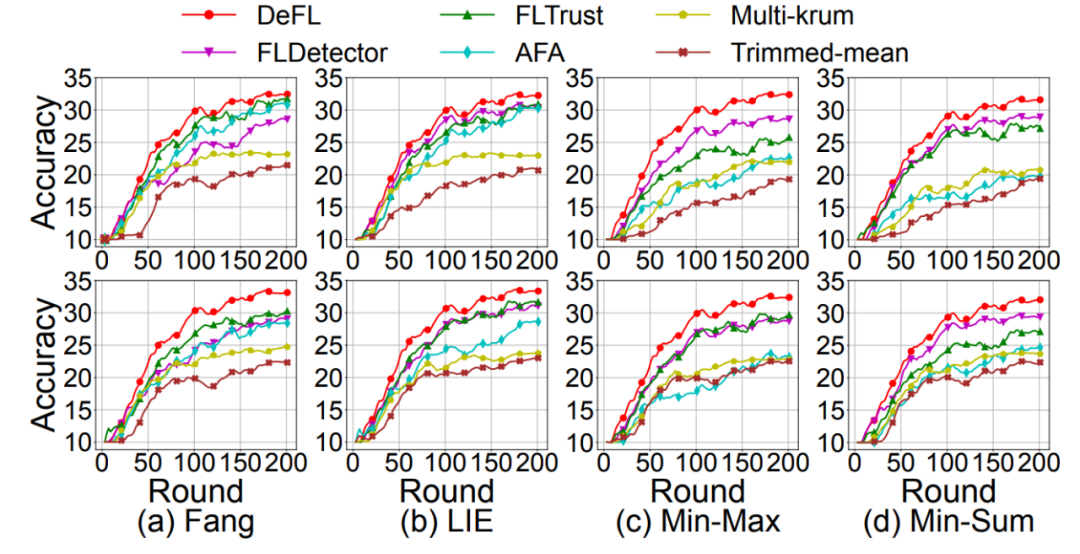
图 14. 在(上)完整和(下)部分场景下,当最先进的模型中毒攻击由 DeFL 和在 Non-IID 分区的 CIFAR-10 上使用 AlexNet 的最先进防御方法进行防御时,全局模型准确度我们进一步了解了 FGNV 中编码的信息对 CLP 检测和恶意客户端检测性能的有效性。如图 13 所示,使用 FGNV 的基于阈值的规则能够像最先进的方法一样准确地检测 CLP,然而,基于 FGNV 方法的计算效率要高得多。表 5 给出了 MOUD Vote 的真阳性率(TPR)和假阳性率(FPR),它将 FGNV 与无监督异常值检测方法相结合。TPR(FPR)是正确(错误)归类为恶意的恶意(良性)客户端的一部分。我们观察到,MOUD Vote 可以始终如一地检测到大多数恶意客户端,只有一小部分(3%)的恶意客户端没有被检测到,例如,在 Non-IID 分区的 CIFAR-10 上使用 VGG-11 的 Fang 攻击下的 TPR 为 97%。DeFL 对这些 TPR 和 FPR 是鲁棒的,因为 DeFL 不仅在 CLP 期间从聚合中删除了检测到的恶意客户端,而且还学会了估计每个客户端的聚合权重。这两种技术共同有助于提高 DeFL 防御的有效性。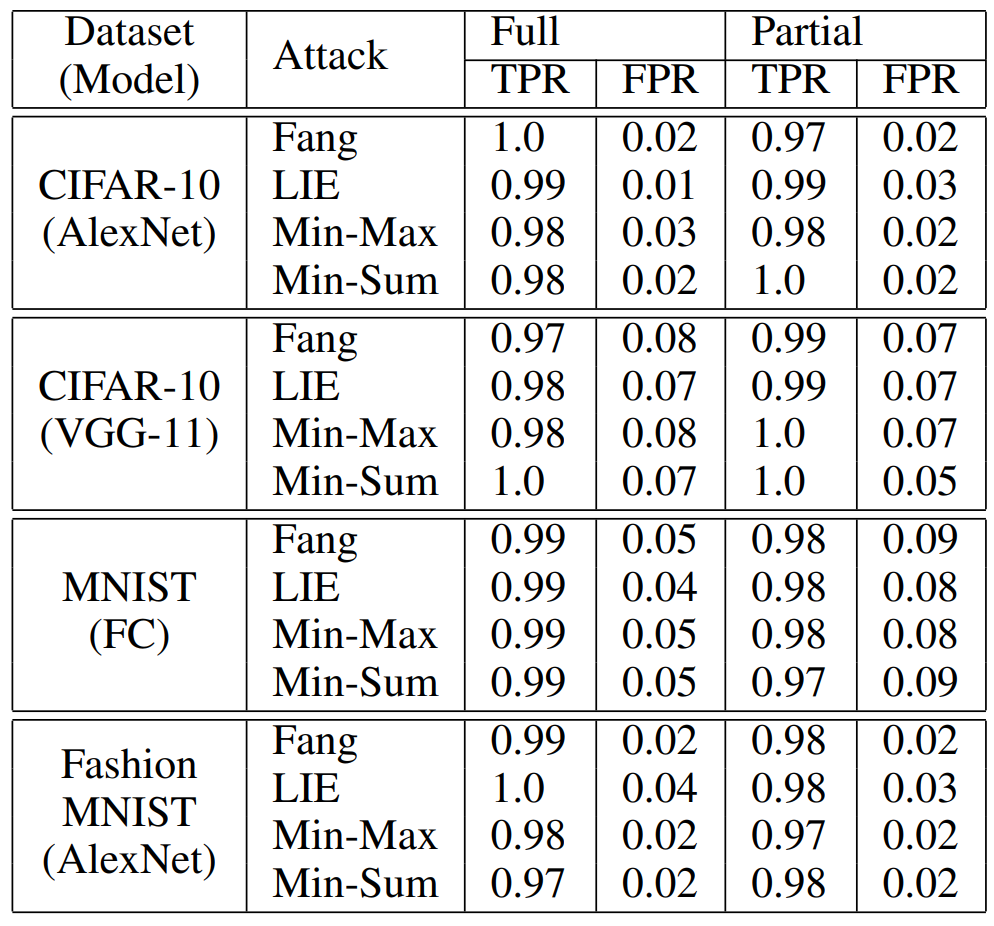
表 5. 在完整和部分场景下,使用 α=0.1 的 Non-IID 分区数据集,针对 DeFL 的模型中毒攻击的 MOUD 投票的 TPR 和 FPR实验利用 FGNV 检测 CLP,评估阈值 δ 的灵敏度。作者考虑了 {0, 0.05, 0.2, 0.35, 0.5} 的候选值。当 DeFL 使用 AlexNet 在具有不同 α 的 Non-IID 分区 CIFAR-10 上防御最先进的攻击时,全局模型准确度如图 15 所示。如作者预期,随着 δ 变大,最初训练阶段认定为 CLP 的轮次数会减少。因此,DeFL 只在较少的循环中完全删除检测到的恶意客户端。随着 δ 变大,全局模型的准确度不会显著下降,这是因为 DeFL 通过学习过程进一步增强,将聚合权重与恶意客户端相关联。为了简单起见,作者在所有实验中都设置了 δ=0.05。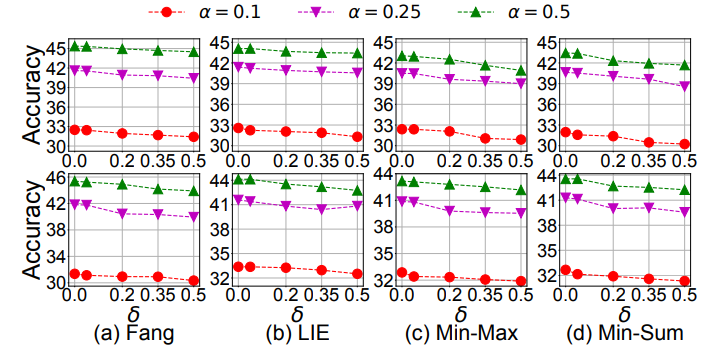
图 15. 在(上)完整和(下)部分场景下,DeFL 使用 AlexNet 对 Non-IID 分区的 CIFAR-10 进行最先进攻击时,CLP 检测阈值 δ 对全局模型准确度的影响图 16 给出了恶意客户端数量的影响,其中,作者考虑每轮恶意客户端的比例为 {12.5%、18.75%、25%、31.25%}。我们观察到全局模型的准确度只略有下降。作者分析,这是因为 DeFL 可以有效地检测具有一致的大 TPR 和小 FPR 的恶意客户端,如图 16 所示,并通过 CLP 感知来减轻其影响。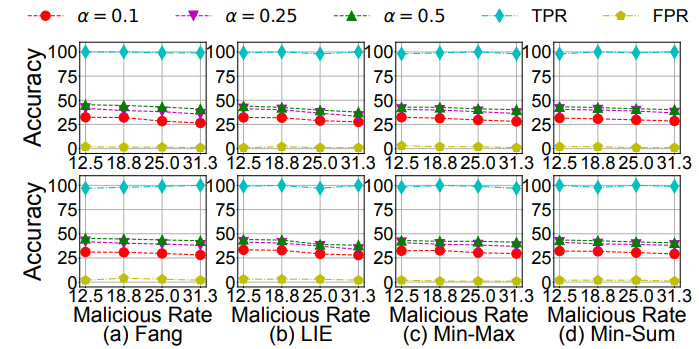
图 16. 在(上)完整和(下)部分场景下,使用 AlexNet 的恶意客户端数量对 Non-IID 分区 CIFAR-10 的影响使用参数为 α 的 Dirichlet 分布将异构数据划分为 N 个客户端。如图 17 所示,随着 Non-IID 程度的降低(随着 α 的增加),DeFL 防御最先进攻击时的全局模型准确度提高。作者分析,这是因为较低程度的 Non-IID 数据使对手更容易被检测到并从聚合中删除。我们再次观察到,在不同的 Non-IID 程度上,DeFL 始终具有大的 TPR 和小的 FPR。
图 17. 在(上)完整和(下)部分情景下,数据的 Non-IID 程度对全局模型准确度的影响我们在这篇文章中探讨了联邦学习中的关键学习期(CLP)问题。三篇论文均出自同一个团队,通过大量的实验证明了联邦学习中确实存在着关键学习期,以及通过客户端的选择,能够影响联邦学习的整体效果。此外,通过识别 CLP、检测恶意客户端,还能够引导联邦学习的过程删除恶意客户端,防御模型中毒攻击。不过,目前针对联邦学习的关键学习期问题的讨论并不多,我们分析的三篇文章也主要通过大量实验的手段对关键学习期的存在进行论证,尚缺少关于 “关键学习期” 的深度理论分析。此外,我们在连续两个专题中分别探讨了 DNN 和 FL 的关键学习期,而在其他场景下或人工智能、机器学习框架下是否也存在关键学习期?目前,仍然缺少关于关键学习期更加普适性的理论分析。最后,我们期待后续有更多的研究人员针对关键学习期问题展开更全面、更深入的分析。[1] Takao K Hensch. Critical period regulation. Annual review of neuroscience, 27:549–579, 2004.[2] Alessandro Achille, Matteo Rovere, Stefano Soatto, CRITICAL LEARNING PERIODS IN DEEP NETWORKS, ICLR 2019., https://arxiv.org/abs/1711.08856[3] Gang Yan, Hao Wang and Jian Li , Seizing Critical Learning Periods in Federated Learning , AAAI-2022,https://aaai.org/papers/08788-seizing-critical-learning-periods-in-federated-learning/[4] Gang Yan,Hao Wang,Xu Yuan,Jian Li,CriticalFL: A Critical Learning Periods Augmented Client Selection Framework for Efficient Federated Learning, KDD 2023, https://dl.acm.org/doi/10.1145/3580305.3599293 [5] DeFL: Defending Against Model Poisoning Attacks in Federated Learning via Critical Learning Periods Awareness, AAAI 2023, https://ojs.aaai.org/index.php/AAAI/article/view/26271 [6] McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; and y Arcas, B. A. 2017. Communication-Efficient Learning of Deep Networks from Decentralized Data. In Proc. of AISTATS
本文作者为Wu Jiying,工学博士,毕业于北京交通大学,曾分别于香港中文大学和香港科技大学担任助理研究员和研究助理,现从事电子政务领域信息化新技术研究工作。主要研究方向为模式识别、计算机视觉,爱好科研,希望能保持学习、不断进步。
关于机器之心全球分析师网络 Synced Global Analyst Network
机器之心全球分析师网络是由机器之心发起的全球性人工智能专业知识共享网络。在过去的四年里,已有数百名来自全球各地的 AI 领域专业学生学者、工程专家、业务专家,利用自己的学业工作之余的闲暇时间,通过线上分享、专栏解读、知识库构建、报告发布、评测及项目咨询等形式与全球 AI 社区共享自己的研究思路、工程经验及行业洞察等专业知识,并从中获得了自身的能力成长、经验积累及职业发展。
感兴趣加入机器之心全球分析师网络?点击阅读原文,提交申请。